 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing interpretability and explainability for feature selection
May 11, 2021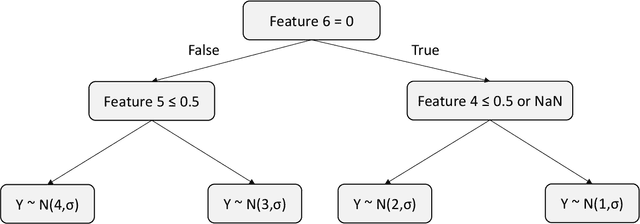

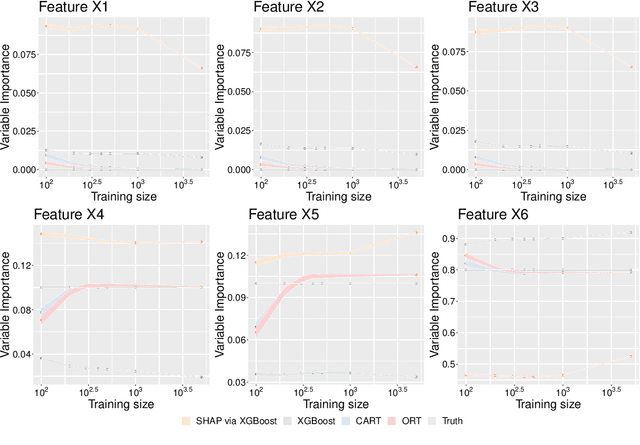

A common approach for feature selection is to examine the variable importance scores for a machine learning model, as a way to understand which features are the most relevant for making predictions. Given the significance of feature selection, it is crucial for the calculated importance scores to reflect reality. Falsely overestimating the importance of irrelevant features can lead to false discoveries, while underestimating importance of relevant features may lead us to discard important features, resulting in poor model performance. Additionally, black-box models like XGBoost provide state-of-the art predictive performance, but cannot be easily understood by humans, and thus we rely on variable importance scores or methods for explainability like SHAP to offer insight into their behavior. In this paper, we investigate the performance of variable importance as a feature selection method across various black-box and interpretable machine learning methods. We compare the ability of CART, Optimal Trees, XGBoost and SHAP to correctly identify the relevant subset of variables across a number of experiments. The results show that regardless of whether we use the native variable importance method or SHAP, XGBoost fails to clearly distinguish between relevant and irrelevant features. On the other hand, the interpretable methods are able to correctly and efficiently identify irrelevant features, and thus offer significantly better performance for feature selection.
From predictions to prescriptions: A data-driven response to COVID-19
Jun 30, 2020The COVID-19 pandemic has created unprecedented challenges worldwide. Strained healthcare providers make difficult decisions on patient triage, treatment and care management on a daily basis. Policy makers have imposed social distancing measures to slow the disease, at a steep economic price. We design analytical tools to support these decisions and combat the pandemic. Specifically, we propose a comprehensive data-driven approach to understand the clinical characteristics of COVID-19, predict its mortality, forecast its evolution, and ultimately alleviate its impact. By leveraging cohort-level clinical data, patient-level hospital data, and census-level epidemiological data, we develop an integrated four-step approach, combining descriptive, predictive and prescriptive analytics. First, we aggregate hundreds of clinical studies into the most comprehensive database on COVID-19 to paint a new macroscopic picture of the disease. Second, we build personalized calculators to predict the risk of infection and mortality as a function of demographics, symptoms, comorbidities, and lab values. Third, we develop a novel epidemiological model to project the pandemic's spread and inform social distancing policies. Fourth, we propose an optimization model to re-allocate ventilators and alleviate shortages. Our results have been used at the clinical level by several hospitals to triage patients, guide care management, plan ICU capacity, and re-distribute ventilators. At the policy level, they are currently supporting safe back-to-work policies at a major institution and equitable vaccine distribution planning at a major pharmaceutical company, and have been integrated into the US Center for Disease Control's pandemic forecast.