 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing interpretability and explainability for feature selection
May 11, 2021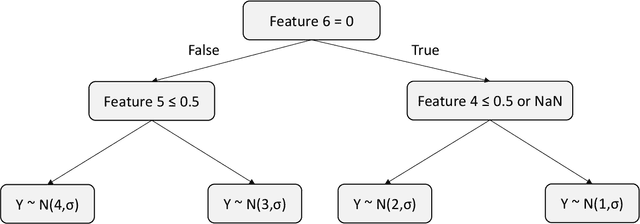

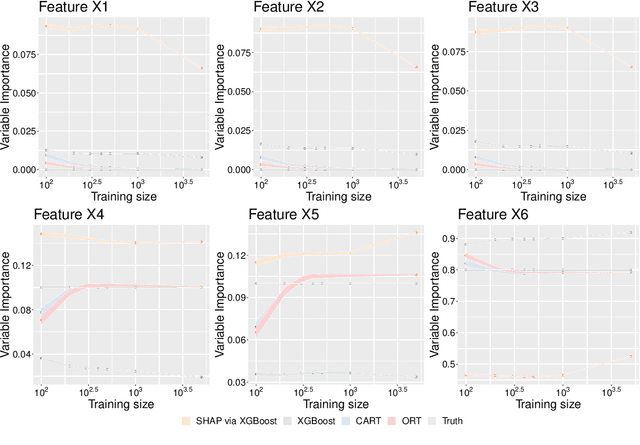

A common approach for feature selection is to examine the variable importance scores for a machine learning model, as a way to understand which features are the most relevant for making predictions. Given the significance of feature selection, it is crucial for the calculated importance scores to reflect reality. Falsely overestimating the importance of irrelevant features can lead to false discoveries, while underestimating importance of relevant features may lead us to discard important features, resulting in poor model performance. Additionally, black-box models like XGBoost provide state-of-the art predictive performance, but cannot be easily understood by humans, and thus we rely on variable importance scores or methods for explainability like SHAP to offer insight into their behavior. In this paper, we investigate the performance of variable importance as a feature selection method across various black-box and interpretable machine learning methods. We compare the ability of CART, Optimal Trees, XGBoost and SHAP to correctly identify the relevant subset of variables across a number of experiments. The results show that regardless of whether we use the native variable importance method or SHAP, XGBoost fails to clearly distinguish between relevant and irrelevant features. On the other hand, the interpretable methods are able to correctly and efficiently identify irrelevant features, and thus offer significantly better performance for feature selection.
Detecting Racial Bias in Jury Selection
Mar 22, 2021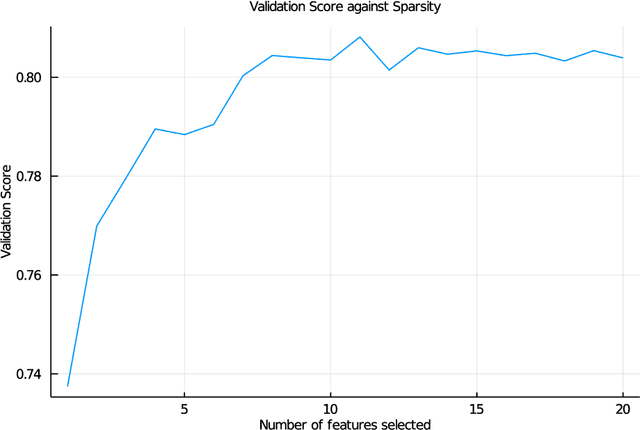
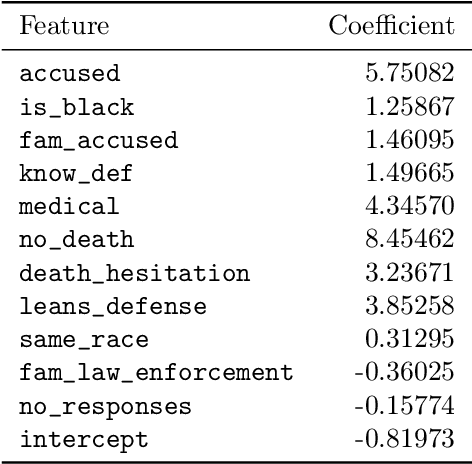
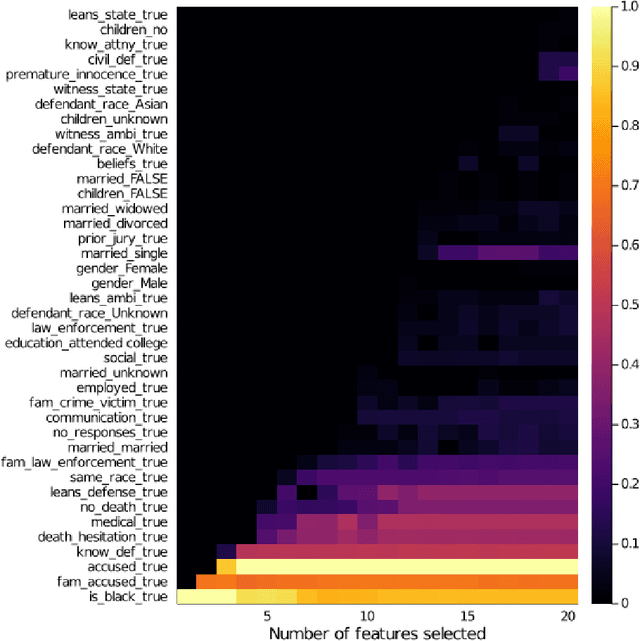
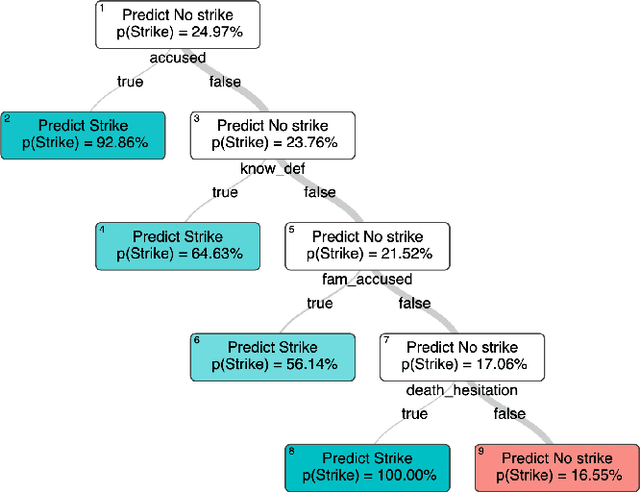
To support the 2019 U.S. Supreme Court case "Flowers v. Mississippi", APM Reports collated historical court records to assess whether the State exhibited a racial bias in striking potential jurors. This analysis used backward stepwise logistic regression to conclude that race was a significant factor, however this method for selecting relevant features is only a heuristic, and additionally cannot consider interactions between features. We apply Optimal Feature Selection to identify the globally-optimal subset of features and affirm that there is significant evidence of racial bias in the strike decisions. We also use Optimal Classification Trees to segment the juror population subgroups with similar characteristics and probability of being struck, and find that three of these subgroups exhibit significant racial disparity in strike rate, pinpointing specific areas of bias in the dataset.
Interpretable Predictive Maintenance for Hard Drives
Feb 12, 2021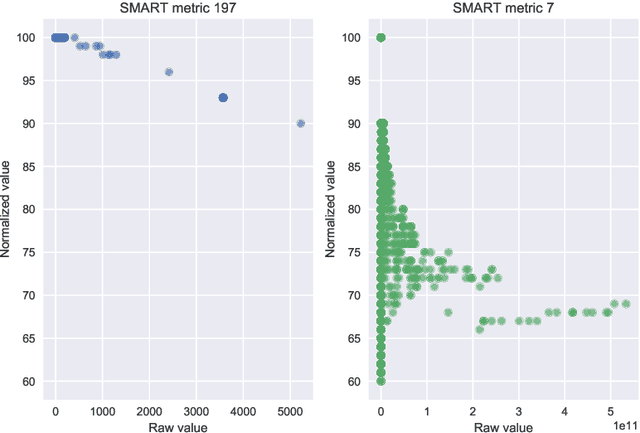
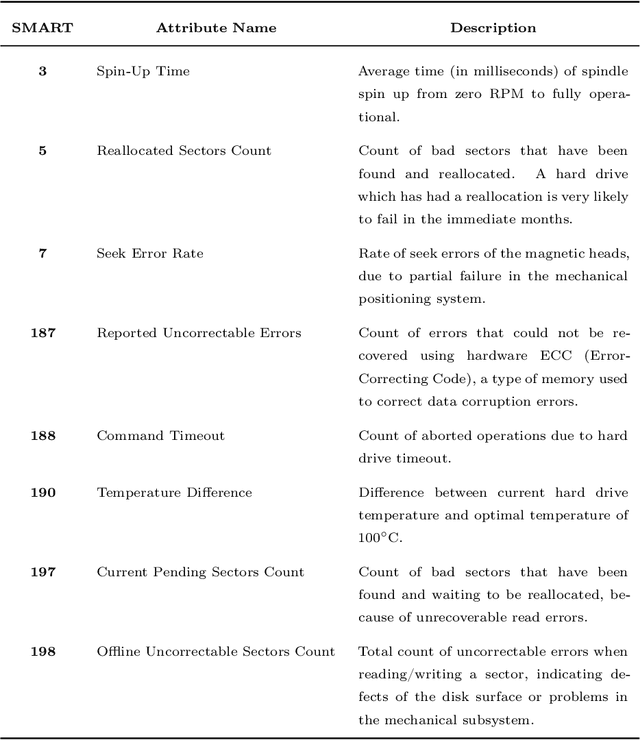
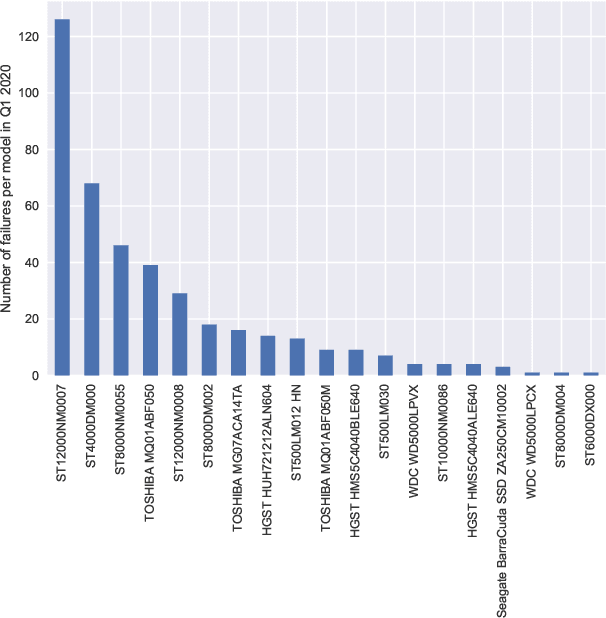
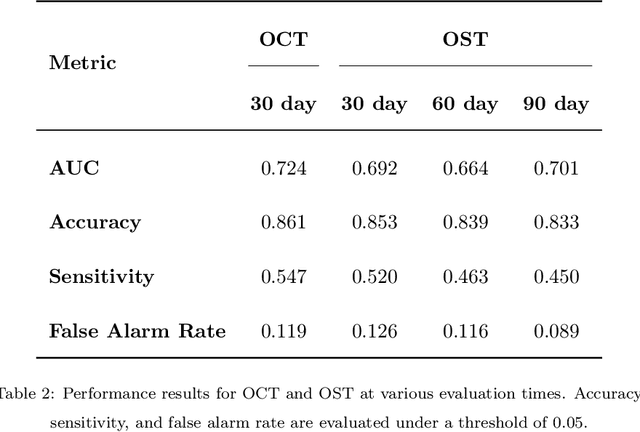
Existing machine learning approaches for data-driven predictive maintenance are usually black boxes that claim high predictive power yet cannot be understood by humans. This limits the ability of humans to use these models to derive insights and understanding of the underlying failure mechanisms, and also limits the degree of confidence that can be placed in such a system to perform well on future data. We consider the task of predicting hard drive failure in a data center using recent algorithms for interpretable machine learning. We demonstrate that these methods provide meaningful insights about short- and long-term drive health, while also maintaining high predictive performance. We also show that these analyses still deliver useful insights even when limited historical data is available, enabling their use in situations where data collection has only recently begun.
Optimal Survival Trees
Dec 08, 2020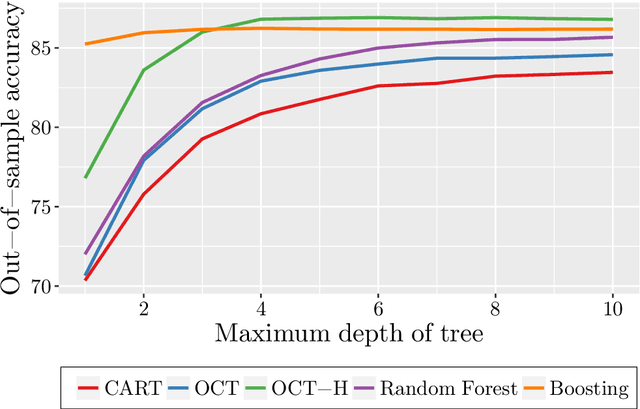
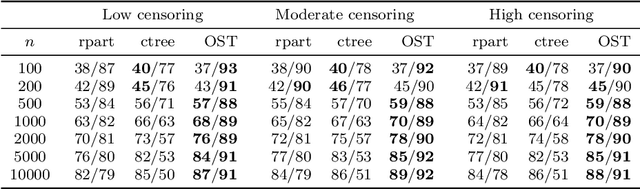
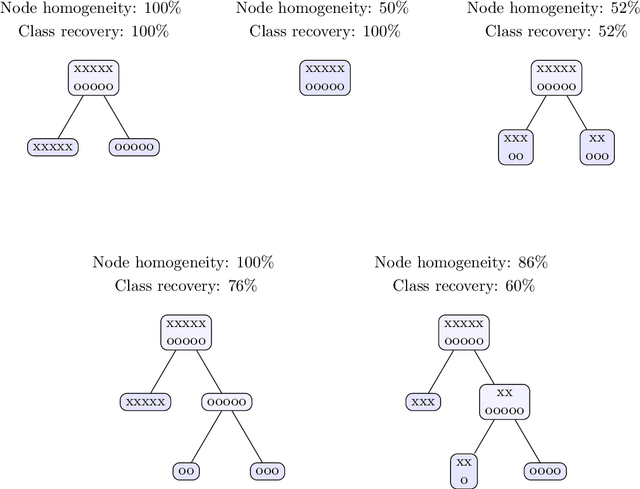
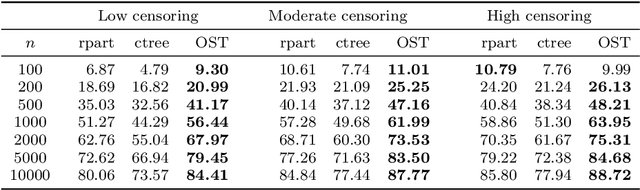
Tree-based models are increasingly popular due to their ability to identify complex relationships that are beyond the scope of parametric models. Survival tree methods adapt these models to allow for the analysis of censored outcomes, which often appear in medical data. We present a new Optimal Survival Trees algorithm that leverages mixed-integer optimization (MIO) and local search techniques to generate globally optimized survival tree models. We demonstrate that the OST algorithm improves on the accuracy of existing survival tree methods, particularly in large datasets.
Optimal Policy Trees
Dec 03, 2020


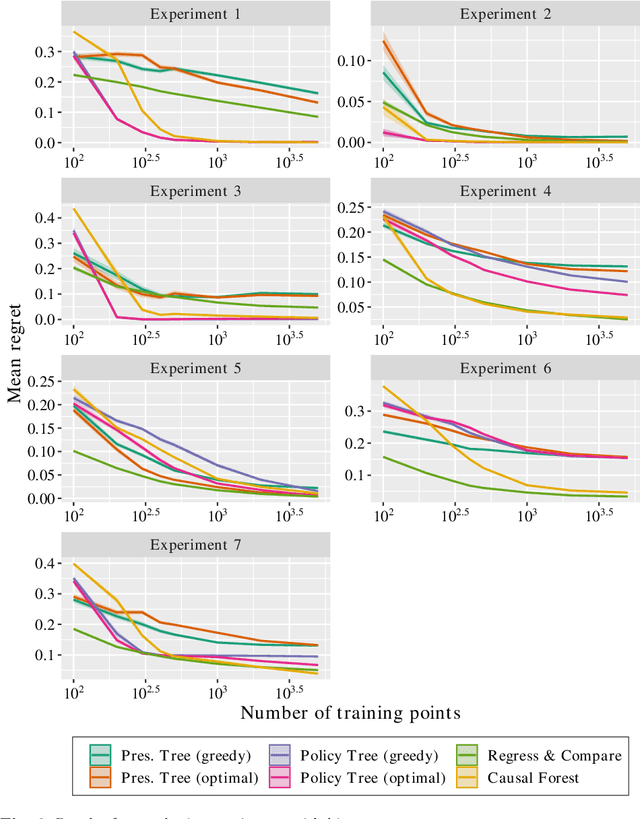
We propose an approach for learning optimal tree-based prescription policies directly from data, combining methods for counterfactual estimation from the causal inference literature with recent advances in training globally-optimal decision trees. The resulting method, Optimal Policy Trees, yields interpretable prescription policies, is highly scalable, and handles both discrete and continuous treatments. We conduct extensive experiments on both synthetic and real-world datasets and demonstrate that these trees offer best-in-class performance across a wide variety of problems.