 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML Compass: Navigating Capability, Cost, and Compliance Trade-offs in AI Model Deployment
Dec 29, 2025We study how organizations should select among competing AI models when user utility, deployment costs, and compliance requirements jointly matter. Widely used capability leaderboards do not translate directly into deployment decisions, creating a capability -- deployment gap; to bridge it, we take a systems-level view in which model choice is tied to application outcomes, operating constraints, and a capability-cost frontier. We develop ML Compass, a framework that treats model selection as constrained optimization over this frontier. On the theory side, we characterize optimal model configurations under a parametric frontier and show a three-regime structure in optimal internal measures: some dimensions are pinned at compliance minima, some saturate at maximum levels, and the remainder take interior values governed by frontier curvature. We derive comparative statics that quantify how budget changes, regulatory tightening, and technological progress propagate across capability dimensions and costs. On the implementation side, we propose a pipeline that (i) extracts low-dimensional internal measures from heterogeneous model descriptors, (ii) estimates an empirical frontier from capability and cost data, (iii) learns a user- or task-specific utility function from interaction outcome data, and (iv) uses these components to target capability-cost profiles and recommend models. We validate ML Compass with two case studies: a general-purpose conversational setting using the PRISM Alignment dataset and a healthcare setting using a custom dataset we build using HealthBench. In both environments, our framework produces recommendations -- and deployment-aware leaderboards based on predicted deployment value under constraints -- that can differ materially from capability-only rankings, and clarifies how trade-offs between capability, cost, and safety shape optimal model choice.
Conformalized Decision Risk Assessment
May 19, 2025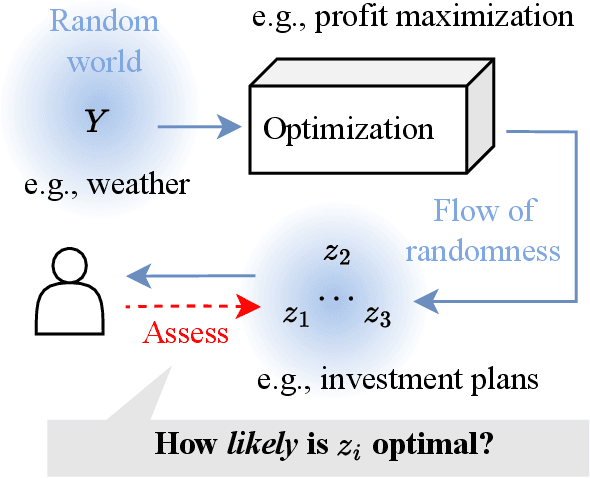



High-stakes decisions in domains such as healthcare, energy, and public policy are often made by human experts using domain knowledge and heuristics, yet are increasingly supported by predictive and optimization-based tools. A dominant approach in operations research is the predict-then-optimize paradigm, where a predictive model estimates uncertain inputs, and an optimization model recommends a decision. However, this approach often lacks interpretability and can fail under distributional uncertainty -- particularly when the outcome distribution is multi-modal or complex -- leading to brittle or misleading decisions. In this paper, we introduce CREDO, a novel framework that quantifies, for any candidate decision, a distribution-free upper bound on the probability that the decision is suboptimal. By combining inverse optimization geometry with conformal prediction and generative modeling, CREDO produces risk certificates that are both statistically rigorous and practically interpretable. This framework enables human decision-makers to audit and validate their own decisions under uncertainty, bridging the gap between algorithmic tools and real-world judgment.
Local Causal Discovery for Structural Evidence of Direct Discrimination
May 23, 2024Fairness is a critical objective in policy design and algorithmic decision-making. Identifying the causal pathways of unfairness requires knowledge of the underlying structural causal model, which may be incomplete or unavailable. This limits the practicality of causal fairness analysis in complex or low-knowledge domains. To mitigate this practicality gap, we advocate for developing efficient causal discovery methods for fairness applications. To this end, we introduce local discovery for direct discrimination (LD3): a polynomial-time algorithm that recovers structural evidence of direct discrimination. LD3 performs a linear number of conditional independence tests with respect to variable set size. Moreover, we propose a graphical criterion for identifying the weighted controlled direct effect (CDE), a qualitative measure of direct discrimination. We prove that this criterion is satisfied by the knowledge returned by LD3, increasing the accessibility of the weighted CDE as a causal fairness measure. Taking liver transplant allocation as a case study, we highlight the potential impact of LD3 for modeling fairness in complex decision systems. Results on real-world data demonstrate more plausible causal relations than baselines, which took 197x to 5870x longer to execute.
Distribution-free risk assessment of regression-based machine learning algorithms
Oct 05, 2023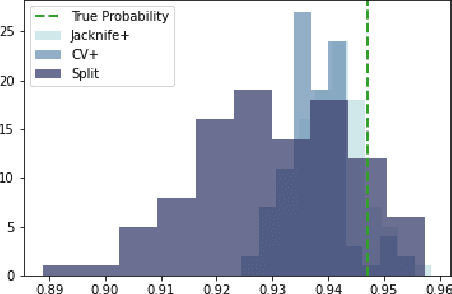
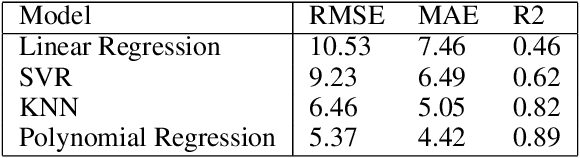
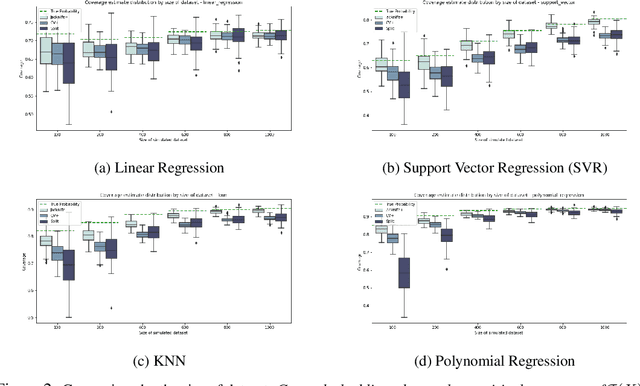
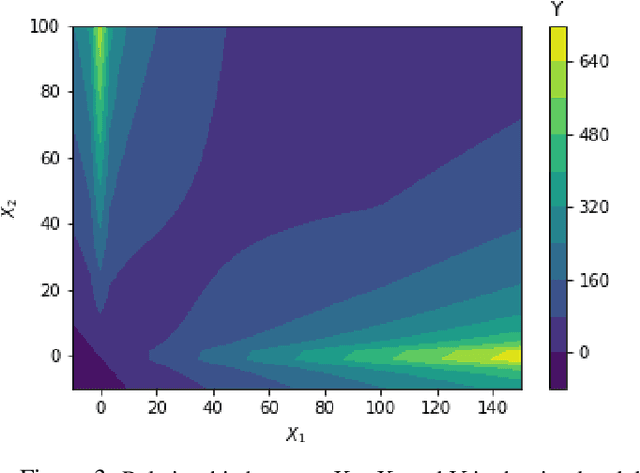
Machine learning algorithms have grown in sophistication over the years and are increasingly deployed for real-life applications. However, when using machine learning techniques in practical settings, particularly in high-risk applications such as medicine and engineering, obtaining the failure probability of the predictive model is critical. We refer to this problem as the risk-assessment task. We focus on regression algorithms and the risk-assessment task of computing the probability of the true label lying inside an interval defined around the model's prediction. We solve the risk-assessment problem using the conformal prediction approach, which provides prediction intervals that are guaranteed to contain the true label with a given probability. Using this coverage property, we prove that our approximated failure probability is conservative in the sense that it is not lower than the true failure probability of the ML algorithm. We conduct extensive experiments to empirically study the accuracy of the proposed method for problems with and without covariate shift. Our analysis focuses on different modeling regimes, dataset sizes, and conformal prediction methodologies.
Pricing Algorithmic Insurance
Jun 01, 2021
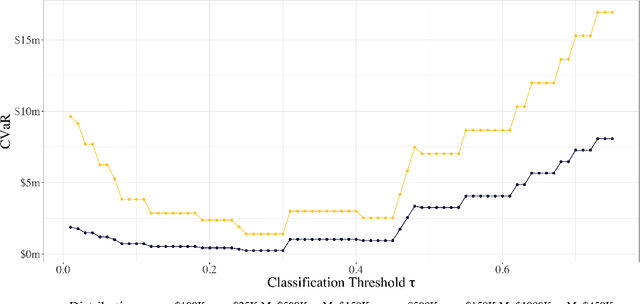
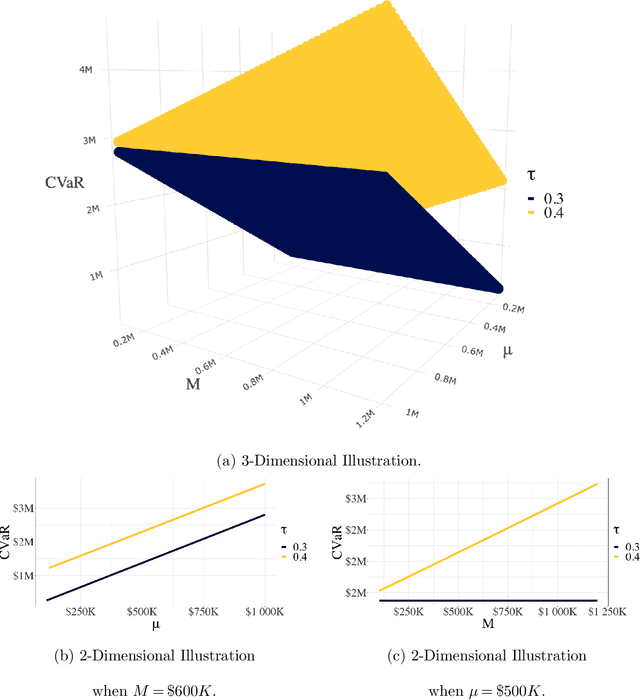
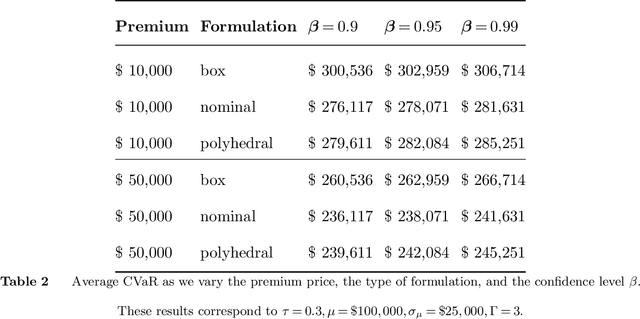
As machine learning algorithms start to get integrated into the decision-making process of companies and organizations, insurance products will be developed to protect their owners from risk. We introduce the concept of algorithmic insurance and present a quantitative framework to enable the pricing of the derived insurance contracts. We propose an optimization formulation to estimate the risk exposure and price for a binary classification model. Our approach outlines how properties of the model, such as accuracy, interpretability and generalizability, can influence the insurance contract evaluation. To showcase a practical implementation of the proposed framework, we present a case study of medical malpractice in the context of breast cancer detection. Our analysis focuses on measuring the effect of the model parameters on the expected financial loss and identifying the aspects of algorithmic performance that predominantly affect the price of the contract.
Optimal Survival Trees
Dec 08, 2020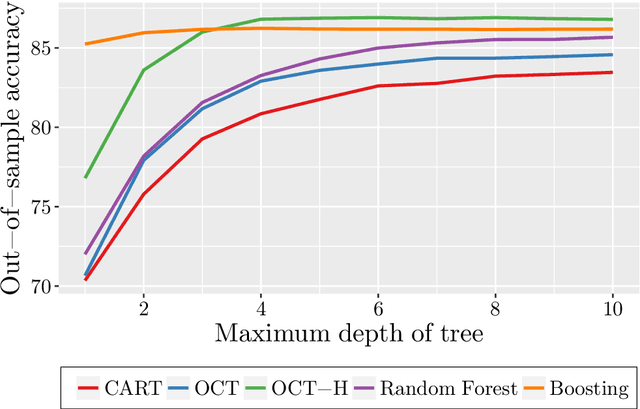
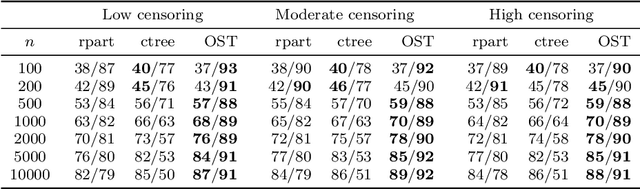
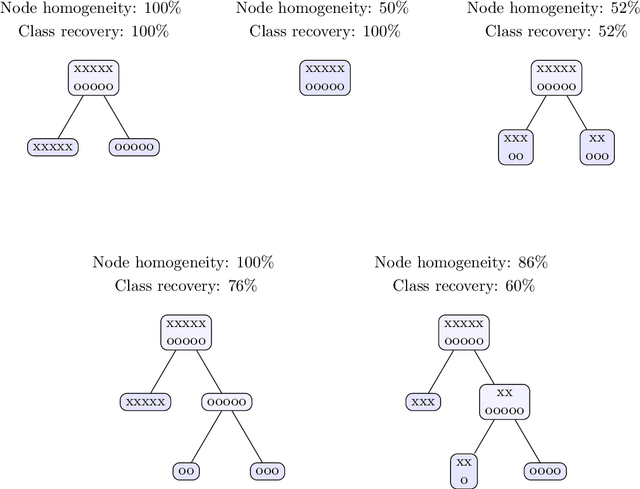
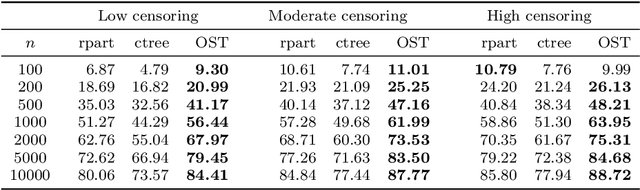
Tree-based models are increasingly popular due to their ability to identify complex relationships that are beyond the scope of parametric models. Survival tree methods adapt these models to allow for the analysis of censored outcomes, which often appear in medical data. We present a new Optimal Survival Trees algorithm that leverages mixed-integer optimization (MIO) and local search techniques to generate globally optimized survival tree models. We demonstrate that the OST algorithm improves on the accuracy of existing survival tree methods, particularly in large datasets.
From predictions to prescriptions: A data-driven response to COVID-19
Jun 30, 2020The COVID-19 pandemic has created unprecedented challenges worldwide. Strained healthcare providers make difficult decisions on patient triage, treatment and care management on a daily basis. Policy makers have imposed social distancing measures to slow the disease, at a steep economic price. We design analytical tools to support these decisions and combat the pandemic. Specifically, we propose a comprehensive data-driven approach to understand the clinical characteristics of COVID-19, predict its mortality, forecast its evolution, and ultimately alleviate its impact. By leveraging cohort-level clinical data, patient-level hospital data, and census-level epidemiological data, we develop an integrated four-step approach, combining descriptive, predictive and prescriptive analytics. First, we aggregate hundreds of clinical studies into the most comprehensive database on COVID-19 to paint a new macroscopic picture of the disease. Second, we build personalized calculators to predict the risk of infection and mortality as a function of demographics, symptoms, comorbidities, and lab values. Third, we develop a novel epidemiological model to project the pandemic's spread and inform social distancing policies. Fourth, we propose an optimization model to re-allocate ventilators and alleviate shortages. Our results have been used at the clinical level by several hospitals to triage patients, guide care management, plan ICU capacity, and re-distribute ventilators. At the policy level, they are currently supporting safe back-to-work policies at a major institution and equitable vaccine distribution planning at a major pharmaceutical company, and have been integrated into the US Center for Disease Control's pandemic forecast.
Personalized Treatment for Coronary Artery Disease Patients: A Machine Learning Approach
Oct 18, 2019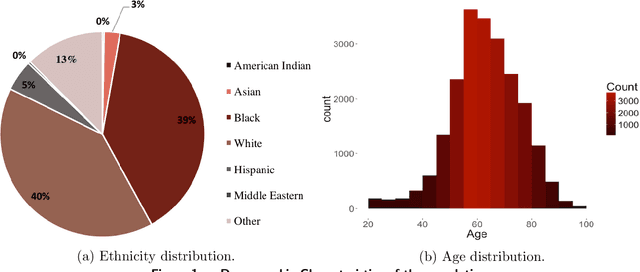

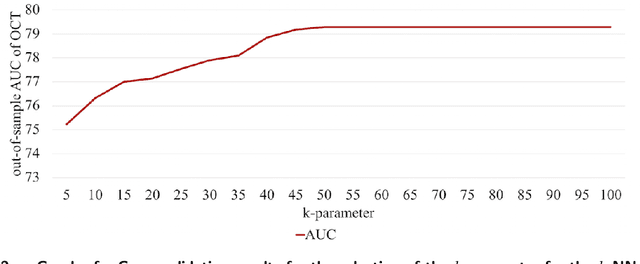
Current clinical practice guidelines for managing Coronary Artery Disease (CAD) account for general cardiovascular risk factors. However, they do not present a framework that considers personalized patient-specific characteristics. Using the electronic health records of 21,460 patients, we created data-driven models for personalized CAD management that significantly improve health outcomes relative to the standard of care. We develop binary classifiers to detect whether a patient will experience an adverse event due to CAD within a 10-year time frame. Combining the patients' medical history and clinical examination results, we achieve 81.5% AUC. For each treatment, we also create a series of regression models that are based on different supervised machine learning algorithms. We are able to estimate with average R squared = 0.801 the time from diagnosis to a potential adverse event (TAE) and gain accurate approximations of the counterfactual treatment effects. Leveraging combinations of these models, we present ML4CAD, a novel personalized prescriptive algorithm. Considering the recommendations of multiple predictive models at once, ML4CAD identifies for every patient the therapy with the best expected outcome using a voting mechanism. We evaluate its performance by measuring the prescription effectiveness and robustness under alternative ground truths. We show that our methodology improves the expected TAE upon the current baseline by 24.11%, increasing it from 4.56 to 5.66 years. The algorithm performs particularly well for the male (24.3% improvement) and Hispanic (58.41% improvement) subpopulations. Finally, we create an interactive interface, providing physicians with an intuitive, accurate, readily implementable, and effective tool.
Interpretable Clustering via Optimal Trees
Dec 03, 2018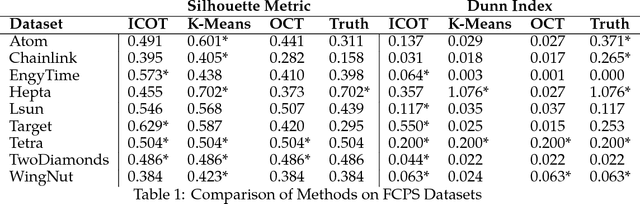
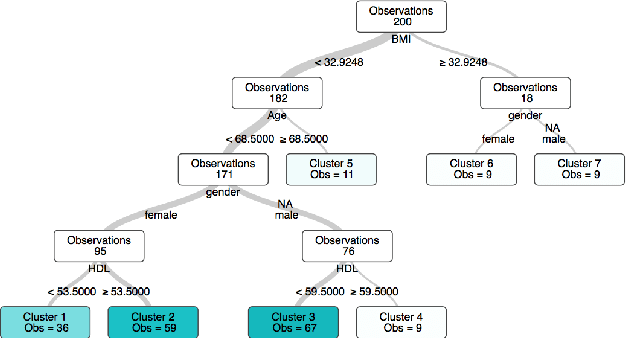
State-of-the-art clustering algorithms use heuristics to partition the feature space and provide little insight into the rationale for cluster membership, limiting their interpretability. In healthcare applications, the latter poses a barrier to the adoption of these methods since medical researchers are required to provide detailed explanations of their decisions in order to gain patient trust and limit liability. We present a new unsupervised learning algorithm that leverages Mixed Integer Optimization techniques to generate interpretable tree-based clustering models. Utilizing the flexible framework of Optimal Trees, our method approximates the globally optimal solution leading to high quality partitions of the feature space. Our algorithm, can incorporate various internal validation metrics, naturally determines the optimal number of clusters, and is able to account for mixed numeric and categorical data. It achieves comparable or superior performance on both synthetic and real world datasets when compared to K-Means while offering significantly higher interpretability.
Imputation of Clinical Covariates in Time Series
Dec 02, 2018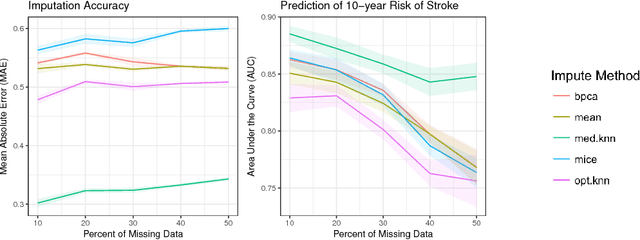
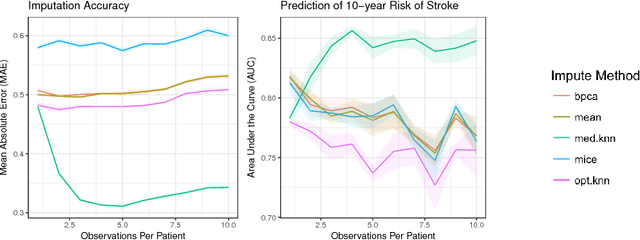
Missing data is a common problem in real-world settings and particularly relevant in healthcare applications where researchers use Electronic Health Records (EHR) and results of observational studies to apply analytics methods. This issue becomes even more prominent for longitudinal data sets, where multiple instances of the same individual correspond to different observations in time. Standard imputation methods do not take into account patient specific information incorporated in multivariate panel data. We introduce the novel imputation algorithm MedImpute that addresses this problem, extending the flexible framework of OptImpute suggested by Bertsimas et al. (2018). Our algorithm provides imputations for data sets with missing continuous and categorical features, and we present the formulation and implement scalable first-order methods for a $K$-NN model. We test the performance of our algorithm on longitudinal data from the Framingham Heart Study when data are missing completely at random (MCAR). We demonstrate that MedImpute leads to significant improvements in both imputation accuracy and downstream model AUC compared to state-of-the-art methods.