 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM or Human? Perceptions of Trust and Information Quality in Research Summaries
Jan 22, 2026Large Language Models (LLMs) are increasingly used to generate and edit scientific abstracts, yet their integration into academic writing raises questions about trust, quality, and disclosure. Despite growing adoption, little is known about how readers perceive LLM-generated summaries and how these perceptions influence evaluations of scientific work. This paper presents a mixed-methods survey experiment investigating whether readers with ML expertise can distinguish between human- and LLM-generated abstracts, how actual and perceived LLM involvement affects judgments of quality and trustworthiness, and what orientations readers adopt toward AI-assisted writing. Our findings show that participants struggle to reliably identify LLM-generated content, yet their beliefs about LLM involvement significantly shape their evaluations. Notably, abstracts edited by LLMs are rated more favorably than those written solely by humans or LLMs. We also identify three distinct reader orientations toward LLM-assisted writing, offering insights into evolving norms and informing policy around disclosure and acceptable use in scientific communication.
Users Mispredict Their Own Preferences for AI Writing Assistance
Jan 08, 2026Proactive AI writing assistants need to predict when users want drafting help, yet we lack empirical understanding of what drives preferences. Through a factorial vignette study with 50 participants making 750 pairwise comparisons, we find compositional effort dominates decisions ($ρ= 0.597$) while urgency shows no predictive power ($ρ\approx 0$). More critically, users exhibit a striking perception-behavior gap: they rank urgency first in self-reports despite it being the weakest behavioral driver, representing a complete preference inversion. This misalignment has measurable consequences. Systems designed from users' stated preferences achieve only 57.7\% accuracy, underperforming even naive baselines, while systems using behavioral patterns reach significantly higher 61.3\% ($p < 0.05$). These findings demonstrate that relying on user introspection for system design actively misleads optimization, with direct implications for proactive natural language generation (NLG) systems.
Improving LLM Group Fairness on Tabular Data via In-Context Learning
Dec 05, 2024Large language models (LLMs) have been shown to be effective on tabular prediction tasks in the low-data regime, leveraging their internal knowledge and ability to learn from instructions and examples. However, LLMs can fail to generate predictions that satisfy group fairness, that is, produce equitable outcomes across groups. Critically, conventional debiasing approaches for natural language tasks do not directly translate to mitigating group unfairness in tabular settings. In this work, we systematically investigate four empirical approaches to improve group fairness of LLM predictions on tabular datasets, including fair prompt optimization, soft prompt tuning, strategic selection of few-shot examples, and self-refining predictions via chain-of-thought reasoning. Through experiments on four tabular datasets using both open-source and proprietary LLMs, we show the effectiveness of these methods in enhancing demographic parity while maintaining high overall performance. Our analysis provides actionable insights for practitioners in selecting the most suitable approach based on their specific requirements and constraints.
Precise Model Benchmarking with Only a Few Observations
Oct 07, 2024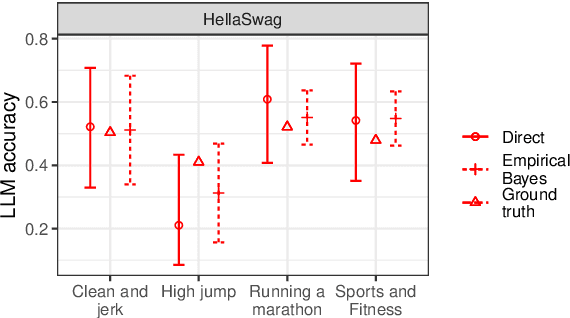
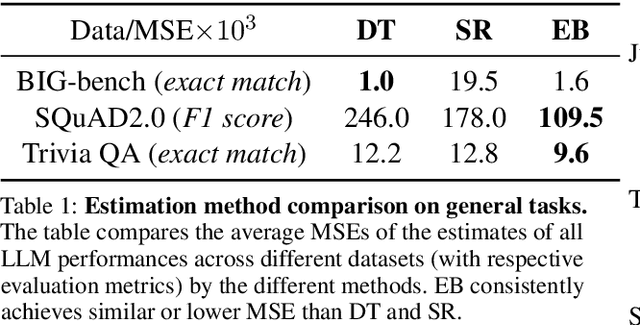
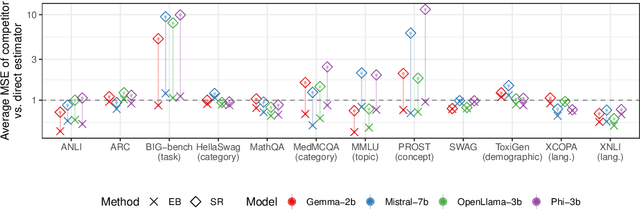
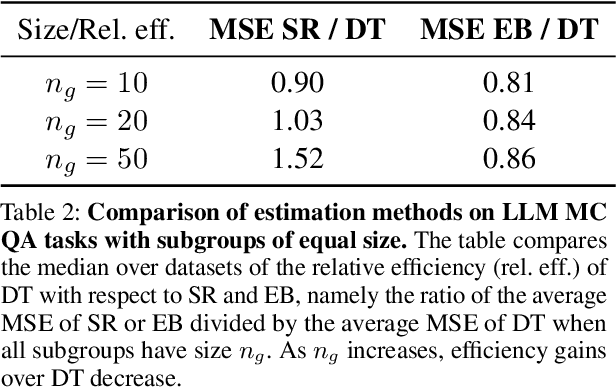
How can we precisely estimate a large language model's (LLM) accuracy on questions belonging to a specific topic within a larger question-answering dataset? The standard direct estimator, which averages the model's accuracy on the questions in each subgroup, may exhibit high variance for subgroups (topics) with small sample sizes. Synthetic regression modeling, which leverages the model's accuracy on questions about other topics, may yield biased estimates that are too unreliable for large subgroups. We prescribe a simple yet effective solution: an empirical Bayes (EB) estimator that balances direct and regression estimates for each subgroup separately, improving the precision of subgroup-level estimates of model performance. Our experiments on multiple datasets show that this approach consistently provides more precise estimates of the LLM performance compared to the direct and regression approaches, achieving substantial reductions in the mean squared error. Confidence intervals for EB estimates also have near-nominal coverage and are narrower compared to those for the direct estimator. Additional experiments on tabular and vision data validate the benefits of this EB approach.
Local Causal Discovery for Structural Evidence of Direct Discrimination
May 23, 2024Fairness is a critical objective in policy design and algorithmic decision-making. Identifying the causal pathways of unfairness requires knowledge of the underlying structural causal model, which may be incomplete or unavailable. This limits the practicality of causal fairness analysis in complex or low-knowledge domains. To mitigate this practicality gap, we advocate for developing efficient causal discovery methods for fairness applications. To this end, we introduce local discovery for direct discrimination (LD3): a polynomial-time algorithm that recovers structural evidence of direct discrimination. LD3 performs a linear number of conditional independence tests with respect to variable set size. Moreover, we propose a graphical criterion for identifying the weighted controlled direct effect (CDE), a qualitative measure of direct discrimination. We prove that this criterion is satisfied by the knowledge returned by LD3, increasing the accessibility of the weighted CDE as a causal fairness measure. Taking liver transplant allocation as a case study, we highlight the potential impact of LD3 for modeling fairness in complex decision systems. Results on real-world data demonstrate more plausible causal relations than baselines, which took 197x to 5870x longer to execute.
The Impact of Differential Feature Under-reporting on Algorithmic Fairness
Jan 16, 2024



Predictive risk models in the public sector are commonly developed using administrative data that is more complete for subpopulations that more greatly rely on public services. In the United States, for instance, information on health care utilization is routinely available to government agencies for individuals supported by Medicaid and Medicare, but not for the privately insured. Critiques of public sector algorithms have identified such differential feature under-reporting as a driver of disparities in algorithmic decision-making. Yet this form of data bias remains understudied from a technical viewpoint. While prior work has examined the fairness impacts of additive feature noise and features that are clearly marked as missing, the setting of data missingness absent indicators (i.e. differential feature under-reporting) has been lacking in research attention. In this work, we present an analytically tractable model of differential feature under-reporting which we then use to characterize the impact of this kind of data bias on algorithmic fairness. We demonstrate how standard missing data methods typically fail to mitigate bias in this setting, and propose a new set of methods specifically tailored to differential feature under-reporting. Our results show that, in real world data settings, under-reporting typically leads to increasing disparities. The proposed solution methods show success in mitigating increases in unfairness.
A Sandbox Tool to Bias-Test Fairness Algorithms
Apr 21, 2022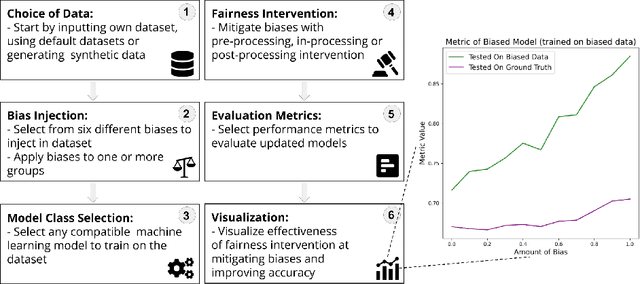
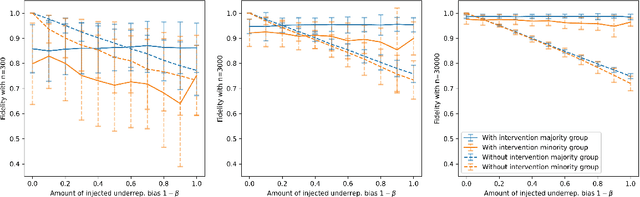
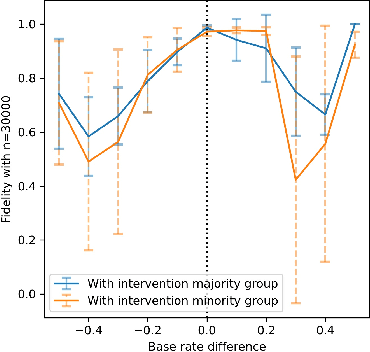
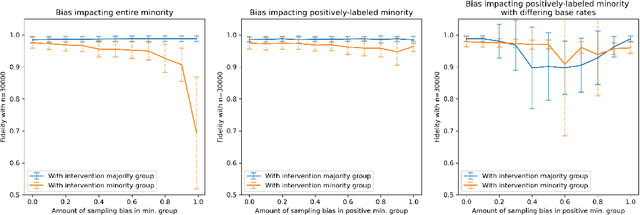
Motivated by the growing importance of reducing unfairness in ML predictions, Fair-ML researchers have presented an extensive suite of algorithmic "fairness-enhancing" remedies. Most existing algorithms, however, are agnostic to the sources of the observed unfairness. As a result, the literature currently lacks guiding frameworks to specify conditions under which each algorithmic intervention can potentially alleviate the underpinning cause of unfairness. To close this gap, we scrutinize the underlying biases (e.g., in the training data or design choices) that cause observational unfairness. We present a bias-injection sandbox tool to investigate fairness consequences of various biases and assess the effectiveness of algorithmic remedies in the presence of specific types of bias. We call this process the bias(stress)-testing of algorithmic interventions. Unlike existing toolkits, ours provides a controlled environment to counterfactually inject biases in the ML pipeline. This stylized setup offers the distinct capability of testing fairness interventions beyond observational data and against an unbiased benchmark. In particular, we can test whether a given remedy can alleviate the injected bias by comparing the predictions resulting after the intervention in the biased setting with true labels in the unbiased regime -- that is, before any bias injection. We illustrate the utility of our toolkit via a proof-of-concept case study on synthetic data. Our empirical analysis showcases the type of insights that can be obtained through our simulations.
The effect of differential victim crime reporting on predictive policing systems
Feb 04, 2021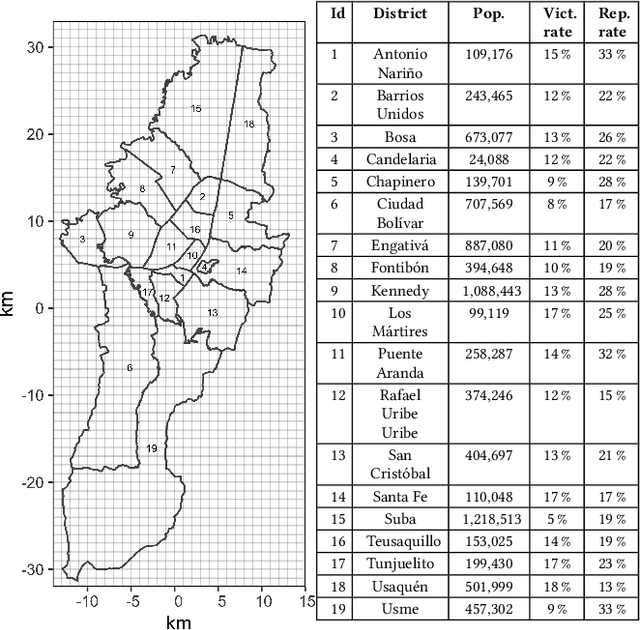
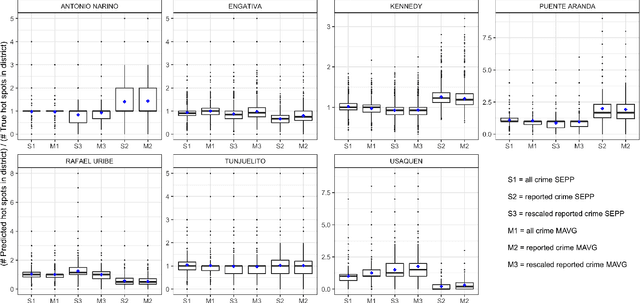
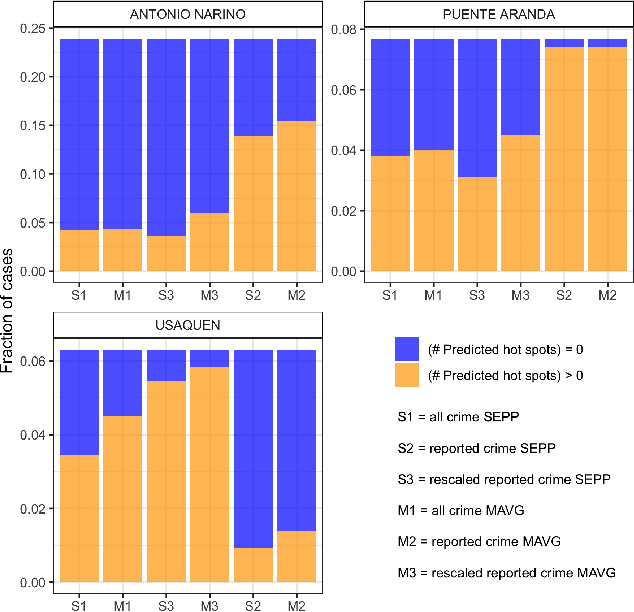

Police departments around the world have been experimenting with forms of place-based data-driven proactive policing for over two decades. Modern incarnations of such systems are commonly known as hot spot predictive policing. These systems predict where future crime is likely to concentrate such that police can allocate patrols to these areas and deter crime before it occurs. Previous research on fairness in predictive policing has concentrated on the feedback loops which occur when models are trained on discovered crime data, but has limited implications for models trained on victim crime reporting data. We demonstrate how differential victim crime reporting rates across geographical areas can lead to outcome disparities in common crime hot spot prediction models. Our analysis is based on a simulation patterned after district-level victimization and crime reporting survey data for Bogot\'a, Colombia. Our results suggest that differential crime reporting rates can lead to a displacement of predicted hotspots from high crime but low reporting areas to high or medium crime and high reporting areas. This may lead to misallocations both in the form of over-policing and under-policing.
Sample Complexity Bounds for Recurrent Neural Networks with Application to Combinatorial Graph Problems
Jan 29, 2019
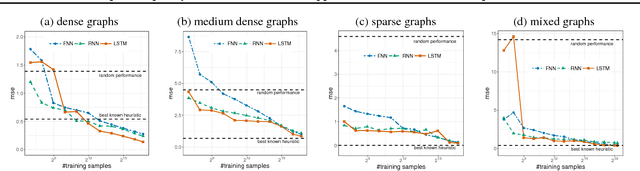
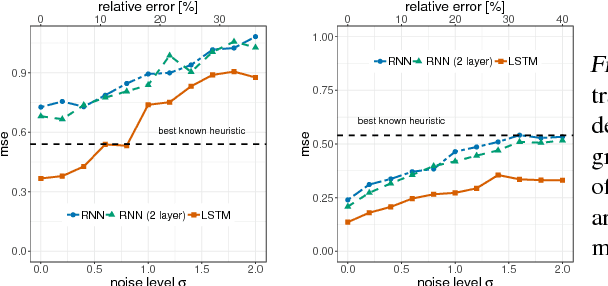
Learning to predict solutions to real-valued combinatorial graph problems promises efficient approximations. As demonstrated based on the NP-hard edge clique cover number, recurrent neural networks (RNNs) are particularly suited for this task and can even outperform state-of-the-art heuristics. However, the theoretical framework for estimating real-valued RNNs is understood only poorly. As our primary contribution, this is the first work that upper bounds the sample complexity for learning real-valued RNNs. While such derivations have been made earlier for feed-forward and convolutional neural networks, our work presents the first such attempt for recurrent neural networks. Given a single-layer RNN with $a$ rectified linear units and input of length $b$, we show that a population prediction error of $\varepsilon$ can be realized with at most $\tilde{\mathcal{O}}(a^4b/\varepsilon^2)$ samples. We further derive comparable results for multi-layer RNNs. Accordingly, a size-adaptive RNN fed with graphs of at most $n$ vertices can be learned in $\tilde{\mathcal{O}}(n^6/\varepsilon^2)$, i.e., with only a polynomial number of samples. For combinatorial graph problems, this provides a theoretical foundation that renders RNNs competitive.