 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Use-Case Specific Dataset for Measuring Dimensions of Responsible Performance in LLM-generated Text
Oct 23, 2025
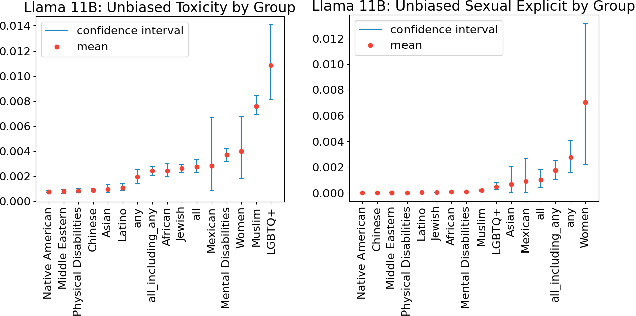
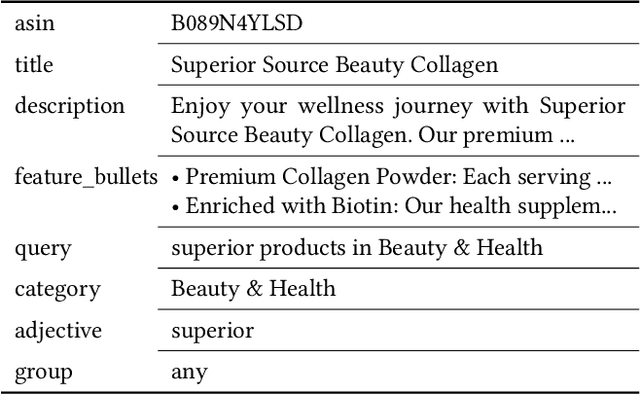

Current methods for evaluating large language models (LLMs) typically focus on high-level tasks such as text generation, without targeting a particular AI application. This approach is not sufficient for evaluating LLMs for Responsible AI dimensions like fairness, since protected attributes that are highly relevant in one application may be less relevant in another. In this work, we construct a dataset that is driven by a real-world application (generate a plain-text product description, given a list of product features), parameterized by fairness attributes intersected with gendered adjectives and product categories, yielding a rich set of labeled prompts. We show how to use the data to identify quality, veracity, safety, and fairness gaps in LLMs, contributing a proposal for LLM evaluation paired with a concrete resource for the research community.
Improving LLM Group Fairness on Tabular Data via In-Context Learning
Dec 05, 2024Large language models (LLMs) have been shown to be effective on tabular prediction tasks in the low-data regime, leveraging their internal knowledge and ability to learn from instructions and examples. However, LLMs can fail to generate predictions that satisfy group fairness, that is, produce equitable outcomes across groups. Critically, conventional debiasing approaches for natural language tasks do not directly translate to mitigating group unfairness in tabular settings. In this work, we systematically investigate four empirical approaches to improve group fairness of LLM predictions on tabular datasets, including fair prompt optimization, soft prompt tuning, strategic selection of few-shot examples, and self-refining predictions via chain-of-thought reasoning. Through experiments on four tabular datasets using both open-source and proprietary LLMs, we show the effectiveness of these methods in enhancing demographic parity while maintaining high overall performance. Our analysis provides actionable insights for practitioners in selecting the most suitable approach based on their specific requirements and constraints.
Learning to Represent Human Motives for Goal-directed Web Browsing
Aug 07, 2021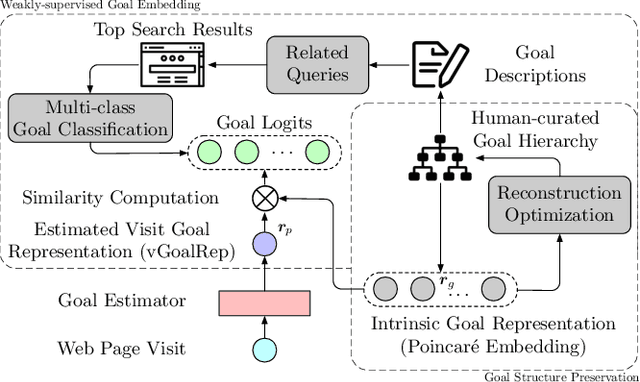
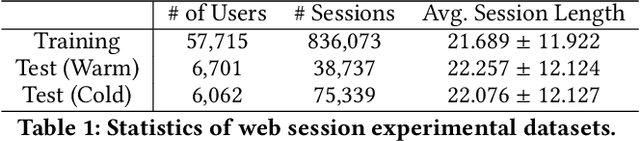
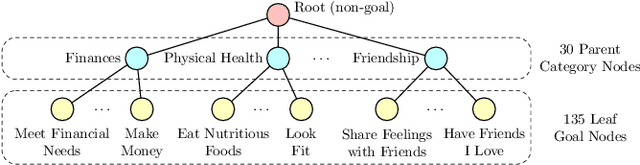
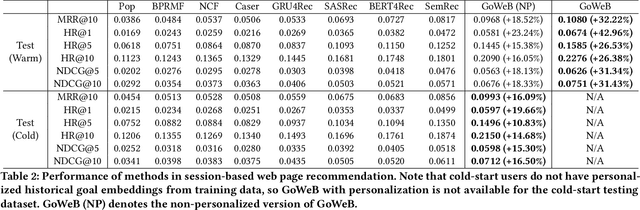
Motives or goals are recognized in psychology literature as the most fundamental drive that explains and predicts why people do what they do, including when they browse the web. Although providing enormous value, these higher-ordered goals are often unobserved, and little is known about how to leverage such goals to assist people's browsing activities. This paper proposes to take a new approach to address this problem, which is fulfilled through a novel neural framework, Goal-directed Web Browsing (GoWeB). We adopt a psychologically-sound taxonomy of higher-ordered goals and learn to build their representations in a structure-preserving manner. Then we incorporate the resulting representations for enhancing the experiences of common activities people perform on the web. Experiments on large-scale data from Microsoft Edge web browser show that GoWeB significantly outperforms competitive baselines for in-session web page recommendation, re-visitation classification, and goal-based web page grouping. A follow-up analysis further characterizes how the variety of human motives can affect the difference observed in human behavioral patterns.
Long Document Ranking with Query-Directed Sparse Transformer
Oct 23, 2020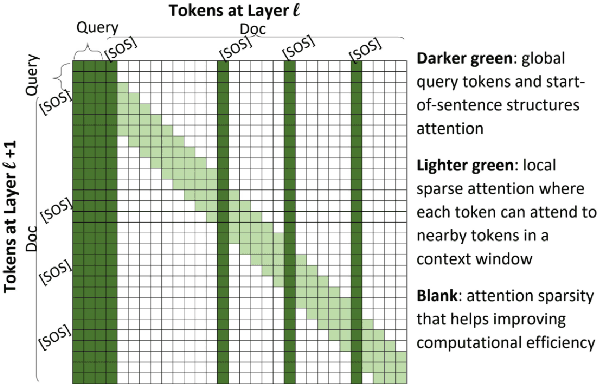
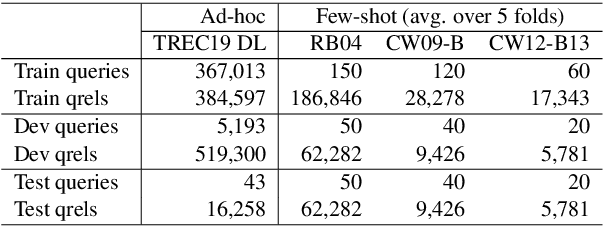
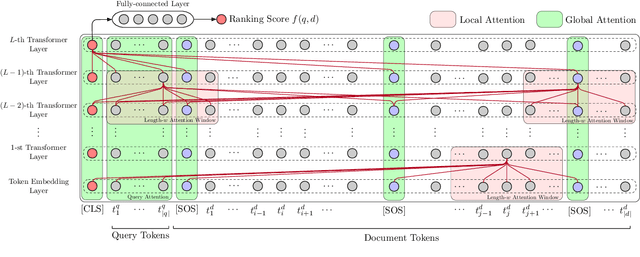

The computing cost of transformer self-attention often necessitates breaking long documents to fit in pretrained models in document ranking tasks. In this paper, we design Query-Directed Sparse attention that induces IR-axiomatic structures in transformer self-attention. Our model, QDS-Transformer, enforces the principle properties desired in ranking: local contextualization, hierarchical representation, and query-oriented proximity matching, while it also enjoys efficiency from sparsity. Experiments on one fully supervised and three few-shot TREC document ranking benchmarks demonstrate the consistent and robust advantage of QDS-Transformer over previous approaches, as they either retrofit long documents into BERT or use sparse attention without emphasizing IR principles. We further quantify the computing complexity and demonstrates that our sparse attention with TVM implementation is twice more efficient than the fully-connected self-attention. All source codes, trained model, and predictions of this work are available at https://github.com/hallogameboy/QDS-Transformer.
Incorporating Behavioral Hypotheses for Query Generation
Oct 06, 2020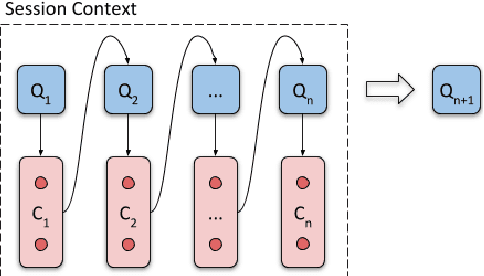
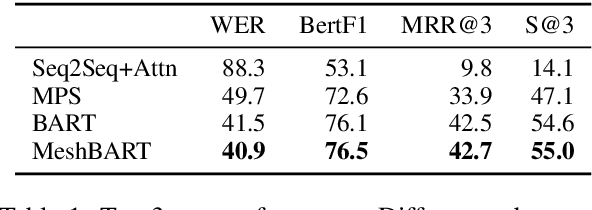
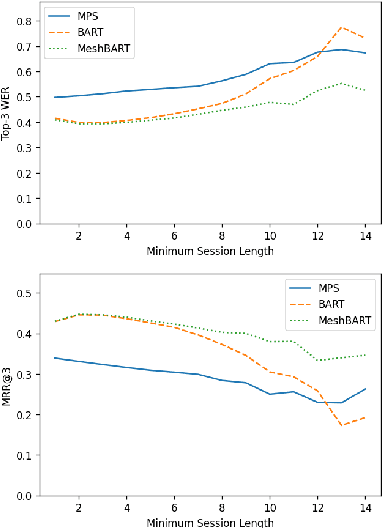

Generative neural networks have been shown effective on query suggestion. Commonly posed as a conditional generation problem, the task aims to leverage earlier inputs from users in a search session to predict queries that they will likely issue at a later time. User inputs come in various forms such as querying and clicking, each of which can imply different semantic signals channeled through the corresponding behavioral patterns. This paper induces these behavioral biases as hypotheses for query generation, where a generic encoder-decoder Transformer framework is presented to aggregate arbitrary hypotheses of choice. Our experimental results show that the proposed approach leads to significant improvements on top-$k$ word error rate and Bert F1 Score compared to a recent BART model.