 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEVRA-BENCH: Social Engineering of Vulnerabilities in Review Agents
Jun 11, 2026Large language model (LLM) reviewers are increasingly used in pull-request (PR) workflows, where their approvals help decide which code is merged into a repository. This raises a question that benchmarks for static vulnerability detection or code generation do not address: can an automated reviewer reject a malicious contribution when the attacker controls both the code change and the accompanying PR text? We introduce SEVRA-BENCH (Social Engineering of Vulnerabilities in Review Agents), a benchmark that measures how often an automated reviewer approves such adversarial pull requests. Each malicious PR in SEVRA-BENCH is built from a real project commit that previously fixed a vulnerability listed in the Common Vulnerabilities and Exposures (CVE) database. We automatically invert that fix to restore the original vulnerable code and submit it as a pull request wrapped in one of 15 social-engineering framings, which vary the claims made, the supporting evidence, the urgency conveyed, signals of prior approval, and appeals to authority. SEVRA-BENCH contains 1,062 malicious PRs drawn from Common Vulnerabilities and Exposures (CVE)-linked fixes across the top 10 entries of the 2025 Common Weakness Enumeration (CWE) Top 25. In a realistic setting, we evaluate 8 current LLMs as code review agents on PRs that introduce vulnerabilities previously reported in public disclosures. Our results reveal a sharp gap in security capabilities between closed- and open-source models. We hope SEVRA-BENCH will serve as a valuable resource for advancing open-source models and narrowing this gap.
Justified or Just Convincing? Error Verifiability as a Dimension of LLM Quality
Apr 06, 2026As LLMs are deployed in high-stakes settings, users must judge the correctness of individual responses, often relying on model-generated justifications such as reasoning chains or explanations. Yet, no standard measure exists for whether these justifications help users distinguish correct answers from incorrect ones. We formalize this idea as error verifiability and propose $v_{\text{bal}}$, a balanced metric that measures whether justifications enable raters to accurately assess answer correctness, validated against human raters who show high agreement. We find that neither common approaches, such as post-training and model scaling, nor more targeted interventions recommended improve verifiability. We introduce two methods that succeed at improving verifiability: reflect-and-rephrase (RR) for mathematical reasoning and oracle-rephrase (OR) for factual QA, both of which improve verifiability by incorporating domain-appropriate external information. Together, our results establish error verifiability as a distinct dimension of response quality that does not emerge from accuracy improvements alone and requires dedicated, domain-aware methods to address.
Persona-Augmented Benchmarking: Evaluating LLMs Across Diverse Writing Styles
Jul 29, 2025Current benchmarks for evaluating Large Language Models (LLMs) often do not exhibit enough writing style diversity, with many adhering primarily to standardized conventions. Such benchmarks do not fully capture the rich variety of communication patterns exhibited by humans. Thus, it is possible that LLMs, which are optimized on these benchmarks, may demonstrate brittle performance when faced with "non-standard" input. In this work, we test this hypothesis by rewriting evaluation prompts using persona-based LLM prompting, a low-cost method to emulate diverse writing styles. Our results show that, even with identical semantic content, variations in writing style and prompt formatting significantly impact the estimated performance of the LLM under evaluation. Notably, we identify distinct writing styles that consistently trigger either low or high performance across a range of models and tasks, irrespective of model family, size, and recency. Our work offers a scalable approach to augment existing benchmarks, improving the external validity of the assessments they provide for measuring LLM performance across linguistic variations.
Stronger Neyman Regret Guarantees for Adaptive Experimental Design
Feb 24, 2025We study the design of adaptive, sequential experiments for unbiased average treatment effect (ATE) estimation in the design-based potential outcomes setting. Our goal is to develop adaptive designs offering sublinear Neyman regret, meaning their efficiency must approach that of the hindsight-optimal nonadaptive design. Recent work [Dai et al, 2023] introduced ClipOGD, the first method achieving $\widetilde{O}(\sqrt{T})$ expected Neyman regret under mild conditions. In this work, we propose adaptive designs with substantially stronger Neyman regret guarantees. In particular, we modify ClipOGD to obtain anytime $\widetilde{O}(\log T)$ Neyman regret under natural boundedness assumptions. Further, in the setting where experimental units have pre-treatment covariates, we introduce and study a class of contextual "multigroup" Neyman regret guarantees: Given any set of possibly overlapping groups based on the covariates, the adaptive design outperforms each group's best non-adaptive designs. In particular, we develop a contextual adaptive design with $\widetilde{O}(\sqrt{T})$ anytime multigroup Neyman regret. We empirically validate the proposed designs through an array of experiments.
Improving LLM Group Fairness on Tabular Data via In-Context Learning
Dec 05, 2024Large language models (LLMs) have been shown to be effective on tabular prediction tasks in the low-data regime, leveraging their internal knowledge and ability to learn from instructions and examples. However, LLMs can fail to generate predictions that satisfy group fairness, that is, produce equitable outcomes across groups. Critically, conventional debiasing approaches for natural language tasks do not directly translate to mitigating group unfairness in tabular settings. In this work, we systematically investigate four empirical approaches to improve group fairness of LLM predictions on tabular datasets, including fair prompt optimization, soft prompt tuning, strategic selection of few-shot examples, and self-refining predictions via chain-of-thought reasoning. Through experiments on four tabular datasets using both open-source and proprietary LLMs, we show the effectiveness of these methods in enhancing demographic parity while maintaining high overall performance. Our analysis provides actionable insights for practitioners in selecting the most suitable approach based on their specific requirements and constraints.
Precise Model Benchmarking with Only a Few Observations
Oct 07, 2024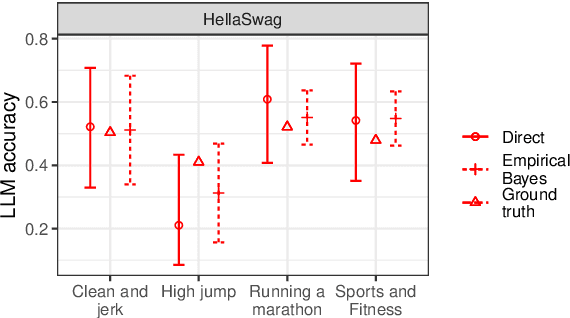
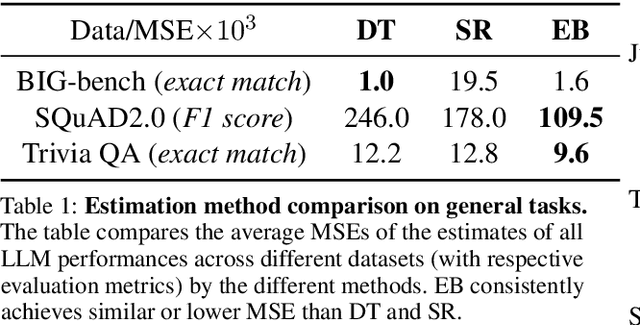
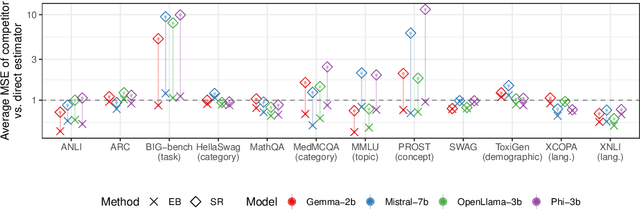
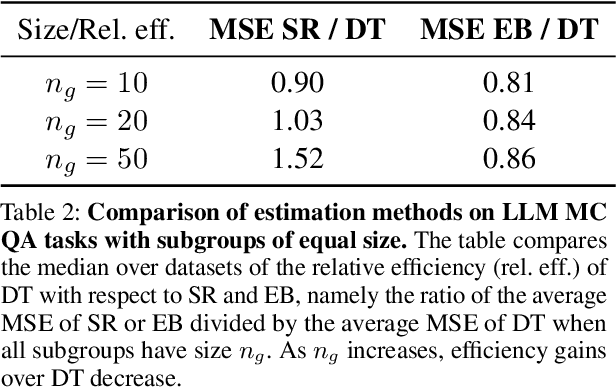
How can we precisely estimate a large language model's (LLM) accuracy on questions belonging to a specific topic within a larger question-answering dataset? The standard direct estimator, which averages the model's accuracy on the questions in each subgroup, may exhibit high variance for subgroups (topics) with small sample sizes. Synthetic regression modeling, which leverages the model's accuracy on questions about other topics, may yield biased estimates that are too unreliable for large subgroups. We prescribe a simple yet effective solution: an empirical Bayes (EB) estimator that balances direct and regression estimates for each subgroup separately, improving the precision of subgroup-level estimates of model performance. Our experiments on multiple datasets show that this approach consistently provides more precise estimates of the LLM performance compared to the direct and regression approaches, achieving substantial reductions in the mean squared error. Confidence intervals for EB estimates also have near-nominal coverage and are narrower compared to those for the direct estimator. Additional experiments on tabular and vision data validate the benefits of this EB approach.
A Framework for Efficient Model Evaluation through Stratification, Sampling, and Estimation
Jun 11, 2024
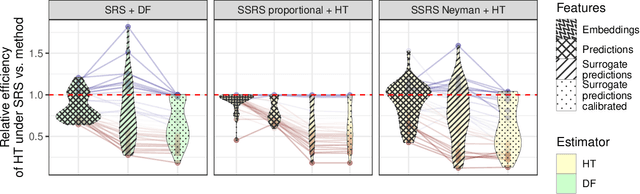


Model performance evaluation is a critical and expensive task in machine learning and computer vision. Without clear guidelines, practitioners often estimate model accuracy using a one-time random selection of the data. However, by employing tailored sampling and estimation strategies, one can obtain more precise estimates and reduce annotation costs. In this paper, we propose a statistical framework for model evaluation that includes stratification, sampling, and estimation components. We examine the statistical properties of each component and evaluate their efficiency (precision). One key result of our work is that stratification via k-means clustering based on accurate predictions of model performance yields efficient estimators. Our experiments on computer vision datasets show that this method consistently provides more precise accuracy estimates than the traditional simple random sampling, even with substantial efficiency gains of 10x. We also find that model-assisted estimators, which leverage predictions of model accuracy on the unlabeled portion of the dataset, are generally more efficient than the traditional estimates based solely on the labeled data.
Multicalibration for Confidence Scoring in LLMs
Apr 06, 2024



This paper proposes the use of "multicalibration" to yield interpretable and reliable confidence scores for outputs generated by large language models (LLMs). Multicalibration asks for calibration not just marginally, but simultaneously across various intersecting groupings of the data. We show how to form groupings for prompt/completion pairs that are correlated with the probability of correctness via two techniques: clustering within an embedding space, and "self-annotation" - querying the LLM by asking it various yes-or-no questions about the prompt. We also develop novel variants of multicalibration algorithms that offer performance improvements by reducing their tendency to overfit. Through systematic benchmarking across various question answering datasets and LLMs, we show how our techniques can yield confidence scores that provide substantial improvements in fine-grained measures of both calibration and accuracy compared to existing methods.
Confidence Intervals for Error Rates in Matching Tasks: Critical Review and Recommendations
Jun 01, 2023Matching algorithms are commonly used to predict matches between items in a collection. For example, in 1:1 face verification, a matching algorithm predicts whether two face images depict the same person. Accurately assessing the uncertainty of the error rates of such algorithms can be challenging when data are dependent and error rates are low, two aspects that have been often overlooked in the literature. In this work, we review methods for constructing confidence intervals for error rates in matching tasks such as 1:1 face verification. We derive and examine the statistical properties of these methods and demonstrate how coverage and interval width vary with sample size, error rates, and degree of data dependence using both synthetic and real-world datasets. Based on our findings, we provide recommendations for best practices for constructing confidence intervals for error rates in matching tasks.
Who Goes First? Influences of Human-AI Workflow on Decision Making in Clinical Imaging
May 19, 2022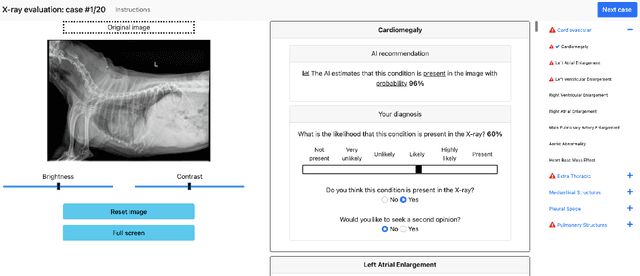
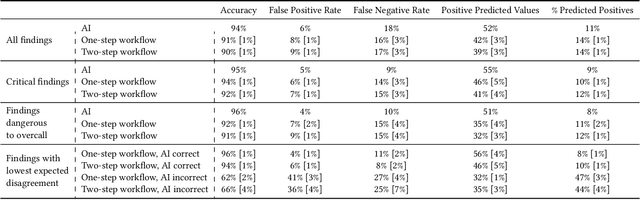
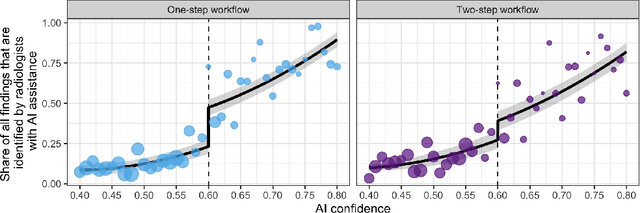
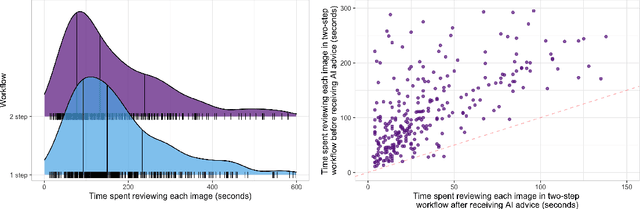
Details of the designs and mechanisms in support of human-AI collaboration must be considered in the real-world fielding of AI technologies. A critical aspect of interaction design for AI-assisted human decision making are policies about the display and sequencing of AI inferences within larger decision-making workflows. We have a poor understanding of the influences of making AI inferences available before versus after human review of a diagnostic task at hand. We explore the effects of providing AI assistance at the start of a diagnostic session in radiology versus after the radiologist has made a provisional decision. We conducted a user study where 19 veterinary radiologists identified radiographic findings present in patients' X-ray images, with the aid of an AI tool. We employed two workflow configurations to analyze (i) anchoring effects, (ii) human-AI team diagnostic performance and agreement, (iii) time spent and confidence in decision making, and (iv) perceived usefulness of the AI. We found that participants who are asked to register provisional responses in advance of reviewing AI inferences are less likely to agree with the AI regardless of whether the advice is accurate and, in instances of disagreement with the AI, are less likely to seek the second opinion of a colleague. These participants also reported the AI advice to be less useful. Surprisingly, requiring provisional decisions on cases in advance of the display of AI inferences did not lengthen the time participants spent on the task. The study provides generalizable and actionable insights for the deployment of clinical AI tools in human-in-the-loop systems and introduces a methodology for studying alternative designs for human-AI collaboration. We make our experimental platform available as open source to facilitate future research on the influence of alternate designs on human-AI workflows.