 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Efficient Model Evaluation through Stratification, Sampling, and Estimation
Paper and Code

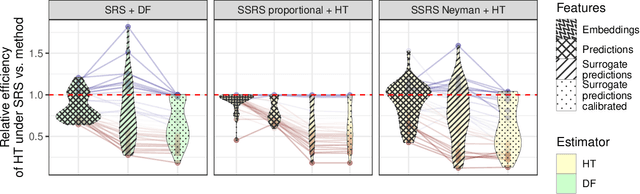


Model performance evaluation is a critical and expensive task in machine learning and computer vision. Without clear guidelines, practitioners often estimate model accuracy using a one-time random selection of the data. However, by employing tailored sampling and estimation strategies, one can obtain more precise estimates and reduce annotation costs. In this paper, we propose a statistical framework for model evaluation that includes stratification, sampling, and estimation components. We examine the statistical properties of each component and evaluate their efficiency (precision). One key result of our work is that stratification via k-means clustering based on accurate predictions of model performance yields efficient estimators. Our experiments on computer vision datasets show that this method consistently provides more precise accuracy estimates than the traditional simple random sampling, even with substantial efficiency gains of 10x. We also find that model-assisted estimators, which leverage predictions of model accuracy on the unlabeled portion of the dataset, are generally more efficient than the traditional estimates based solely on the labeled data.