 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Stochasticity in Deep Research Agents
Feb 26, 2026Deep Research Agents (DRAs) are promising agentic systems that gather and synthesize information to support research across domains such as financial decision-making, medical analysis, and scientific discovery. Despite recent improvements in research quality (e.g., outcome accuracy when ground truth is available), DRA system design often overlooks a critical barrier to real-world deployment: stochasticity. Under identical queries, repeated executions of DRAs can exhibit substantial variability in terms of research outcome, findings, and citations. In this paper, we formalize the study of stochasticity in DRAs by modeling them as information acquisition Markov Decision Processes. We introduce an evaluation framework that quantifies variance in the system and identify three sources of it: information acquisition, information compression, and inference. Through controlled experiments, we investigate how stochasticity from these modules across different decision steps influences the variance of DRA outputs. Our results show that reducing stochasticity can improve research output quality, with inference and early-stage stochasticity contributing the most to DRA output variance. Based on these findings, we propose strategies for mitigating stochasticity while maintaining output quality via structured output and ensemble-based query generation. Our experiments on DeepSearchQA show that our proposed mitigation methods reduce average stochasticity by 22% while maintaining high research quality.
Optimal Unconstrained Self-Distillation in Ridge Regression: Strict Improvements, Precise Asymptotics, and One-Shot Tuning
Feb 19, 2026Self-distillation (SD) is the process of retraining a student on a mixture of ground-truth labels and the teacher's own predictions using the same architecture and training data. Although SD has been empirically shown to often improve generalization, its formal guarantees remain limited. We study SD for ridge regression in unconstrained setting in which the mixing weight $ξ$ may be outside the unit interval. Conditioned on the training data and without any distributional assumptions, we prove that for any squared prediction risk (including out-of-distribution), the optimally mixed student strictly improves upon the ridge teacher for every regularization level $λ> 0$ at which the teacher ridge risk $R(λ)$ is nonstationary (i.e., $R'(λ) \neq 0$). We obtain a closed-form expression for the optimal mixing weight $ξ^\star(λ)$ for any value of $λ$ and show that it obeys the sign rule: $\operatorname{sign}(ξ^\star(λ))=-\operatorname{sign}(R'(λ))$. In particular, $ξ^\star(λ)$ can be negative, which is the case in over-regularized regimes. To quantify the risk improvement due to SD, we derive exact deterministic equivalents for the optimal SD risk in the proportional asymptotics regime (where the sample and feature sizes $n$ and $p$ both diverge but their aspect ratio $p/n$ converges) under general anisotropic covariance and deterministic signals. Our asymptotic analysis extends standard second-order ridge deterministic equivalents to their fourth-order analogs using block linearization, which may be of independent interest. From a practical standpoint, we propose a consistent one-shot tuning method to estimate $ξ^\star$ without grid search, sample splitting, or refitting. Experiments on real-world datasets and pretrained neural network features support our theory and the one-shot tuning method.
Precise Model Benchmarking with Only a Few Observations
Oct 07, 2024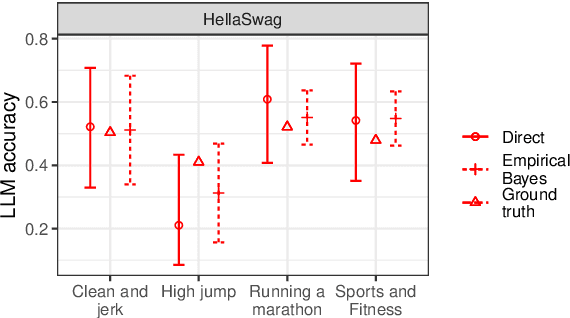
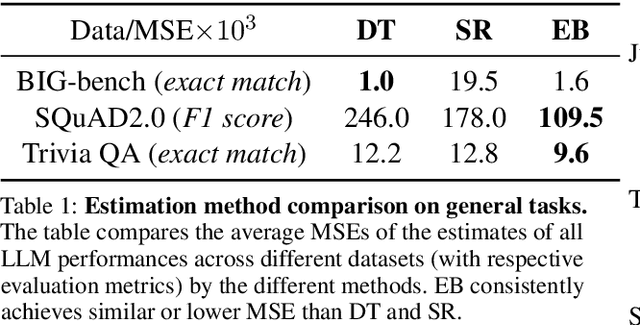
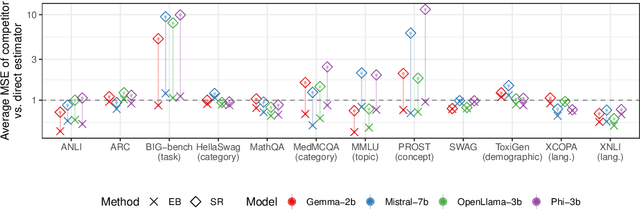
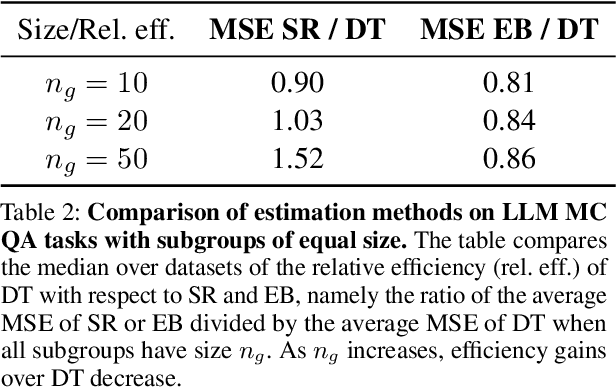
How can we precisely estimate a large language model's (LLM) accuracy on questions belonging to a specific topic within a larger question-answering dataset? The standard direct estimator, which averages the model's accuracy on the questions in each subgroup, may exhibit high variance for subgroups (topics) with small sample sizes. Synthetic regression modeling, which leverages the model's accuracy on questions about other topics, may yield biased estimates that are too unreliable for large subgroups. We prescribe a simple yet effective solution: an empirical Bayes (EB) estimator that balances direct and regression estimates for each subgroup separately, improving the precision of subgroup-level estimates of model performance. Our experiments on multiple datasets show that this approach consistently provides more precise estimates of the LLM performance compared to the direct and regression approaches, achieving substantial reductions in the mean squared error. Confidence intervals for EB estimates also have near-nominal coverage and are narrower compared to those for the direct estimator. Additional experiments on tabular and vision data validate the benefits of this EB approach.
Revisiting Optimism and Model Complexity in the Wake of Overparameterized Machine Learning
Oct 02, 2024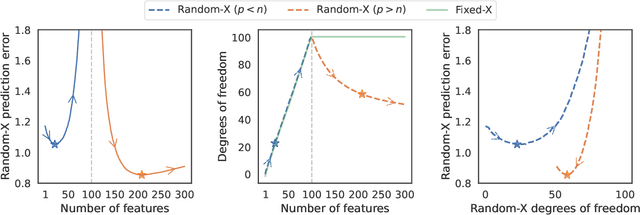

Common practice in modern machine learning involves fitting a large number of parameters relative to the number of observations. These overparameterized models can exhibit surprising generalization behavior, e.g., ``double descent'' in the prediction error curve when plotted against the raw number of model parameters, or another simplistic notion of complexity. In this paper, we revisit model complexity from first principles, by first reinterpreting and then extending the classical statistical concept of (effective) degrees of freedom. Whereas the classical definition is connected to fixed-X prediction error (in which prediction error is defined by averaging over the same, nonrandom covariate points as those used during training), our extension of degrees of freedom is connected to random-X prediction error (in which prediction error is averaged over a new, random sample from the covariate distribution). The random-X setting more naturally embodies modern machine learning problems, where highly complex models, even those complex enough to interpolate the training data, can still lead to desirable generalization performance under appropriate conditions. We demonstrate the utility of our proposed complexity measures through a mix of conceptual arguments, theory, and experiments, and illustrate how they can be used to interpret and compare arbitrary prediction models.
Implicit Regularization Paths of Weighted Neural Representations
Aug 28, 2024
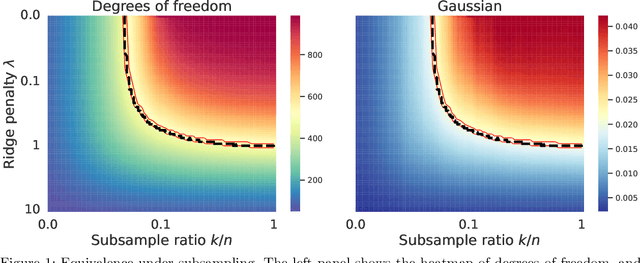
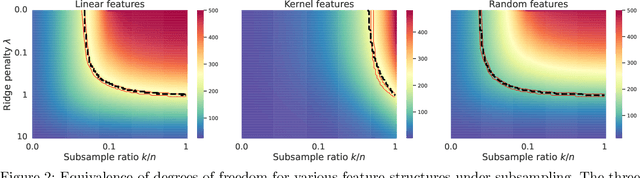
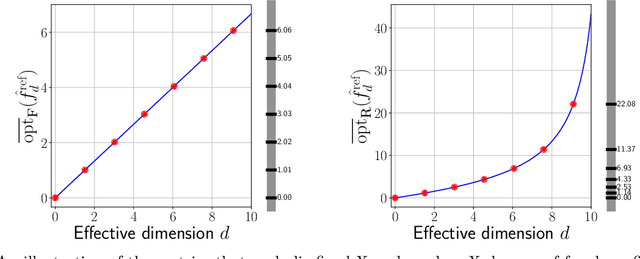
We study the implicit regularization effects induced by (observation) weighting of pretrained features. For weight and feature matrices of bounded operator norms that are infinitesimally free with respect to (normalized) trace functionals, we derive equivalence paths connecting different weighting matrices and ridge regularization levels. Specifically, we show that ridge estimators trained on weighted features along the same path are asymptotically equivalent when evaluated against test vectors of bounded norms. These paths can be interpreted as matching the effective degrees of freedom of ridge estimators fitted with weighted features. For the special case of subsampling without replacement, our results apply to independently sampled random features and kernel features and confirm recent conjectures (Conjectures 7 and 8) of the authors on the existence of such paths in Patil et al. We also present an additive risk decomposition for ensembles of weighted estimators and show that the risks are equivalent along the paths when the ensemble size goes to infinity. As a practical consequence of the path equivalences, we develop an efficient cross-validation method for tuning and apply it to subsampled pretrained representations across several models (e.g., ResNet-50) and datasets (e.g., CIFAR-100).
A Framework for Efficient Model Evaluation through Stratification, Sampling, and Estimation
Jun 11, 2024
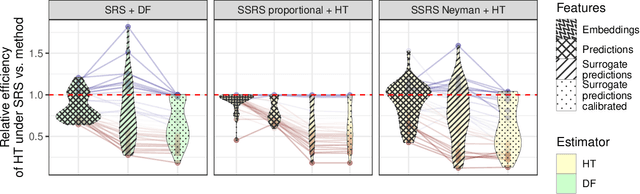


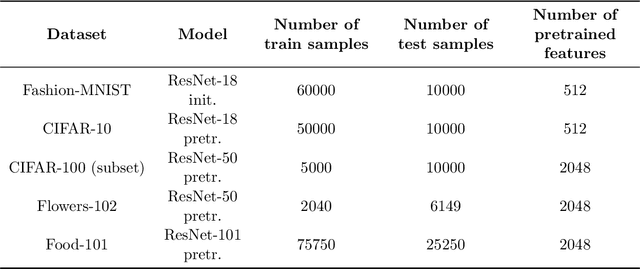
Model performance evaluation is a critical and expensive task in machine learning and computer vision. Without clear guidelines, practitioners often estimate model accuracy using a one-time random selection of the data. However, by employing tailored sampling and estimation strategies, one can obtain more precise estimates and reduce annotation costs. In this paper, we propose a statistical framework for model evaluation that includes stratification, sampling, and estimation components. We examine the statistical properties of each component and evaluate their efficiency (precision). One key result of our work is that stratification via k-means clustering based on accurate predictions of model performance yields efficient estimators. Our experiments on computer vision datasets show that this method consistently provides more precise accuracy estimates than the traditional simple random sampling, even with substantial efficiency gains of 10x. We also find that model-assisted estimators, which leverage predictions of model accuracy on the unlabeled portion of the dataset, are generally more efficient than the traditional estimates based solely on the labeled data.
Optimal Ridge Regularization for Out-of-Distribution Prediction
Apr 01, 2024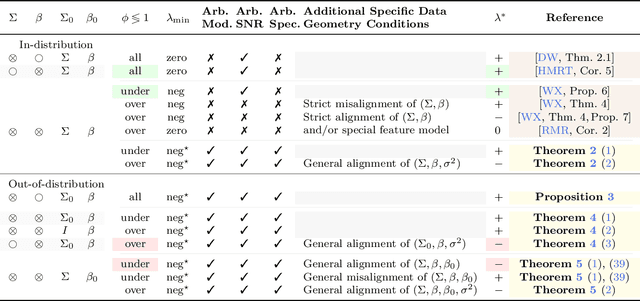
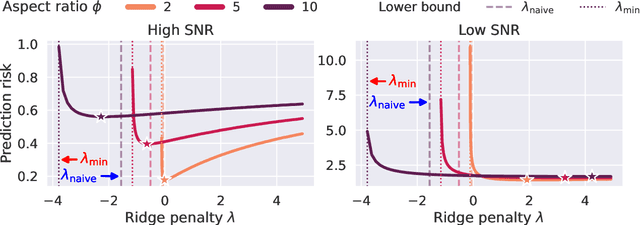
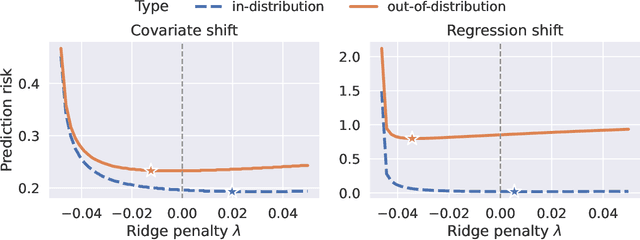

We study the behavior of optimal ridge regularization and optimal ridge risk for out-of-distribution prediction, where the test distribution deviates arbitrarily from the train distribution. We establish general conditions that determine the sign of the optimal regularization level under covariate and regression shifts. These conditions capture the alignment between the covariance and signal structures in the train and test data and reveal stark differences compared to the in-distribution setting. For example, a negative regularization level can be optimal under covariate shift or regression shift, even when the training features are isotropic or the design is underparameterized. Furthermore, we prove that the optimally-tuned risk is monotonic in the data aspect ratio, even in the out-of-distribution setting and when optimizing over negative regularization levels. In general, our results do not make any modeling assumptions for the train or the test distributions, except for moment bounds, and allow for arbitrary shifts and the widest possible range of (negative) regularization levels.
Failures and Successes of Cross-Validation for Early-Stopped Gradient Descent
Feb 26, 2024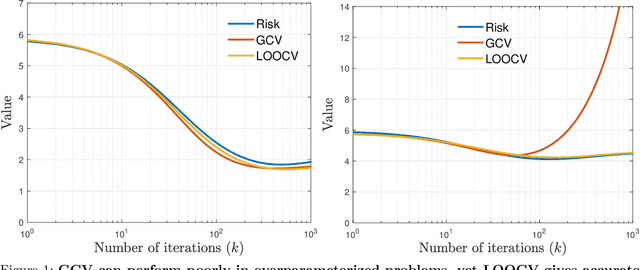
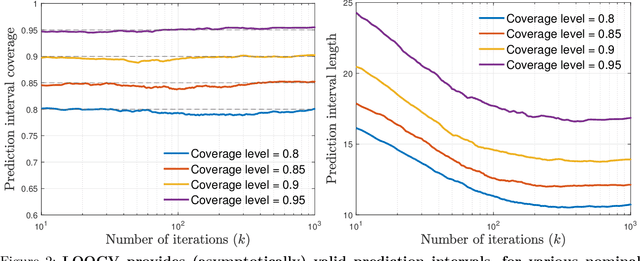
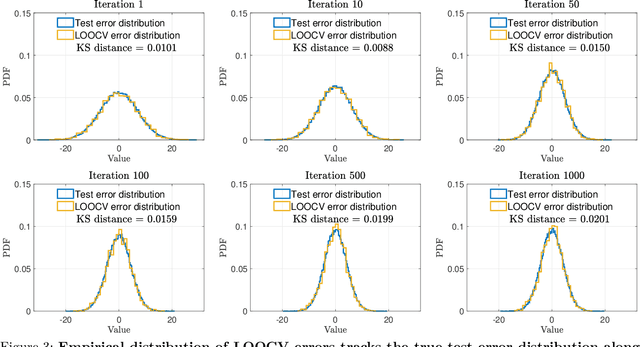

We analyze the statistical properties of generalized cross-validation (GCV) and leave-one-out cross-validation (LOOCV) applied to early-stopped gradient descent (GD) in high-dimensional least squares regression. We prove that GCV is generically inconsistent as an estimator of the prediction risk of early-stopped GD, even for a well-specified linear model with isotropic features. In contrast, we show that LOOCV converges uniformly along the GD trajectory to the prediction risk. Our theory requires only mild assumptions on the data distribution and does not require the underlying regression function to be linear. Furthermore, by leveraging the individual LOOCV errors, we construct consistent estimators for the entire prediction error distribution along the GD trajectory and consistent estimators for a wide class of error functionals. This in particular enables the construction of pathwise prediction intervals based on GD iterates that have asymptotically correct nominal coverage conditional on the training data.
Asymptotically free sketched ridge ensembles: Risks, cross-validation, and tuning
Oct 06, 2023



We employ random matrix theory to establish consistency of generalized cross validation (GCV) for estimating prediction risks of sketched ridge regression ensembles, enabling efficient and consistent tuning of regularization and sketching parameters. Our results hold for a broad class of asymptotically free sketches under very mild data assumptions. For squared prediction risk, we provide a decomposition into an unsketched equivalent implicit ridge bias and a sketching-based variance, and prove that the risk can be globally optimized by only tuning sketch size in infinite ensembles. For general subquadratic prediction risk functionals, we extend GCV to construct consistent risk estimators, and thereby obtain distributional convergence of the GCV-corrected predictions in Wasserstein-2 metric. This in particular allows construction of prediction intervals with asymptotically correct coverage conditional on the training data. We also propose an "ensemble trick" whereby the risk for unsketched ridge regression can be efficiently estimated via GCV using small sketched ridge ensembles. We empirically validate our theoretical results using both synthetic and real large-scale datasets with practical sketches including CountSketch and subsampled randomized discrete cosine transforms.
Corrected generalized cross-validation for finite ensembles of penalized estimators
Oct 02, 2023


Generalized cross-validation (GCV) is a widely-used method for estimating the squared out-of-sample prediction risk that employs a scalar degrees of freedom adjustment (in a multiplicative sense) to the squared training error. In this paper, we examine the consistency of GCV for estimating the prediction risk of arbitrary ensembles of penalized least squares estimators. We show that GCV is inconsistent for any finite ensemble of size greater than one. Towards repairing this shortcoming, we identify a correction that involves an additional scalar correction (in an additive sense) based on degrees of freedom adjusted training errors from each ensemble component. The proposed estimator (termed CGCV) maintains the computational advantages of GCV and requires neither sample splitting, model refitting, or out-of-bag risk estimation. The estimator stems from a finer inspection of ensemble risk decomposition and two intermediate risk estimators for the components in this decomposition. We provide a non-asymptotic analysis of the CGCV and the two intermediate risk estimators for ensembles of convex penalized estimators under Gaussian features and a linear response model. In the special case of ridge regression, we extend the analysis to general feature and response distributions using random matrix theory, which establishes model-free uniform consistency of CGCV.