 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBasic Inequalities for First-Order Optimization with Applications to Statistical Risk Analysis
Dec 31, 2025We introduce \textit{basic inequalities} for first-order iterative optimization algorithms, forming a simple and versatile framework that connects implicit and explicit regularization. While related inequalities appear in the literature, we isolate and highlight a specific form and develop it as a well-rounded tool for statistical analysis. Let $f$ denote the objective function to be optimized. Given a first-order iterative algorithm initialized at $θ_0$ with current iterate $θ_T$, the basic inequality upper bounds $f(θ_T)-f(z)$ for any reference point $z$ in terms of the accumulated step sizes and the distances between $θ_0$, $θ_T$, and $z$. The bound translates the number of iterations into an effective regularization coefficient in the loss function. We demonstrate this framework through analyses of training dynamics and prediction risk bounds. In addition to revisiting and refining known results on gradient descent, we provide new results for mirror descent with Bregman divergence projection, for generalized linear models trained by gradient descent and exponentiated gradient descent, and for randomized predictors. We illustrate and supplement these theoretical findings with experiments on generalized linear models.
Calibrated Multi-Level Quantile Forecasting
Dec 29, 2025We present an online method for guaranteeing calibration of quantile forecasts at multiple quantile levels simultaneously. A sequence of $α$-level quantile forecasts is calibrated if the forecasts are larger than the target value at an $α$-fraction of time steps. We introduce a lightweight method called Multi-Level Quantile Tracker (MultiQT) that wraps around any existing point or quantile forecaster to produce corrected forecasts guaranteed to achieve calibration, even against adversarial distribution shifts, while ensuring that the forecasts are ordered -- e.g., the 0.5-level quantile forecast is never larger than the 0.6-level forecast. Furthermore, the method comes with a no-regret guarantee that implies it will not worsen the performance of an existing forecaster, asymptotically, with respect to the quantile loss. In experiments, we find that MultiQT significantly improves the calibration of real forecasters in epidemic and energy forecasting problems.
Sample-Efficient Omniprediction for Proper Losses
Oct 14, 2025We consider the problem of constructing probabilistic predictions that lead to accurate decisions when employed by downstream users to inform actions. For a single decision maker, designing an optimal predictor is equivalent to minimizing a proper loss function corresponding to the negative utility of that individual. For multiple decision makers, our problem can be viewed as a variant of omniprediction in which the goal is to design a single predictor that simultaneously minimizes multiple losses. Existing algorithms for achieving omniprediction broadly fall into two categories: 1) boosting methods that optimize other auxiliary targets such as multicalibration and obtain omniprediction as a corollary, and 2) adversarial two-player game based approaches that estimate and respond to the ``worst-case" loss in an online fashion. We give lower bounds demonstrating that multicalibration is a strictly more difficult problem than omniprediction and thus the former approach must incur suboptimal sample complexity. For the latter approach, we discuss how these ideas can be used to obtain a sample-efficient algorithm through an online-to-batch conversion. This conversion has the downside of returning a complex, randomized predictor. We improve on this method by designing a more direct, unrandomized algorithm that exploits structural elements of the set of proper losses.
Gradient Equilibrium in Online Learning: Theory and Applications
Jan 14, 2025
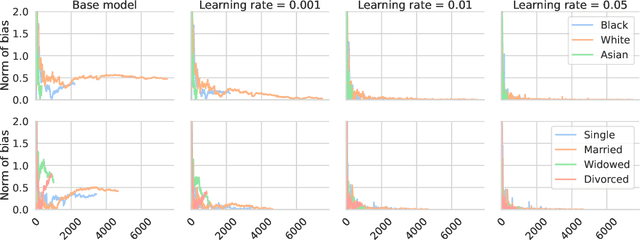
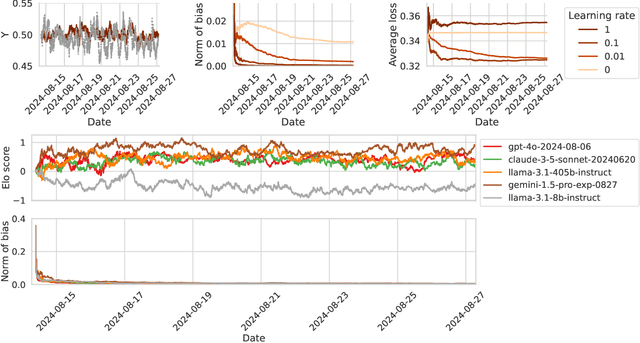
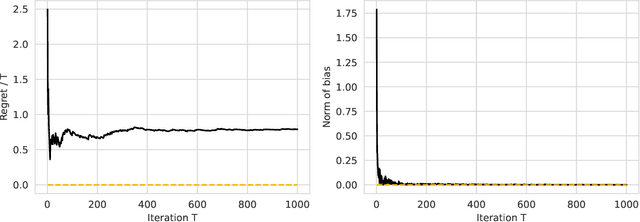
We present a new perspective on online learning that we refer to as gradient equilibrium: a sequence of iterates achieves gradient equilibrium if the average of gradients of losses along the sequence converges to zero. In general, this condition is not implied by nor implies sublinear regret. It turns out that gradient equilibrium is achievable by standard online learning methods such as gradient descent and mirror descent with constant step sizes (rather than decaying step sizes, as is usually required for no regret). Further, as we show through examples, gradient equilibrium translates into an interpretable and meaningful property in online prediction problems spanning regression, classification, quantile estimation, and others. Notably, we show that the gradient equilibrium framework can be used to develop a debiasing scheme for black-box predictions under arbitrary distribution shift, based on simple post hoc online descent updates. We also show that post hoc gradient updates can be used to calibrate predicted quantiles under distribution shift, and that the framework leads to unbiased Elo scores for pairwise preference prediction.
Revisiting Optimism and Model Complexity in the Wake of Overparameterized Machine Learning
Oct 02, 2024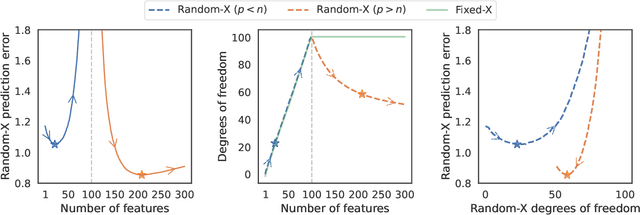

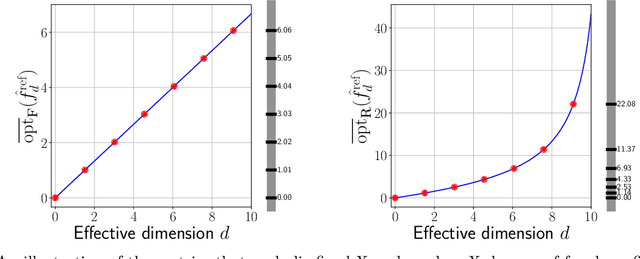
Common practice in modern machine learning involves fitting a large number of parameters relative to the number of observations. These overparameterized models can exhibit surprising generalization behavior, e.g., ``double descent'' in the prediction error curve when plotted against the raw number of model parameters, or another simplistic notion of complexity. In this paper, we revisit model complexity from first principles, by first reinterpreting and then extending the classical statistical concept of (effective) degrees of freedom. Whereas the classical definition is connected to fixed-X prediction error (in which prediction error is defined by averaging over the same, nonrandom covariate points as those used during training), our extension of degrees of freedom is connected to random-X prediction error (in which prediction error is averaged over a new, random sample from the covariate distribution). The random-X setting more naturally embodies modern machine learning problems, where highly complex models, even those complex enough to interpolate the training data, can still lead to desirable generalization performance under appropriate conditions. We demonstrate the utility of our proposed complexity measures through a mix of conceptual arguments, theory, and experiments, and illustrate how they can be used to interpret and compare arbitrary prediction models.
Optimal Ridge Regularization for Out-of-Distribution Prediction
Apr 01, 2024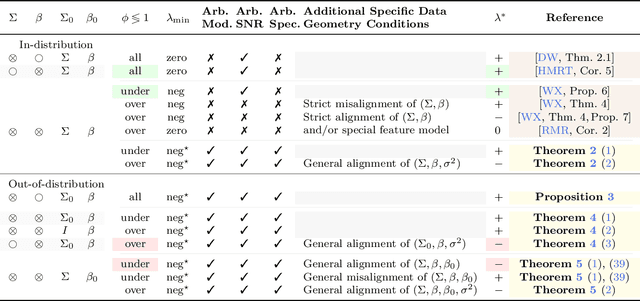
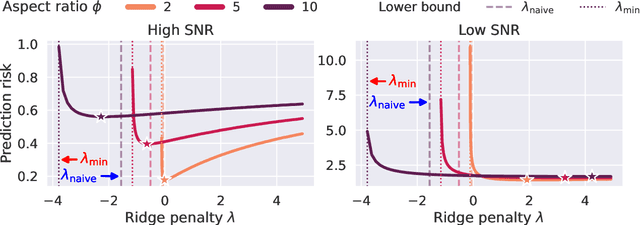
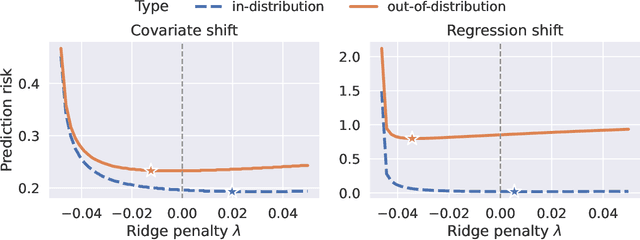

We study the behavior of optimal ridge regularization and optimal ridge risk for out-of-distribution prediction, where the test distribution deviates arbitrarily from the train distribution. We establish general conditions that determine the sign of the optimal regularization level under covariate and regression shifts. These conditions capture the alignment between the covariance and signal structures in the train and test data and reveal stark differences compared to the in-distribution setting. For example, a negative regularization level can be optimal under covariate shift or regression shift, even when the training features are isotropic or the design is underparameterized. Furthermore, we prove that the optimally-tuned risk is monotonic in the data aspect ratio, even in the out-of-distribution setting and when optimizing over negative regularization levels. In general, our results do not make any modeling assumptions for the train or the test distributions, except for moment bounds, and allow for arbitrary shifts and the widest possible range of (negative) regularization levels.
Failures and Successes of Cross-Validation for Early-Stopped Gradient Descent
Feb 26, 2024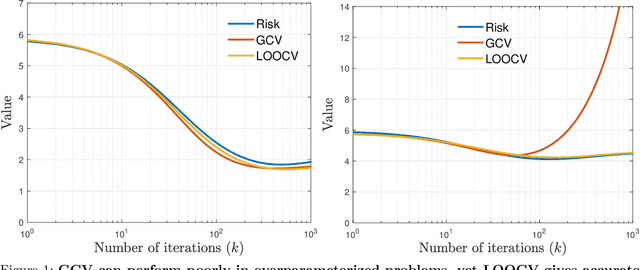
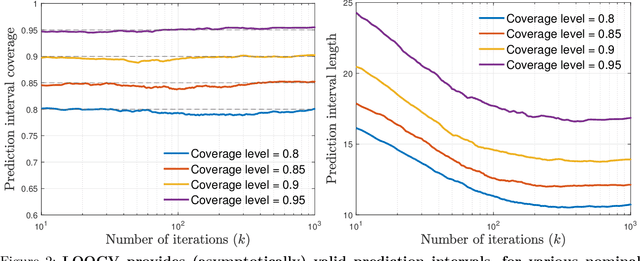
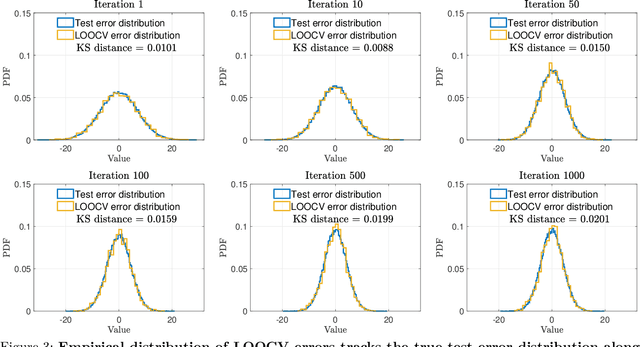

We analyze the statistical properties of generalized cross-validation (GCV) and leave-one-out cross-validation (LOOCV) applied to early-stopped gradient descent (GD) in high-dimensional least squares regression. We prove that GCV is generically inconsistent as an estimator of the prediction risk of early-stopped GD, even for a well-specified linear model with isotropic features. In contrast, we show that LOOCV converges uniformly along the GD trajectory to the prediction risk. Our theory requires only mild assumptions on the data distribution and does not require the underlying regression function to be linear. Furthermore, by leveraging the individual LOOCV errors, we construct consistent estimators for the entire prediction error distribution along the GD trajectory and consistent estimators for a wide class of error functionals. This in particular enables the construction of pathwise prediction intervals based on GD iterates that have asymptotically correct nominal coverage conditional on the training data.
Maximum Mean Discrepancy Meets Neural Networks: The Radon-Kolmogorov-Smirnov Test
Sep 13, 2023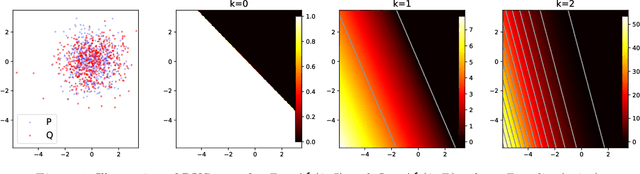

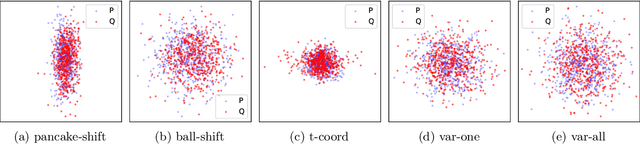
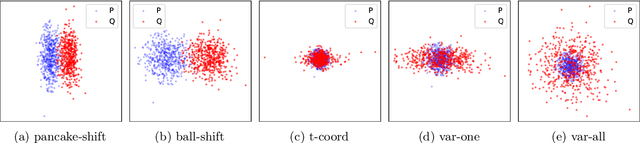
Maximum mean discrepancy (MMD) refers to a general class of nonparametric two-sample tests that are based on maximizing the mean difference over samples from one distribution $P$ versus another $Q$, over all choices of data transformations $f$ living in some function space $\mathcal{F}$. Inspired by recent work that connects what are known as functions of $\textit{Radon bounded variation}$ (RBV) and neural networks (Parhi and Nowak, 2021, 2023), we study the MMD defined by taking $\mathcal{F}$ to be the unit ball in the RBV space of a given smoothness order $k \geq 0$. This test, which we refer to as the $\textit{Radon-Kolmogorov-Smirnov}$ (RKS) test, can be viewed as a generalization of the well-known and classical Kolmogorov-Smirnov (KS) test to multiple dimensions and higher orders of smoothness. It is also intimately connected to neural networks: we prove that the witness in the RKS test -- the function $f$ achieving the maximum mean difference -- is always a ridge spline of degree $k$, i.e., a single neuron in a neural network. This allows us to leverage the power of modern deep learning toolkits to (approximately) optimize the criterion that underlies the RKS test. We prove that the RKS test has asymptotically full power at distinguishing any distinct pair $P \not= Q$ of distributions, derive its asymptotic null distribution, and carry out extensive experiments to elucidate the strengths and weakenesses of the RKS test versus the more traditional kernel MMD test.
Conformal PID Control for Time Series Prediction
Jul 31, 2023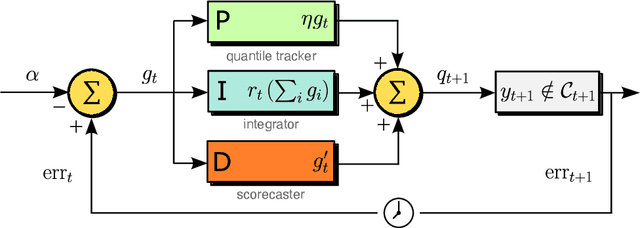
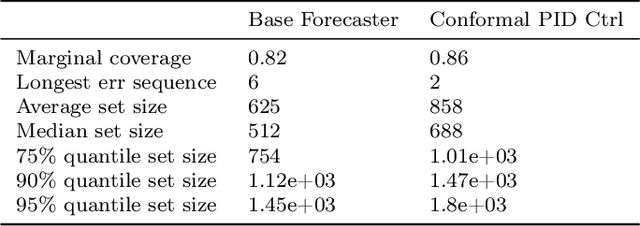
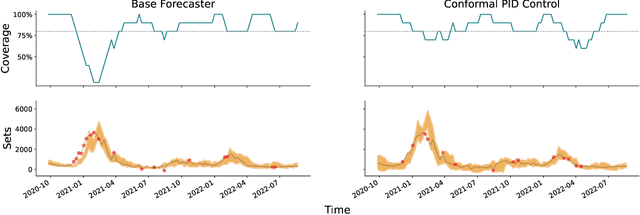
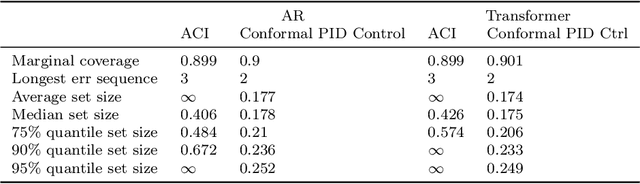
We study the problem of uncertainty quantification for time series prediction, with the goal of providing easy-to-use algorithms with formal guarantees. The algorithms we present build upon ideas from conformal prediction and control theory, are able to prospectively model conformal scores in an online setting, and adapt to the presence of systematic errors due to seasonality, trends, and general distribution shifts. Our theory both simplifies and strengthens existing analyses in online conformal prediction. Experiments on 4-week-ahead forecasting of statewide COVID-19 death counts in the U.S. show an improvement in coverage over the ensemble forecaster used in official CDC communications. We also run experiments on predicting electricity demand, market returns, and temperature using autoregressive, Theta, Prophet, and Transformer models. We provide an extendable codebase for testing our methods and for the integration of new algorithms, data sets, and forecasting rules.
Class-Conditional Conformal Prediction With Many Classes
Jun 15, 2023

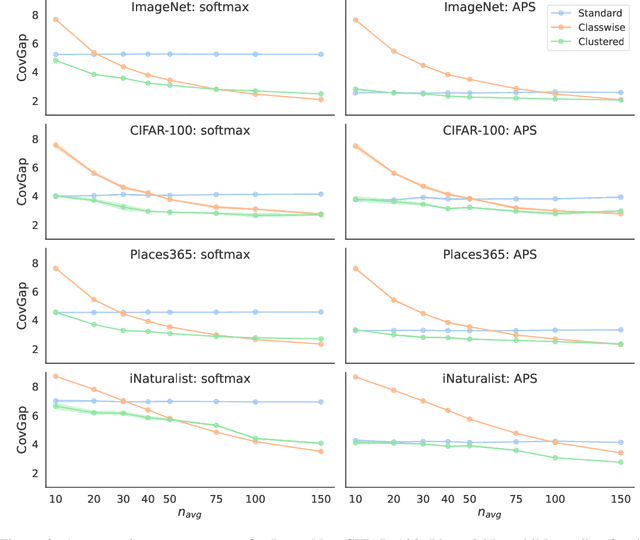
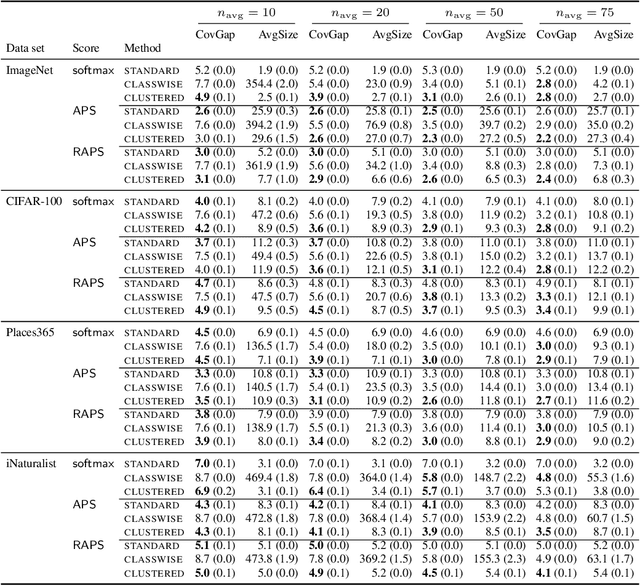
Standard conformal prediction methods provide a marginal coverage guarantee, which means that for a random test point, the conformal prediction set contains the true label with a user-chosen probability. In many classification problems, we would like to obtain a stronger guarantee -- that for test points of a specific class, the prediction set contains the true label with the same user-chosen probability. Existing conformal prediction methods do not work well when there is a limited amount of labeled data per class, as is often the case in real applications where the number of classes is large. We propose a method called clustered conformal prediction, which clusters together classes that have "similar" conformal scores and then performs conformal prediction at the cluster level. Based on empirical evaluation across four image data sets with many (up to 1000) classes, we find that clustered conformal typically outperforms existing methods in terms of class-conditional coverage and set size metrics.