 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn AI-Based Public Health Data Monitoring System
Jun 04, 2025Public health experts need scalable approaches to monitor large volumes of health data (e.g., cases, hospitalizations, deaths) for outbreaks or data quality issues. Traditional alert-based monitoring systems struggle with modern public health data monitoring systems for several reasons, including that alerting thresholds need to be constantly reset and the data volumes may cause application lag. Instead, we propose a ranking-based monitoring paradigm that leverages new AI anomaly detection methods. Through a multi-year interdisciplinary collaboration, the resulting system has been deployed at a national organization to monitor up to 5,000,000 data points daily. A three-month longitudinal deployed evaluation revealed a significant improvement in monitoring objectives, with a 54x increase in reviewer speed efficiency compared to traditional alert-based methods. This work highlights the potential of human-centered AI to transform public health decision-making.
Outlier Ranking in Large-Scale Public Health Streams
Jan 02, 2024Disease control experts inspect public health data streams daily for outliers worth investigating, like those corresponding to data quality issues or disease outbreaks. However, they can only examine a few of the thousands of maximally-tied outliers returned by univariate outlier detection methods applied to large-scale public health data streams. To help experts distinguish the most important outliers from these thousands of tied outliers, we propose a new task for algorithms to rank the outputs of any univariate method applied to each of many streams. Our novel algorithm for this task, which leverages hierarchical networks and extreme value analysis, performed the best across traditional outlier detection metrics in a human-expert evaluation using public health data streams. Most importantly, experts have used our open-source Python implementation since April 2023 and report identifying outliers worth investigating 9.1x faster than their prior baseline. Other organizations can readily adapt this implementation to create rankings from the outputs of their tailored univariate methods across large-scale streams.
Correcting for heterogeneity in real-time epidemiological indicators
Sep 28, 2023



Auxiliary data sources have become increasingly important in epidemiological surveillance, as they are often available at a finer spatial and temporal resolution, larger coverage, and lower latency than traditional surveillance signals. We describe the problem of spatial and temporal heterogeneity in these signals derived from these data sources, where spatial and/or temporal biases are present. We present a method to use a ``guiding'' signal to correct for these biases and produce a more reliable signal that can be used for modeling and forecasting. The method assumes that the heterogeneity can be approximated by a low-rank matrix and that the temporal heterogeneity is smooth over time. We also present a hyperparameter selection algorithm to choose the parameters representing the matrix rank and degree of temporal smoothness of the corrections. In the absence of ground truth, we use maps and plots to argue that this method does indeed reduce heterogeneity. Reducing heterogeneity from auxiliary data sources greatly increases their utility in modeling and forecasting epidemics.
Federated Epidemic Surveillance
Jul 05, 2023



The surveillance of a pandemic is a challenging task, especially when crucial data is distributed and stakeholders cannot or are unwilling to share. To overcome this obstacle, federated methodologies should be developed to incorporate less sensitive evidence that entities are willing to provide. This study aims to explore the feasibility of pushing hypothesis tests behind each custodian's firewall and then meta-analysis to combine the results, and to determine the optimal approach for reconstructing the hypothesis test and optimizing the inference. We propose a hypothesis testing framework to identify a surge in the indicators and conduct power analyses and experiments on real and semi-synthetic data to showcase the properties of our proposed hypothesis test and suggest suitable methods for combining $p$-values. Our findings highlight the potential of using $p$-value combination as a federated methodology for pandemic surveillance and provide valuable insights into integrating available data sources.
Computationally Assisted Quality Control for Public Health Data Streams
Jun 29, 2023Irregularities in public health data streams (like COVID-19 Cases) hamper data-driven decision-making for public health stakeholders. A real-time, computer-generated list of the most important, outlying data points from thousands of daily-updated public health data streams could assist an expert reviewer in identifying these irregularities. However, existing outlier detection frameworks perform poorly on this task because they do not account for the data volume or for the statistical properties of public health streams. Accordingly, we developed FlaSH (Flagging Streams in public Health), a practical outlier detection framework for public health data users that uses simple, scalable models to capture these statistical properties explicitly. In an experiment where human experts evaluate FlaSH and existing methods (including deep learning approaches), FlaSH scales to the data volume of this task, matches or exceeds these other methods in mean accuracy, and identifies the outlier points that users empirically rate as more helpful. Based on these results, FlaSH has been deployed on data streams used by public health stakeholders.
Recalibrating probabilistic forecasts of epidemics
Dec 12, 2021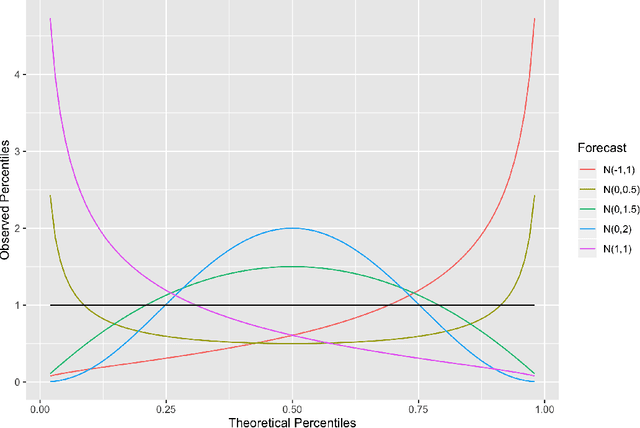
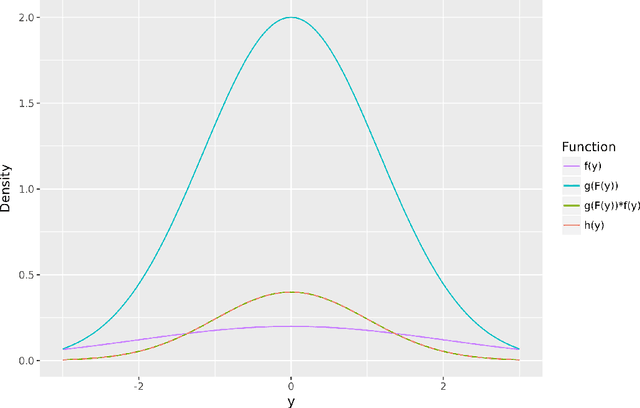
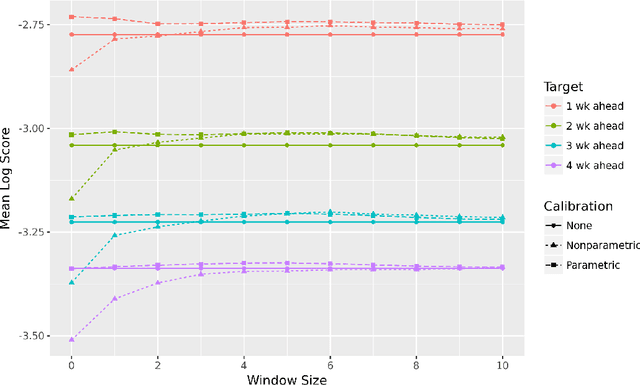
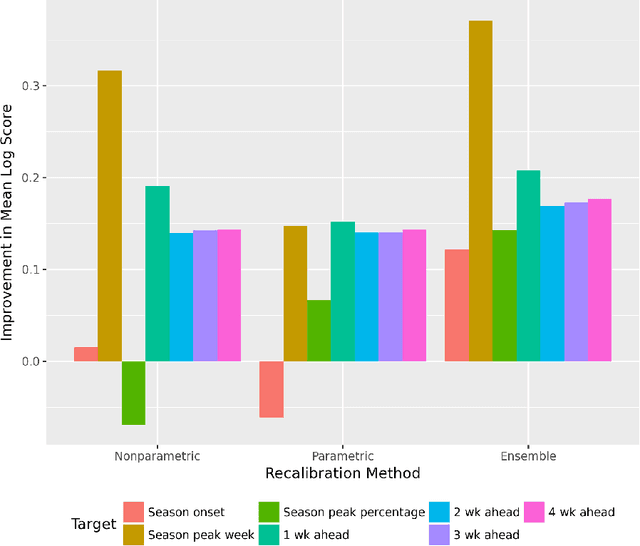
Distributional forecasts are important for a wide variety of applications, including forecasting epidemics. Often, forecasts are miscalibrated, or unreliable in assigning uncertainty to future events. We present a recalibration method that can be applied to a black-box forecaster given retrospective forecasts and observations, as well as an extension to make this method more effective in recalibrating epidemic forecasts. This method is guaranteed to improve calibration and log score performance when trained and measured in-sample. We also prove that the increase in expected log score of a recalibrated forecaster is equal to the entropy of the PIT distribution. We apply this recalibration method to the 27 influenza forecasters in the FluSight Network and show that recalibration reliably improves forecast accuracy and calibration. This method is effective, robust, and easy to use as a post-processing tool to improve epidemic forecasts.