 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputationally Assisted Quality Control for Public Health Data Streams
Jun 29, 2023Irregularities in public health data streams (like COVID-19 Cases) hamper data-driven decision-making for public health stakeholders. A real-time, computer-generated list of the most important, outlying data points from thousands of daily-updated public health data streams could assist an expert reviewer in identifying these irregularities. However, existing outlier detection frameworks perform poorly on this task because they do not account for the data volume or for the statistical properties of public health streams. Accordingly, we developed FlaSH (Flagging Streams in public Health), a practical outlier detection framework for public health data users that uses simple, scalable models to capture these statistical properties explicitly. In an experiment where human experts evaluate FlaSH and existing methods (including deep learning approaches), FlaSH scales to the data volume of this task, matches or exceeds these other methods in mean accuracy, and identifies the outlier points that users empirically rate as more helpful. Based on these results, FlaSH has been deployed on data streams used by public health stakeholders.
Conversational Neuro-Symbolic Commonsense Reasoning
Jun 19, 2020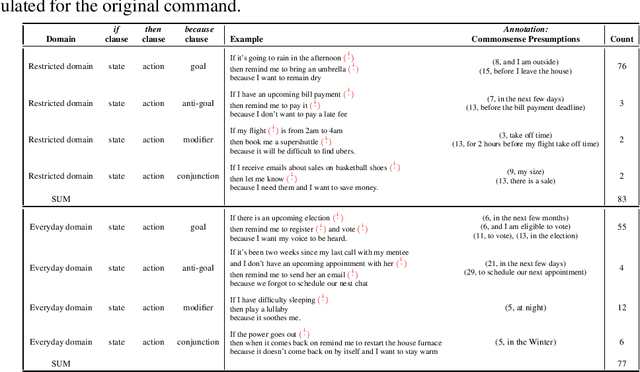
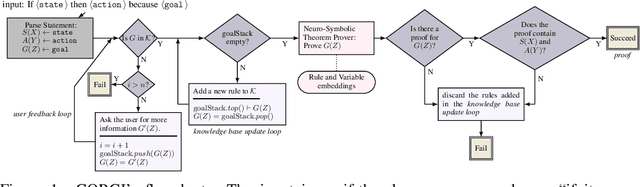
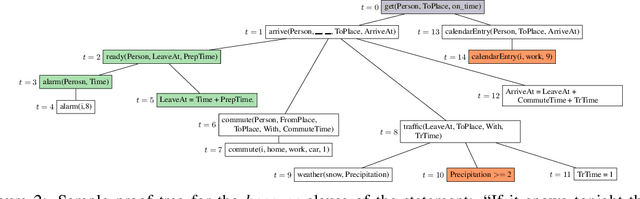

One aspect of human commonsense reasoning is the ability to make presumptions about daily experiences, activities and social interactions with others. We propose a new commonsense reasoning benchmark where the task is to uncover commonsense presumptions implied by imprecisely stated natural language commands in the form of if-then-because statements. For example, in the command "If it snows at night then wake me up early because I don't want to be late for work" the speaker relies on commonsense reasoning of the listener to infer the implicit presumption that it must snow enough to cause traffic slowdowns. Such if-then-because commands are particularly important when users instruct conversational agents. We release a benchmark data set for this task, collected from humans and annotated with commonsense presumptions. We develop a neuro-symbolic theorem prover that extracts multi-hop reasoning chains and apply it to this problem. We further develop an interactive conversational framework that evokes commonsense knowledge from humans for completing reasoning chains.
Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text
Sep 04, 2018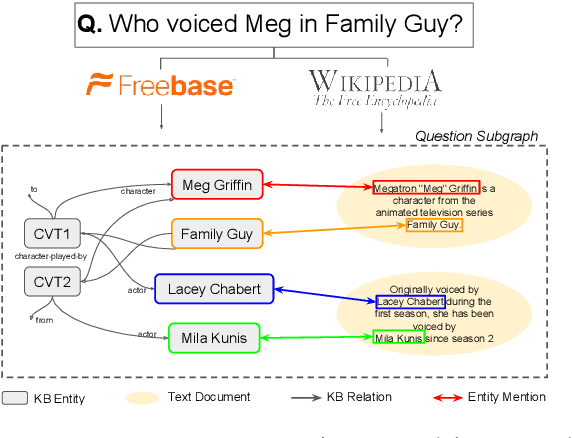

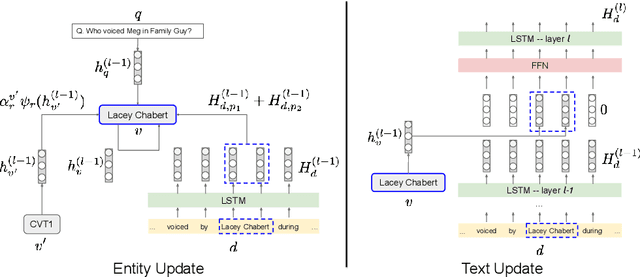
Open Domain Question Answering (QA) is evolving from complex pipelined systems to end-to-end deep neural networks. Specialized neural models have been developed for extracting answers from either text alone or Knowledge Bases (KBs) alone. In this paper we look at a more practical setting, namely QA over the combination of a KB and entity-linked text, which is appropriate when an incomplete KB is available with a large text corpus. Building on recent advances in graph representation learning we propose a novel model, GRAFT-Net, for extracting answers from a question-specific subgraph containing text and KB entities and relations. We construct a suite of benchmark tasks for this problem, varying the difficulty of questions, the amount of training data, and KB completeness. We show that GRAFT-Net is competitive with the state-of-the-art when tested using either KBs or text alone, and vastly outperforms existing methods in the combined setting. Source code is available at https://github.com/OceanskySun/GraftNet .
Quasar: Datasets for Question Answering by Search and Reading
Aug 09, 2017


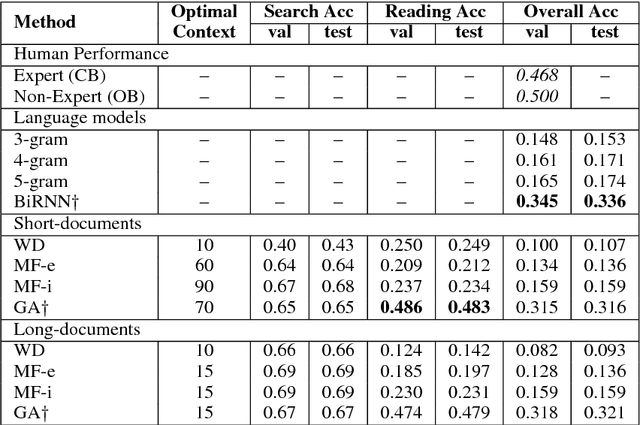
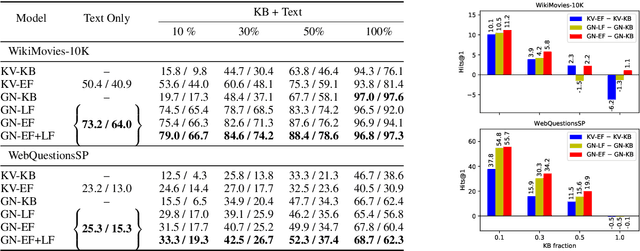
We present two new large-scale datasets aimed at evaluating systems designed to comprehend a natural language query and extract its answer from a large corpus of text. The Quasar-S dataset consists of 37000 cloze-style (fill-in-the-gap) queries constructed from definitions of software entity tags on the popular website Stack Overflow. The posts and comments on the website serve as the background corpus for answering the cloze questions. The Quasar-T dataset consists of 43000 open-domain trivia questions and their answers obtained from various internet sources. ClueWeb09 serves as the background corpus for extracting these answers. We pose these datasets as a challenge for two related subtasks of factoid Question Answering: (1) searching for relevant pieces of text that include the correct answer to a query, and (2) reading the retrieved text to answer the query. We also describe a retrieval system for extracting relevant sentences and documents from the corpus given a query, and include these in the release for researchers wishing to only focus on (2). We evaluate several baselines on both datasets, ranging from simple heuristics to powerful neural models, and show that these lag behind human performance by 16.4% and 32.1% for Quasar-S and -T respectively. The datasets are available at https://github.com/bdhingra/quasar .
Explainable Entity-based Recommendations with Knowledge Graphs
Jul 12, 2017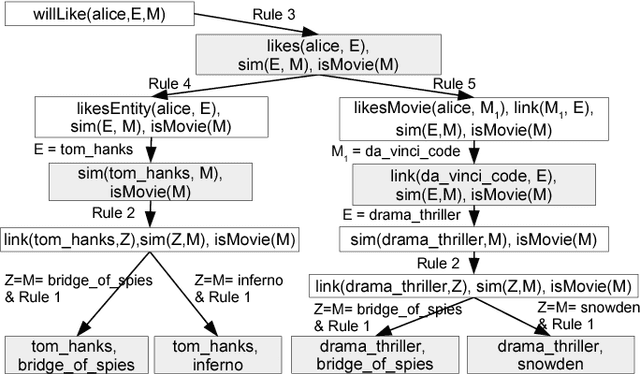
Explainable recommendation is an important task. Many methods have been proposed which generate explanations from the content and reviews written for items. When review text is unavailable, generating explanations is still a hard problem. In this paper, we illustrate how explanations can be generated in such a scenario by leveraging external knowledge in the form of knowledge graphs. Our method jointly ranks items and knowledge graph entities using a Personalized PageRank procedure to produce recommendations together with their explanations.
Bootstrapping Distantly Supervised IE using Joint Learning and Small Well-structured Corpora
Aug 11, 2016
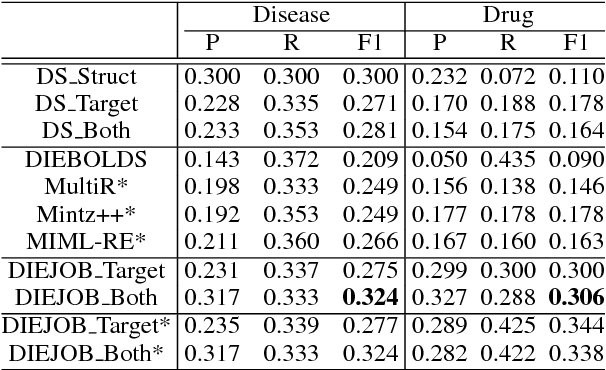
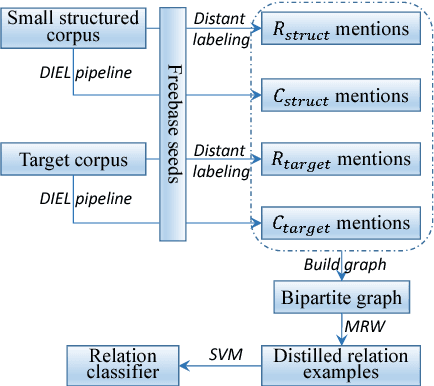
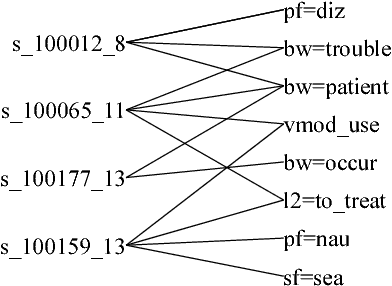
We propose a framework to improve performance of distantly-supervised relation extraction, by jointly learning to solve two related tasks: concept-instance extraction and relation extraction. We combine this with a novel use of document structure: in some small, well-structured corpora, sections can be identified that correspond to relation arguments, and distantly-labeled examples from such sections tend to have good precision. Using these as seeds we extract additional relation examples by applying label propagation on a graph composed of noisy examples extracted from a large unstructured testing corpus. Combined with the soft constraint that concept examples should have the same type as the second argument of the relation, we get significant improvements over several state-of-the-art approaches to distantly-supervised relation extraction.
Efficient Inference and Learning in a Large Knowledge Base: Reasoning with Extracted Information using a Locally Groundable First-Order Probabilistic Logic
Apr 12, 2014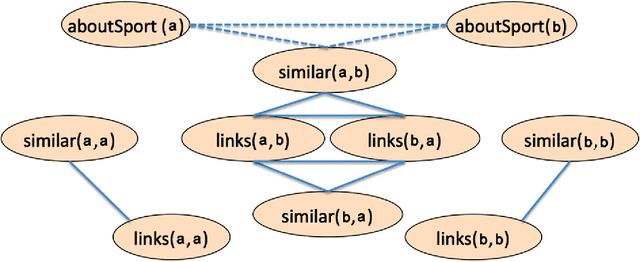

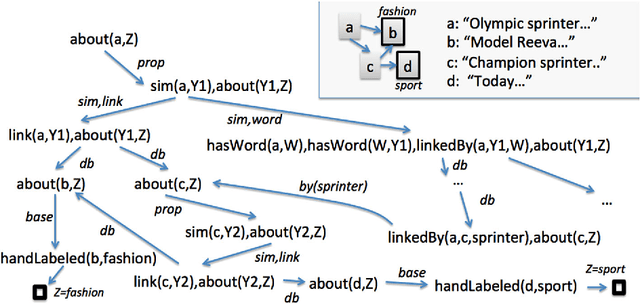

One important challenge for probabilistic logics is reasoning with very large knowledge bases (KBs) of imperfect information, such as those produced by modern web-scale information extraction systems. One scalability problem shared by many probabilistic logics is that answering queries involves "grounding" the query---i.e., mapping it to a propositional representation---and the size of a "grounding" grows with database size. To address this bottleneck, we present a first-order probabilistic language called ProPPR in which that approximate "local groundings" can be constructed in time independent of database size. Technically, ProPPR is an extension to stochastic logic programs (SLPs) that is biased towards short derivations; it is also closely related to an earlier relational learning algorithm called the path ranking algorithm (PRA). We show that the problem of constructing proofs for this logic is related to computation of personalized PageRank (PPR) on a linearized version of the proof space, and using on this connection, we develop a proveably-correct approximate grounding scheme, based on the PageRank-Nibble algorithm. Building on this, we develop a fast and easily-parallelized weight-learning algorithm for ProPPR. In experiments, we show that learning for ProPPR is orders magnitude faster than learning for Markov logic networks; that allowing mutual recursion (joint learning) in KB inference leads to improvements in performance; and that ProPPR can learn weights for a mutually recursive program with hundreds of clauses, which define scores of interrelated predicates, over a KB containing one million entities.
Programming with Personalized PageRank: A Locally Groundable First-Order Probabilistic Logic
May 10, 2013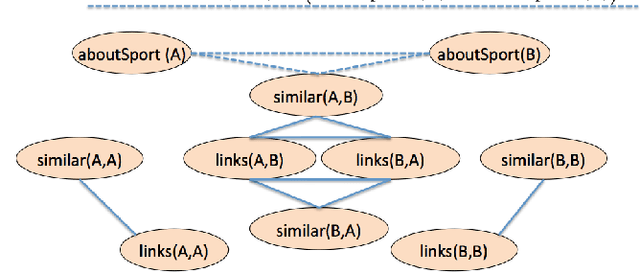
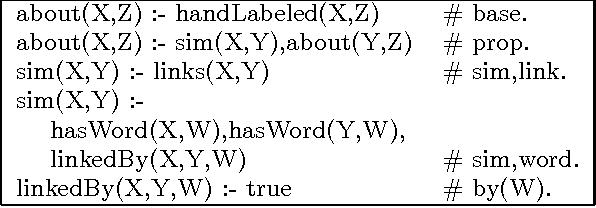
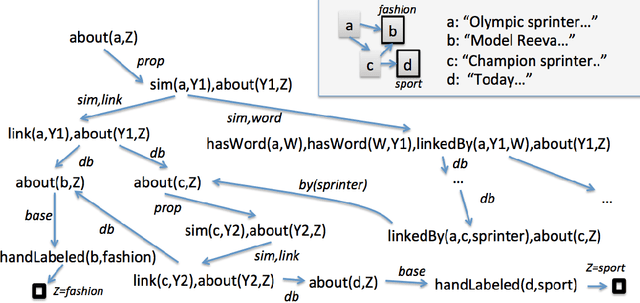
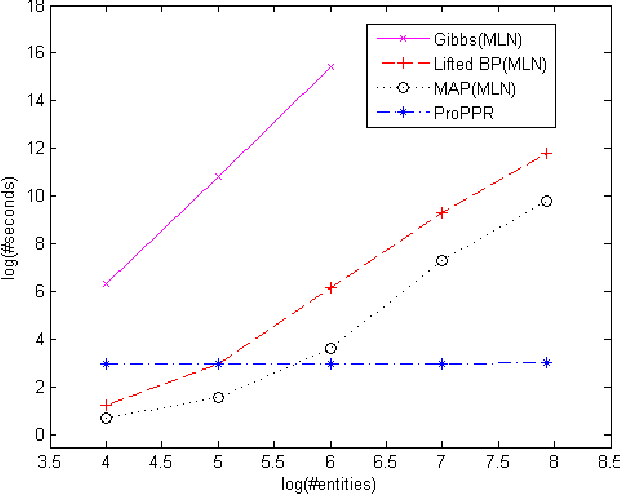
In many probabilistic first-order representation systems, inference is performed by "grounding"---i.e., mapping it to a propositional representation, and then performing propositional inference. With a large database of facts, groundings can be very large, making inference and learning computationally expensive. Here we present a first-order probabilistic language which is well-suited to approximate "local" grounding: every query $Q$ can be approximately grounded with a small graph. The language is an extension of stochastic logic programs where inference is performed by a variant of personalized PageRank. Experimentally, we show that the approach performs well without weight learning on an entity resolution task; that supervised weight-learning improves accuracy; and that grounding time is independent of DB size. We also show that order-of-magnitude speedups are possible by parallelizing learning.