 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Latent Spaces: Assessing the Interpretability of Time Series Foundation Models for Visual Analytics
Apr 26, 2025The present study explores the interpretability of latent spaces produced by time series foundation models, focusing on their potential for visual analysis tasks. Specifically, we evaluate the MOMENT family of models, a set of transformer-based, pre-trained architectures for multivariate time series tasks such as: imputation, prediction, classification, and anomaly detection. We evaluate the capacity of these models on five datasets to capture the underlying structures in time series data within their latent space projection and validate whether fine tuning improves the clarity of the resulting embedding spaces. Notable performance improvements in terms of loss reduction were observed after fine tuning. Visual analysis shows limited improvement in the interpretability of the embeddings, requiring further work. Results suggest that, although Time Series Foundation Models such as MOMENT are robust, their latent spaces may require additional methodological refinements to be adequately interpreted, such as alternative projection techniques, loss functions, or data preprocessing strategies. Despite the limitations of MOMENT, foundation models supose a big reduction in execution time and so a great advance for interactive visual analytics.
Neural Polysynthetic Language Modelling
May 13, 2020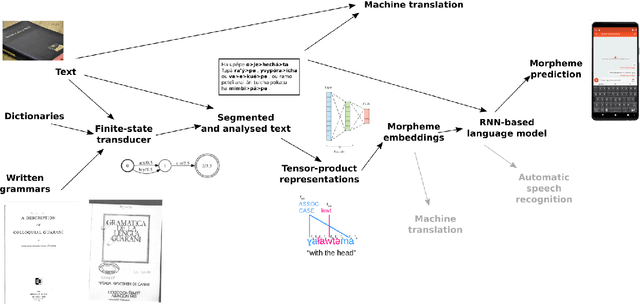

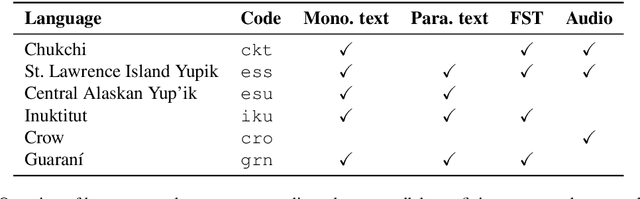
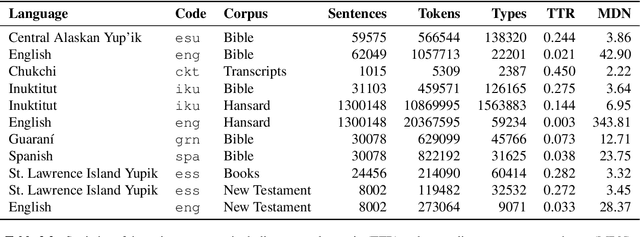
Research in natural language processing commonly assumes that approaches that work well for English and and other widely-used languages are "language agnostic". In high-resource languages, especially those that are analytic, a common approach is to treat morphologically-distinct variants of a common root as completely independent word types. This assumes, that there are limited morphological inflections per root, and that the majority will appear in a large enough corpus, so that the model can adequately learn statistics about each form. Approaches like stemming, lemmatization, or subword segmentation are often used when either of those assumptions do not hold, particularly in the case of synthetic languages like Spanish or Russian that have more inflection than English. In the literature, languages like Finnish or Turkish are held up as extreme examples of complexity that challenge common modelling assumptions. Yet, when considering all of the world's languages, Finnish and Turkish are closer to the average case. When we consider polysynthetic languages (those at the extreme of morphological complexity), approaches like stemming, lemmatization, or subword modelling may not suffice. These languages have very high numbers of hapax legomena, showing the need for appropriate morphological handling of words, without which it is not possible for a model to capture enough word statistics. We examine the current state-of-the-art in language modelling, machine translation, and text prediction for four polysynthetic languages: Guaran\'i, St. Lawrence Island Yupik, Central Alaskan Yupik, and Inuktitut. We then propose a novel framework for language modelling that combines knowledge representations from finite-state morphological analyzers with Tensor Product Representations in order to enable neural language models capable of handling the full range of typologically variant languages.
Bootstrapping Distantly Supervised IE using Joint Learning and Small Well-structured Corpora
Aug 11, 2016
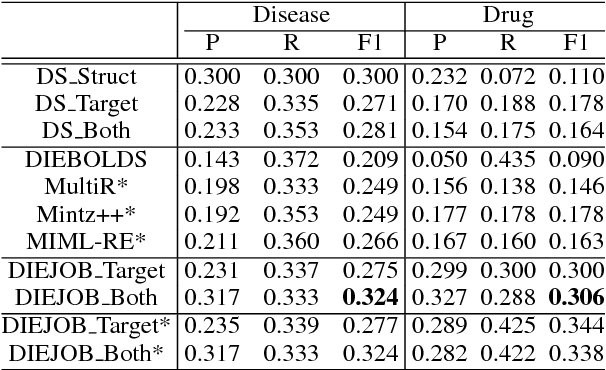
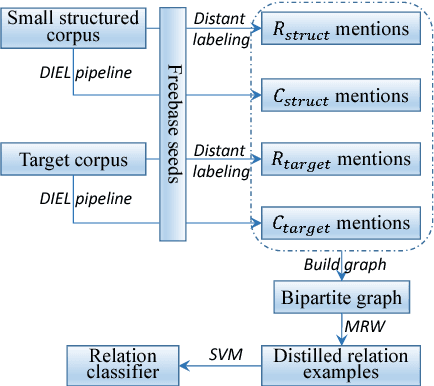
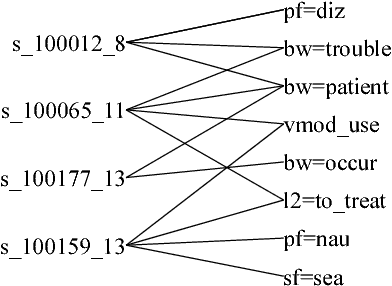
We propose a framework to improve performance of distantly-supervised relation extraction, by jointly learning to solve two related tasks: concept-instance extraction and relation extraction. We combine this with a novel use of document structure: in some small, well-structured corpora, sections can be identified that correspond to relation arguments, and distantly-labeled examples from such sections tend to have good precision. Using these as seeds we extract additional relation examples by applying label propagation on a graph composed of noisy examples extracted from a large unstructured testing corpus. Combined with the soft constraint that concept examples should have the same type as the second argument of the relation, we get significant improvements over several state-of-the-art approaches to distantly-supervised relation extraction.
Active Learning Algorithms for Graphical Model Selection
Apr 07, 2016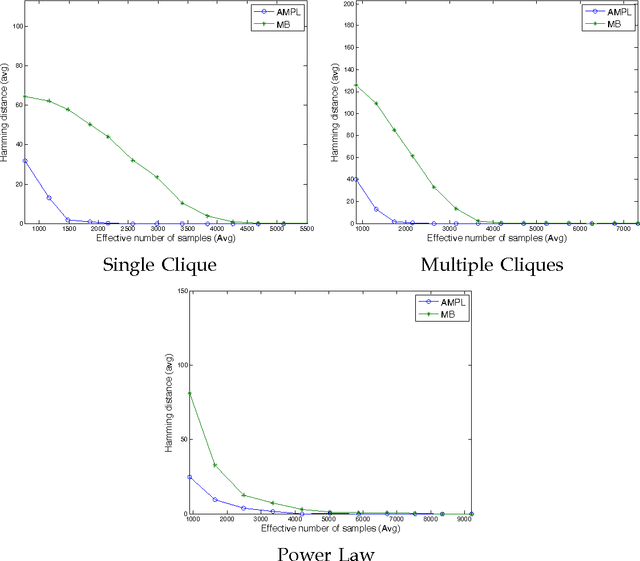
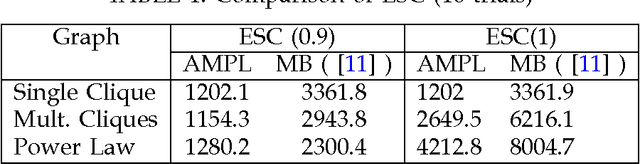
The problem of learning the structure of a high dimensional graphical model from data has received considerable attention in recent years. In many applications such as sensor networks and proteomics it is often expensive to obtain samples from all the variables involved simultaneously. For instance, this might involve the synchronization of a large number of sensors or the tagging of a large number of proteins. To address this important issue, we initiate the study of a novel graphical model selection problem, where the goal is to optimize the total number of scalar samples obtained by allowing the collection of samples from only subsets of the variables. We propose a general paradigm for graphical model selection where feedback is used to guide the sampling to high degree vertices, while obtaining only few samples from the ones with the low degrees. We instantiate this framework with two specific active learning algorithms, one of which makes mild assumptions but is computationally expensive, while the other is more computationally efficient but requires stronger (nevertheless standard) assumptions. Whereas the sample complexity of passive algorithms is typically a function of the maximum degree of the graph, we show that the sample complexity of our algorithms is provable smaller and that it depends on a novel local complexity measure that is akin to the average degree of the graph. We finally demonstrate the efficacy of our framework via simulations.