 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCWoMP: Morpheme Representation Learning for Interlinear Glossing
Mar 18, 2026Interlinear glossed text (IGT) is a standard notation for language documentation which is linguistically rich but laborious to produce manually. Recent automated IGT methods treat glosses as character sequences, neglecting their compositional structure. We propose CWoMP (Contrastive Word-Morpheme Pretraining), which instead treats morphemes as atomic form-meaning units with learned representations. A contrastively trained encoder aligns words-in-context with their constituent morphemes in a shared embedding space; an autoregressive decoder then generates the morpheme sequence by retrieving entries from a mutable lexicon of these embeddings. Predictions are interpretable--grounded in lexicon entries--and users can improve results at inference time by expanding the lexicon without retraining. We evaluate on diverse low-resource languages, showing that CWoMP outperforms existing methods while being significantly more efficient, with particularly strong gains in extremely low-resource settings.
UCxn: Typologically Informed Annotation of Constructions Atop Universal Dependencies
Mar 26, 2024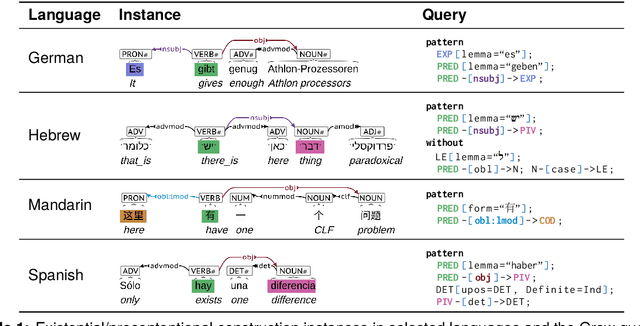
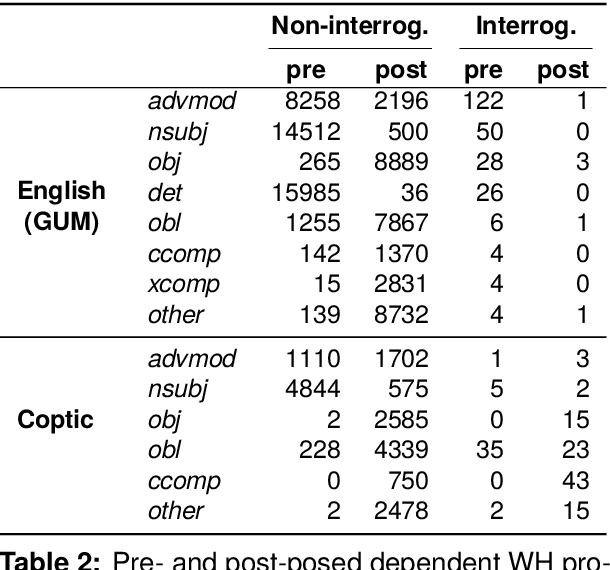
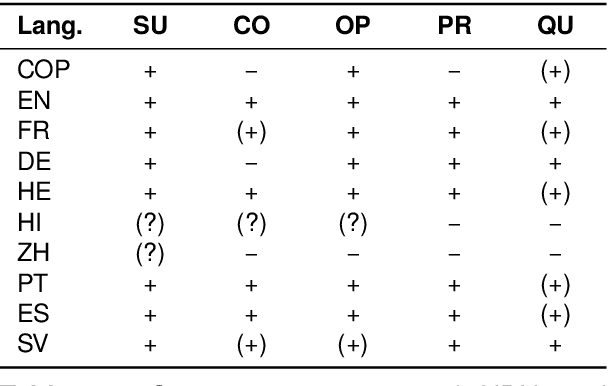
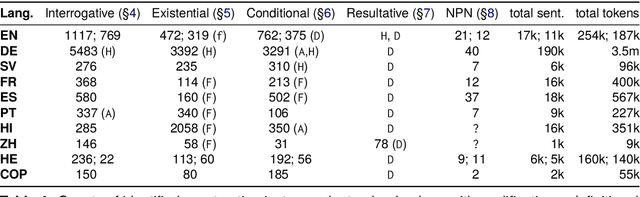
The Universal Dependencies (UD) project has created an invaluable collection of treebanks with contributions in over 140 languages. However, the UD annotations do not tell the full story. Grammatical constructions that convey meaning through a particular combination of several morphosyntactic elements -- for example, interrogative sentences with special markers and/or word orders -- are not labeled holistically. We argue for (i) augmenting UD annotations with a 'UCxn' annotation layer for such meaning-bearing grammatical constructions, and (ii) approaching this in a typologically informed way so that morphosyntactic strategies can be compared across languages. As a case study, we consider five construction families in ten languages, identifying instances of each construction in UD treebanks through the use of morphosyntactic patterns. In addition to findings regarding these particular constructions, our study yields important insights on methodology for describing and identifying constructions in language-general and language-particular ways, and lays the foundation for future constructional enrichment of UD treebanks.
Constructions Are So Difficult That Even Large Language Models Get Them Right for the Wrong Reasons
Mar 26, 2024
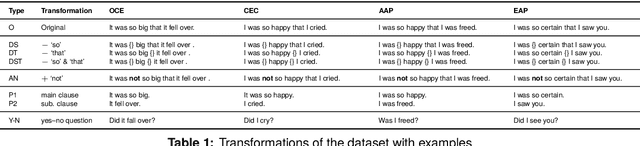
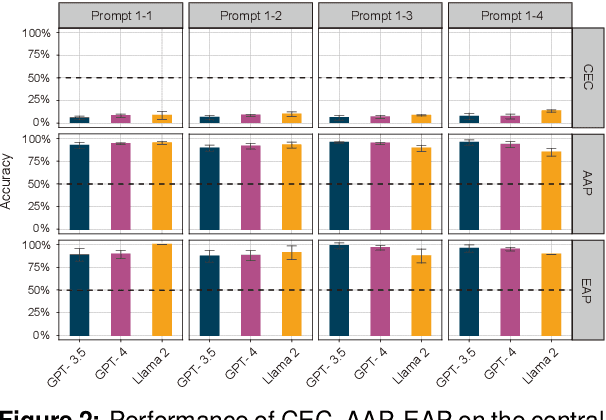
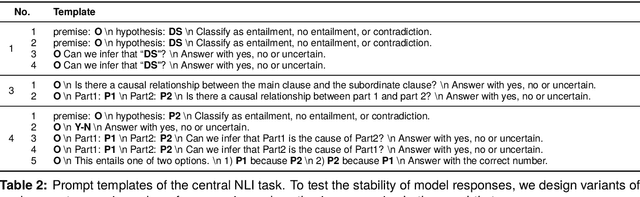
In this paper, we make a contribution that can be understood from two perspectives: from an NLP perspective, we introduce a small challenge dataset for NLI with large lexical overlap, which minimises the possibility of models discerning entailment solely based on token distinctions, and show that GPT-4 and Llama 2 fail it with strong bias. We then create further challenging sub-tasks in an effort to explain this failure. From a Computational Linguistics perspective, we identify a group of constructions with three classes of adjectives which cannot be distinguished by surface features. This enables us to probe for LLM's understanding of these constructions in various ways, and we find that they fail in a variety of ways to distinguish between them, suggesting that they don't adequately represent their meaning or capture the lexical properties of phrasal heads.
Wav2Gloss: Generating Interlinear Glossed Text from Speech
Mar 19, 2024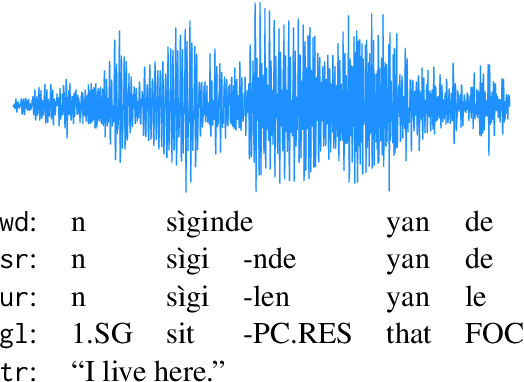
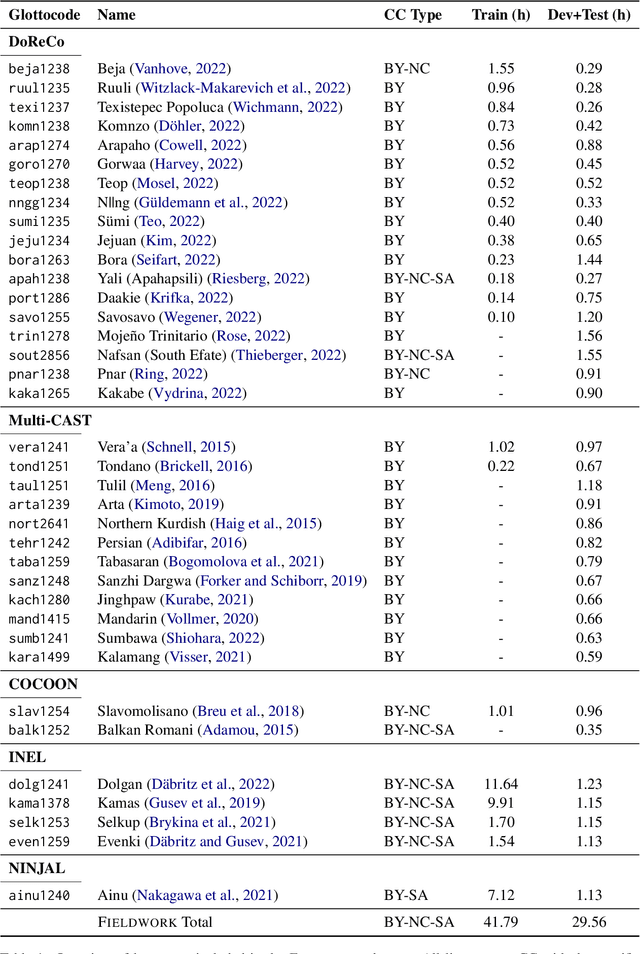
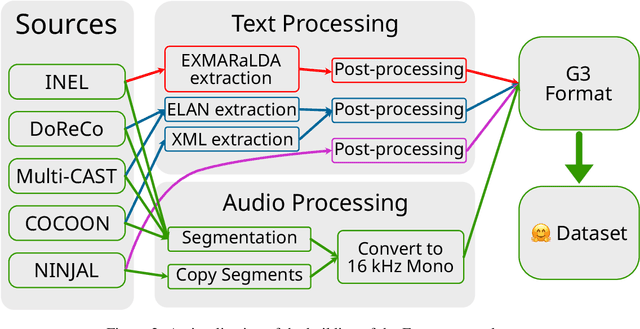
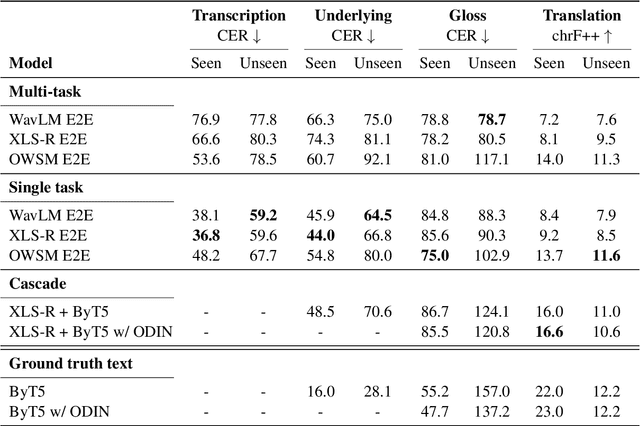
Thousands of the world's languages are in danger of extinction--a tremendous threat to cultural identities and human language diversity. Interlinear Glossed Text (IGT) is a form of linguistic annotation that can support documentation and resource creation for these languages' communities. IGT typically consists of (1) transcriptions, (2) morphological segmentation, (3) glosses, and (4) free translations to a majority language. We propose Wav2Gloss: a task to extract these four annotation components automatically from speech, and introduce the first dataset to this end, Fieldwork: a corpus of speech with all these annotations covering 37 languages with standard formatting and train/dev/test splits. We compare end-to-end and cascaded Wav2Gloss methods, with analysis suggesting that pre-trained decoders assist with translation and glossing, that multi-task and multilingual approaches are underperformant, and that end-to-end systems perform better than cascaded systems, despite the text-only systems' advantages. We provide benchmarks to lay the ground work for future research on IGT generation from speech.
GlossLM: Multilingual Pretraining for Low-Resource Interlinear Glossing
Mar 11, 2024



A key aspect of language documentation is the creation of annotated text in a format such as interlinear glossed text (IGT), which captures fine-grained morphosyntactic analyses in a morpheme-by-morpheme format. Prior work has explored methods to automatically generate IGT in order to reduce the time cost of language analysis. However, many languages (particularly those requiring preservation) lack sufficient IGT data to train effective models, and crosslingual transfer has been proposed as a method to overcome this limitation. We compile the largest existing corpus of IGT data from a variety of sources, covering over 450k examples across 1.8k languages, to enable research on crosslingual transfer and IGT generation. Then, we pretrain a large multilingual model on a portion of this corpus, and further finetune it to specific languages. Our model is competitive with state-of-the-art methods for segmented data and large monolingual datasets. Meanwhile, our model outperforms SOTA models on unsegmented text and small corpora by up to 6.6% morpheme accuracy, demonstrating the effectiveness of crosslingual transfer for low-resource languages.
Syntax and Semantics Meet in the "Middle": Probing the Syntax-Semantics Interface of LMs Through Agentivity
May 29, 2023



Recent advances in large language models have prompted researchers to examine their abilities across a variety of linguistic tasks, but little has been done to investigate how models handle the interactions in meaning across words and larger syntactic forms -- i.e. phenomena at the intersection of syntax and semantics. We present the semantic notion of agentivity as a case study for probing such interactions. We created a novel evaluation dataset by utilitizing the unique linguistic properties of a subset of optionally transitive English verbs. This dataset was used to prompt varying sizes of three model classes to see if they are sensitive to agentivity at the lexical level, and if they can appropriately employ these word-level priors given a specific syntactic context. Overall, GPT-3 text-davinci-003 performs extremely well across all experiments, outperforming all other models tested by far. In fact, the results are even better correlated with human judgements than both syntactic and semantic corpus statistics. This suggests that LMs may potentially serve as more useful tools for linguistic annotation, theory testing, and discovery than select corpora for certain tasks.
Construction Grammar Provides Unique Insight into Neural Language Models
Feb 04, 2023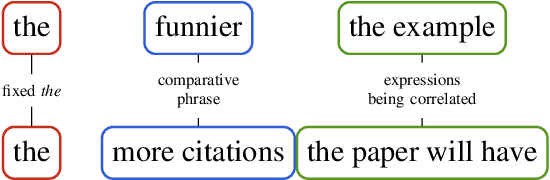



Construction Grammar (CxG) has recently been used as the basis for probing studies that have investigated the performance of large pretrained language models (PLMs) with respect to the structure and meaning of constructions. In this position paper, we make suggestions for the continuation and augmentation of this line of research. We look at probing methodology that was not designed with CxG in mind, as well as probing methodology that was designed for specific constructions. We analyse selected previous work in detail, and provide our view of the most important challenges and research questions that this promising new field faces.
Neural Polysynthetic Language Modelling
May 13, 2020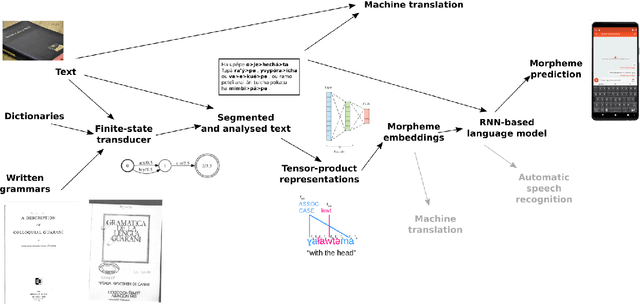

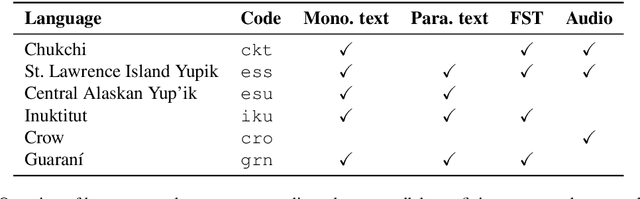
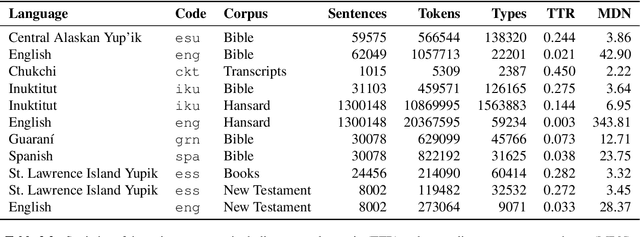
Research in natural language processing commonly assumes that approaches that work well for English and and other widely-used languages are "language agnostic". In high-resource languages, especially those that are analytic, a common approach is to treat morphologically-distinct variants of a common root as completely independent word types. This assumes, that there are limited morphological inflections per root, and that the majority will appear in a large enough corpus, so that the model can adequately learn statistics about each form. Approaches like stemming, lemmatization, or subword segmentation are often used when either of those assumptions do not hold, particularly in the case of synthetic languages like Spanish or Russian that have more inflection than English. In the literature, languages like Finnish or Turkish are held up as extreme examples of complexity that challenge common modelling assumptions. Yet, when considering all of the world's languages, Finnish and Turkish are closer to the average case. When we consider polysynthetic languages (those at the extreme of morphological complexity), approaches like stemming, lemmatization, or subword modelling may not suffice. These languages have very high numbers of hapax legomena, showing the need for appropriate morphological handling of words, without which it is not possible for a model to capture enough word statistics. We examine the current state-of-the-art in language modelling, machine translation, and text prediction for four polysynthetic languages: Guaran\'i, St. Lawrence Island Yupik, Central Alaskan Yupik, and Inuktitut. We then propose a novel framework for language modelling that combines knowledge representations from finite-state morphological analyzers with Tensor Product Representations in order to enable neural language models capable of handling the full range of typologically variant languages.
A Resource for Computational Experiments on Mapudungun
Dec 04, 2019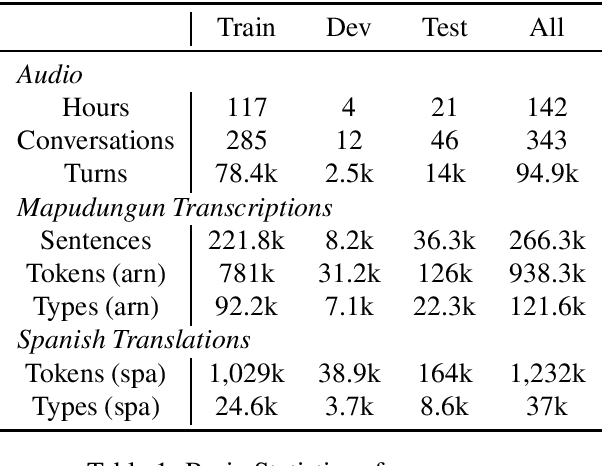

We present a resource for computational experiments on Mapudungun, a polysynthetic indigenous language spoken in Chile with upwards of 200 thousand speakers. We provide 142 hours of culturally significant conversations in the domain of medical treatment. The conversations are fully transcribed and translated into Spanish. The transcriptions also include annotations for code-switching and non-standard pronunciations. We also provide baseline results on three core NLP tasks: speech recognition, speech synthesis, and machine translation between Spanish and Mapudungun. We further explore other applications for which the corpus will be suitable, including the study of code-switching, historical orthography change, linguistic structure, and sociological and anthropological studies.
Low-Resource Machine Translation using Interlinear Glosses
Nov 07, 2019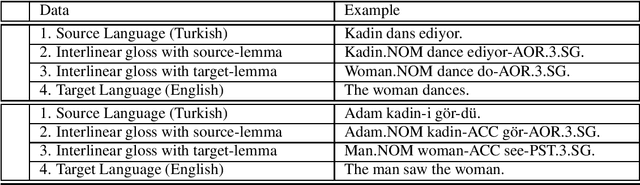

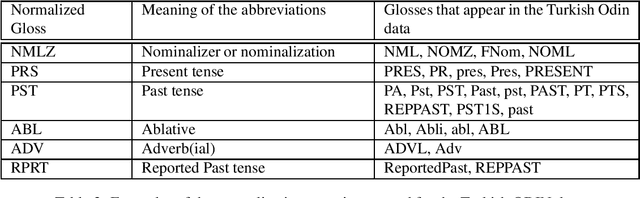
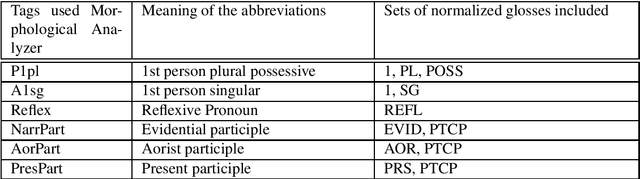
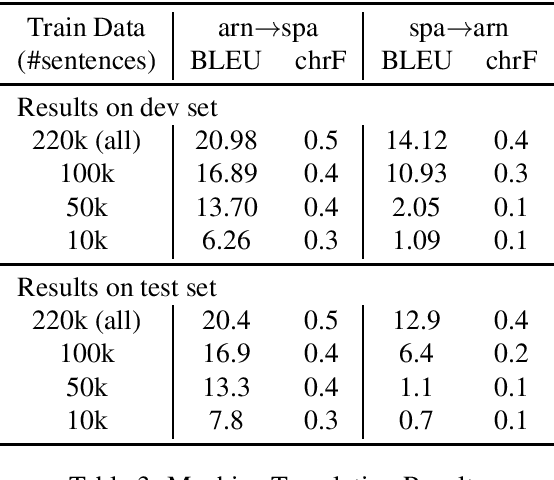
Neural Machine Translation (NMT) does not handle low-resource translation well because NMT is data-hungry and low-resource languages, by their nature, have limited parallel data. Many low-resource languages are morphologically rich, which complicates matters further by increasing data sparsity. However, a good linguist is capable of building a morphological analyzer in far fewer hours than it would take to collect and translate the amount of parallel data needed for conventional NMT. We combine the benefits of both NMT and linguistic information in our work. We use morphological analyzer to automatically generate interlinear glosses with dictionary or parallel data, and translate the source text to interlinear gloss as an interlingua representation, and finally translate into the target text using NMT trained on the ODIN dataset that includes a large collection of interlinear glosses and their corresponding target translations. Our result for translating from the interlinear gloss to the target text using the entire ODIN dataset achieves a BLEU score of 35.07. And our qualitative results show positive findings in a low-resource scenario of Turkish-English translation using 865 lines of training data. Our translation system yield better results than training NMT directly from the source language to the target language in a constrained-data setting, and is helpful to produce translation with sufficiently good content and fluency when data is scarce.