 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Unknown: Conditional Evidence Decoupling for Unknown Rejection
Jun 26, 2024In this paper, we focus on training an open-set object detector under the condition of scarce training samples, which should distinguish the known and unknown categories. Under this challenging scenario, the decision boundaries of unknowns are difficult to learn and often ambiguous. To mitigate this issue, we develop a novel open-set object detection framework, which delves into conditional evidence decoupling for the unknown rejection. Specifically, we select pseudo-unknown samples by leveraging the discrepancy in attribution gradients between known and unknown classes, alleviating the inadequate unknown distribution coverage of training data. Subsequently, we propose a Conditional Evidence Decoupling Loss (CEDL) based on Evidential Deep Learning (EDL) theory, which decouples known and unknown properties in pseudo-unknown samples to learn distinct knowledge, enhancing separability between knowns and unknowns. Additionally, we propose an Abnormality Calibration Loss (ACL), which serves as a regularization term to adjust the output probability distribution, establishing robust decision boundaries for the unknown rejection. Our method has achieved the superiority performance over previous state-of-the-art approaches, improving the mean recall of unknown class by 7.24% across all shots in VOC10-5-5 dataset settings and 1.38% in VOC-COCO dataset settings. The code is available via https://github.com/zjzwzw/CED-FOOD.
Massively Multilingual Text Translation For Low-Resource Languages
Jan 29, 2024

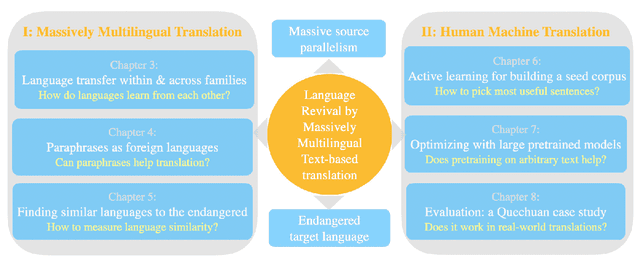
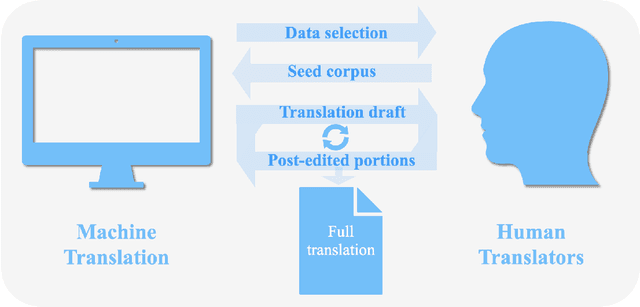
Translation into severely low-resource languages has both the cultural goal of saving and reviving those languages and the humanitarian goal of assisting the everyday needs of local communities that are accelerated by the recent COVID-19 pandemic. In many humanitarian efforts, translation into severely low-resource languages often does not require a universal translation engine, but a dedicated text-specific translation engine. For example, healthcare records, hygienic procedures, government communication, emergency procedures and religious texts are all limited texts. While generic translation engines for all languages do not exist, translation of multilingually known limited texts into new, low-resource languages may be possible and reduce human translation effort. We attempt to leverage translation resources from rich-resource languages to efficiently produce best possible translation quality for well known texts, which are available in multiple languages, in a new, low-resource language. To reach this goal, we argue that in translating a closed text into low-resource languages, generalization to out-of-domain texts is not necessary, but generalization to new languages is. Performance gain comes from massive source parallelism by careful choice of close-by language families, style-consistent corpus-level paraphrases within the same language and strategic adaptation of existing large pretrained multilingual models to the domain first and then to the language. Such performance gain makes it possible for machine translation systems to collaborate with human translators to expedite the translation process into new, low-resource languages.
Train Global, Tailor Local: Minimalist Multilingual Translation into Endangered Languages
May 05, 2023In many humanitarian scenarios, translation into severely low resource languages often does not require a universal translation engine, but a dedicated text-specific translation engine. For example, healthcare records, hygienic procedures, government communication, emergency procedures and religious texts are all limited texts. While generic translation engines for all languages do not exist, translation of multilingually known limited texts into new, endangered languages may be possible and reduce human translation effort. We attempt to leverage translation resources from many rich resource languages to efficiently produce best possible translation quality for a well known text, which is available in multiple languages, in a new, severely low resource language. We examine two approaches: 1. best selection of seed sentences to jump start translations in a new language in view of best generalization to the remainder of a larger targeted text(s), and 2. we adapt large general multilingual translation engines from many other languages to focus on a specific text in a new, unknown language. We find that adapting large pretrained multilingual models to the domain/text first and then to the severely low resource language works best. If we also select a best set of seed sentences, we can improve average chrF performance on new test languages from a baseline of 21.9 to 50.7, while reducing the number of seed sentences to only around 1,000 in the new, unknown language.
QR-CLIP: Introducing Explicit Open-World Knowledge for Location and Time Reasoning
Feb 02, 2023Daily images may convey abstract meanings that require us to memorize and infer profound information from them. To encourage such human-like reasoning, in this work, we teach machines to predict where and when it was taken rather than performing basic tasks like traditional segmentation or classification. Inspired by Horn's QR theory, we designed a novel QR-CLIP model consisting of two components: 1) the Quantity module first retrospects more open-world knowledge as the candidate language inputs; 2) the Relevance module carefully estimates vision and language cues and infers the location and time. Experiments show our QR-CLIP's effectiveness, and it outperforms the previous SOTA on each task by an average of about 10% and 130% relative lift in terms of location and time reasoning. This study lays a technical foundation for location and time reasoning and suggests that effectively introducing open-world knowledge is one of the panaceas for the tasks.
Towards Few-Shot Open-Set Object Detection
Oct 28, 2022



Open-set object detection (OSOD) aims to detect the known categories and identify unknown objects in a dynamic world, which has achieved significant attentions. However, previous approaches only consider this problem in data-abundant conditions. We seek a solution for few-shot open-set object detection (FSOSOD), which aims to quickly train a detector based on few samples while detecting all known classes and identifying unknown classes. The main challenge for this task is that few training samples tend to overfit on the known classes, and lead to poor open-set performance. We propose a new FSOSOD algorithm to tackle this issue, named FOOD, which contains a novel class dropout cosine classifier (CDCC) and a novel unknown decoupling learner (UDL). To prevent over-fitting, CDCC randomly inactivates parts of the normalized neurons for the logit prediction of all classes, and then decreases the co-adaptability between the class and its neighbors. Alongside, UDL decouples training the unknown class and enables the model to form a compact unknown decision boundary. Thus, the unknown objects can be identified with a confidence probability without any pseudo-unknown samples for training. We compare our method with several state-of-the-art OSOD methods in few-shot scenes and observe that our method improves the recall of unknown classes by 5%-9% across all shots in VOC-COCO dataset setting.
Active Learning for Massively Parallel Translation of Constrained Text into Low Resource Languages
Aug 16, 2021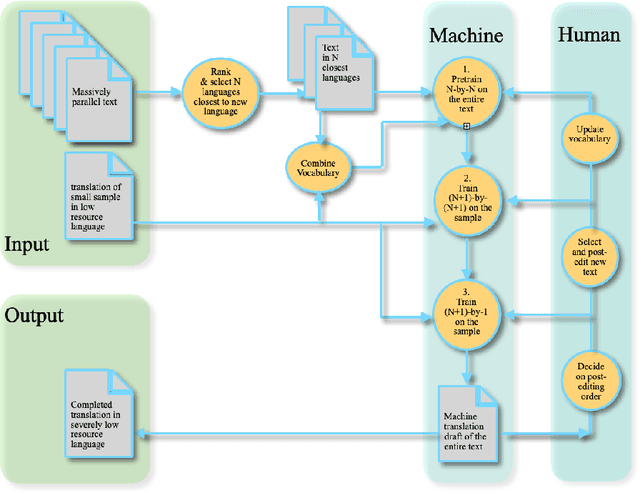
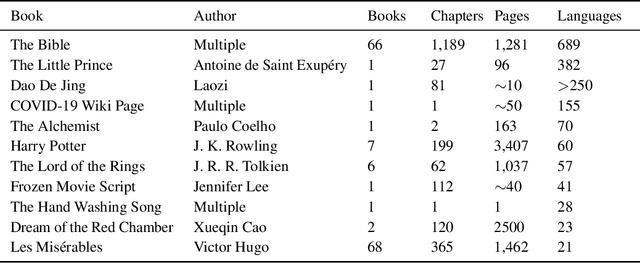
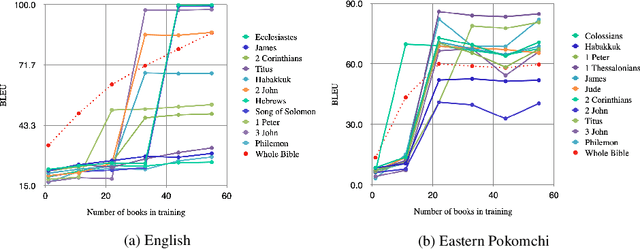
We translate a closed text that is known in advance and available in many languages into a new and severely low resource language. Most human translation efforts adopt a portion-based approach to translate consecutive pages/chapters in order, which may not suit machine translation. We compare the portion-based approach that optimizes coherence of the text locally with the random sampling approach that increases coverage of the text globally. Our results show that the random sampling approach performs better. When training on a seed corpus of ~1,000 lines from the Bible and testing on the rest of the Bible (~30,000 lines), random sampling gives a performance gain of +11.0 BLEU using English as a simulated low resource language, and +4.9 BLEU using Eastern Pokomchi, a Mayan language. Furthermore, we compare three ways of updating machine translation models with increasing amount of human post-edited data through iterations. We find that adding newly post-edited data to training after vocabulary update without self-supervision performs the best. We propose an algorithm for human and machine to work together seamlessly to translate a closed text into a severely low resource language.
Family of Origin and Family of Choice: Massively Parallel Lexiconized Iterative Pretraining for Severely Low Resource Machine Translation
Apr 28, 2021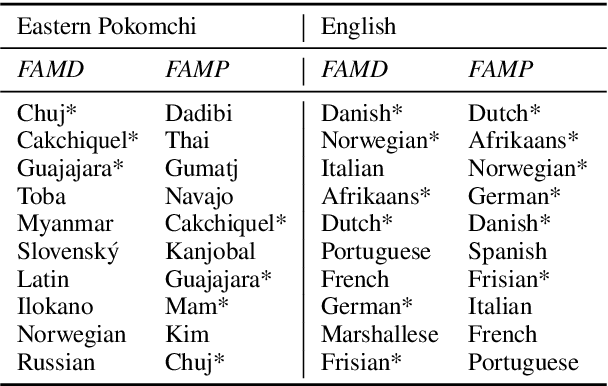


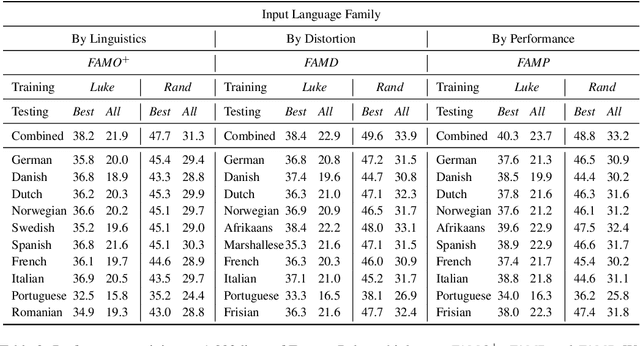
We translate a closed text that is known in advance into a severely low resource language by leveraging massive source parallelism. In other words, given a text in 124 source languages, we translate it into a severely low resource language using only ~1,000 lines of low resource data without any external help. Firstly, we propose a systematic method to rank and choose source languages that are close to the low resource language. We call the linguistic definition of language family Family of Origin (FAMO), and we call the empirical definition of higher-ranked languages using our metrics Family of Choice (FAMC). Secondly, we build an Iteratively Pretrained Multilingual Order-preserving Lexiconized Transformer (IPML) to train on ~1,000 lines (~3.5%) of low resource data. To translate named entities correctly, we build a massive lexicon table for 2,939 Bible named entities in 124 source languages, and include many that occur once and covers more than 66 severely low resource languages. Moreover, we also build a novel method of combining translations from different source languages into one. Using English as a hypothetical low resource language, we get a +23.9 BLEU increase over a multilingual baseline, and a +10.3 BLEU increase over our asymmetric baseline in the Bible dataset. We get a 42.8 BLEU score for Portuguese-English translation on the medical EMEA dataset. We also have good results for a real severely low resource Mayan language, Eastern Pokomchi.
SIGAN: A Novel Image Generation Method for Solar Cell Defect Segmentation and Augmentation
Apr 11, 2021
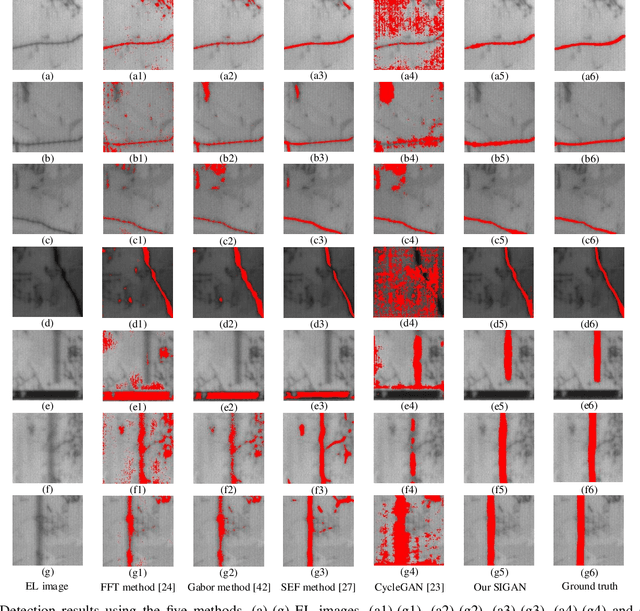
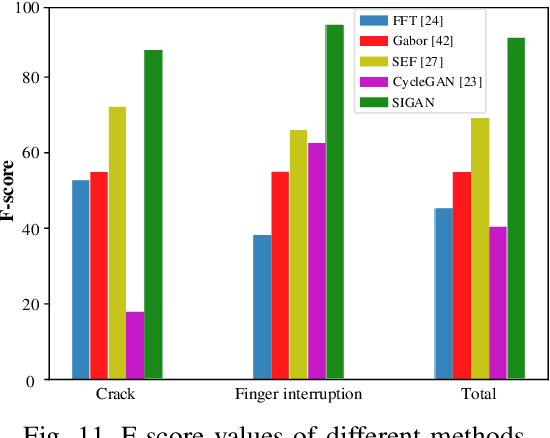
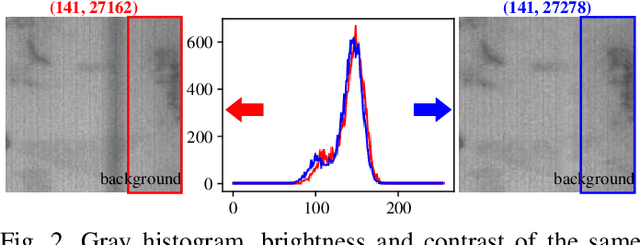
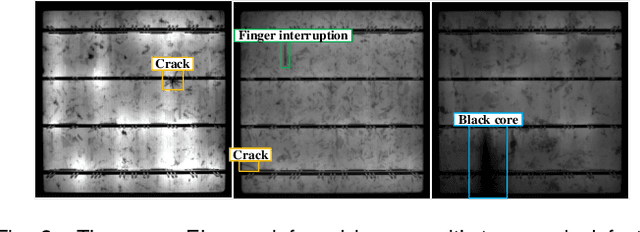
Solar cell electroluminescence (EL) defect segmentation is an interesting and challenging topic. Many methods have been proposed for EL defect detection, but these methods are still unsatisfactory due to the diversity of the defect and background. In this paper, we provide a new idea of using generative adversarial network (GAN) for defect segmentation. Firstly, the GAN-based method removes the defect region in the input defective image to get a defect-free image, while keeping the background almost unchanged. Then, the subtracted image is obtained by making difference between the defective input image with the generated defect-free image. Finally, the defect region can be segmented through thresholding the subtracted image. To keep the background unchanged before and after image generation, we propose a novel strong identity GAN (SIGAN), which adopts a novel strong identity loss to constraint the background consistency. The SIGAN can be used not only for defect segmentation, but also small-samples defective dataset augmentation. Moreover, we release a new solar cell EL image dataset named as EL-2019, which includes three types of images: crack, finger interruption and defect-free. Experiments on EL-2019 dataset show that the proposed method achieves 90.34% F-score, which outperforms many state-of-the-art methods in terms of solar cell defects segmentation results.
BAF-Detector: An Efficient CNN-Based Detector for Photovoltaic Solar Cell Defect Detection
Dec 19, 2020
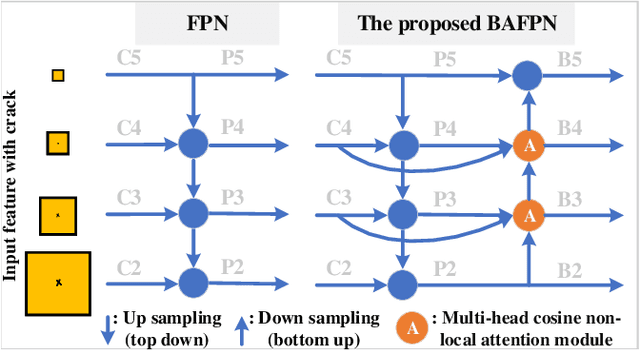
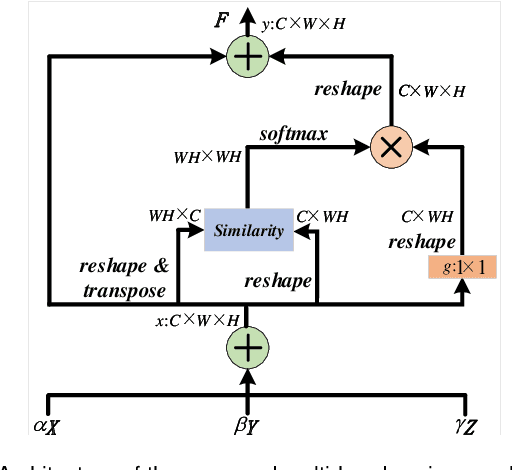
The multi-scale defect detection for solar cell electroluminescence (EL) images is a challenging task, due to the feature vanishing as network deepens. To address this problem, a novel Bidirectional Attention Feature Pyramid Network (BAFPN) is designed by combining the novel multi-head cosine non-local attention module with top-down and bottom-up feature pyramid networks through bidirectional cross-scale connections, which can make all layers of the pyramid share similar semantic features. In multi-head cosine non-local attention module, cosine function is applied to compute the similarity matrix of the input features. Furthermore, a novel object detector is proposed, called BAF-Detector, which embeds BAFPN into Region Proposal Network (RPN) in Faster RCNN+FPN to improve the detection effect of multi-scale defects in solar cell EL images. Finally, some experimental results on a large-scale EL dataset including 3629 images, 2129 of which are defective, show that the proposed method performs much better than other methods in terms of multi-scale defects classification and detection results in raw solar cell EL images.
Object-aware Feature Aggregation for Video Object Detection
Oct 23, 2020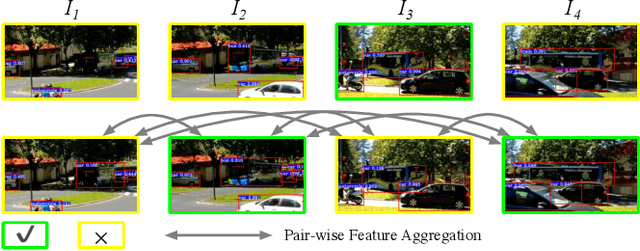

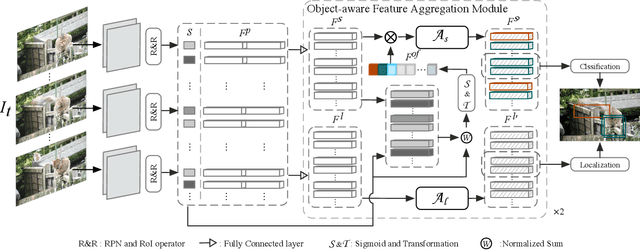
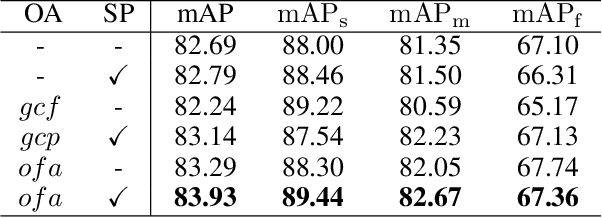
We present an Object-aware Feature Aggregation (OFA) module for video object detection (VID). Our approach is motivated by the intriguing property that video-level object-aware knowledge can be employed as a powerful semantic prior to help object recognition. As a consequence, augmenting features with such prior knowledge can effectively improve the classification and localization performance. To make features get access to more content about the whole video, we first capture the object-aware knowledge of proposals and incorporate such knowledge with the well-established pair-wise contexts. With extensive experimental results on the ImageNet VID dataset, our approach demonstrates the effectiveness of object-aware knowledge with the superior performance of 83.93% and 86.09% mAP with ResNet-101 and ResNeXt-101, respectively. When further equipped with Sequence DIoU NMS, we obtain the best-reported mAP of 85.07% and 86.88% upon the paper submitted. The code to reproduce our results will be released after acceptance.