 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-aware Symmetric Alignment for Text-guided Medical Image Segmentation
Dec 28, 2025Text-guided Medical Image Segmentation has shown considerable promise for medical image segmentation, with rich clinical text serving as an effective supplement for scarce data. However, current methods have two key bottlenecks. On one hand, they struggle to process diagnostic and descriptive texts simultaneously, making it difficult to identify lesions and establish associations with image regions. On the other hand, existing approaches focus on lesions description and fail to capture positional constraints, leading to critical deviations. Specifically, with the text "in the left lower lung", the segmentation results may incorrectly cover both sides of the lung. To address the limitations, we propose the Spatial-aware Symmetric Alignment (SSA) framework to enhance the capacity of referring hybrid medical texts consisting of locational, descriptive, and diagnostic information. Specifically, we propose symmetric optimal transport alignment mechanism to strengthen the associations between image regions and multiple relevant expressions, which establishes bi-directional fine-grained multimodal correspondences. In addition, we devise a composite directional guidance strategy that explicitly introduces spatial constraints in the text by constructing region-level guidance masks. Extensive experiments on public benchmarks demonstrate that SSA achieves state-of-the-art (SOTA) performance, particularly in accurately segmenting lesions characterized by spatial relational constraints.
Frequency Domain Image Translation: More Photo-realistic, Better Identity-preserving
Dec 01, 2020
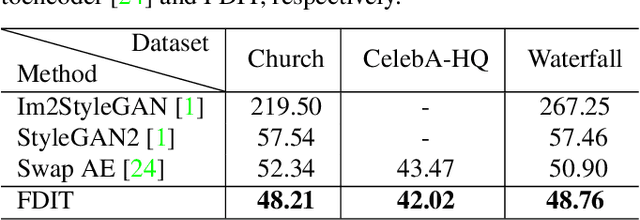
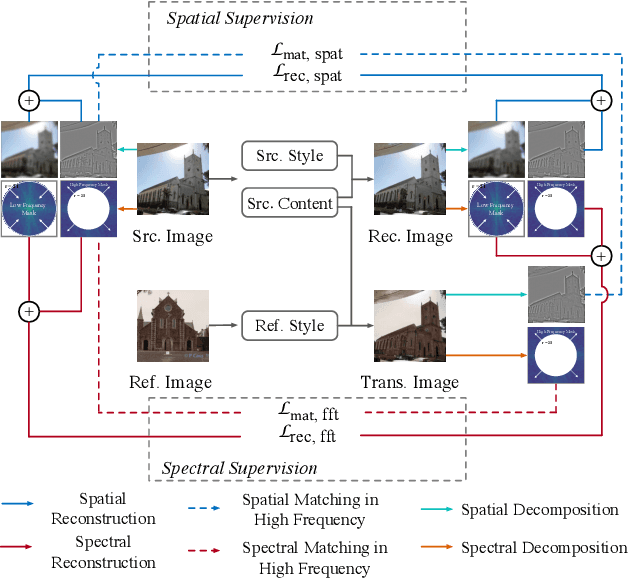
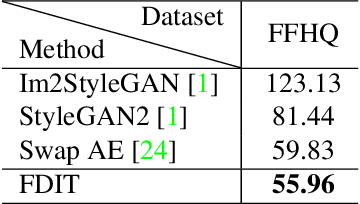
Image-to-image translation aims at translating a particular style of an image to another. The synthesized images can be more photo-realistic and identity-preserving by decomposing the image into content and style in a disentangled manner. While existing models focus on designing specialized network architecture to separate the two components, this paper investigates how to explicitly constrain the content and style statistics of images. We achieve this goal by transforming the input image into high frequency and low frequency information, which correspond to the content and style, respectively. We regulate the frequency distribution from two aspects: a) a spatial level restriction to locally restrict the frequency distribution of images; b) a spectral level regulation to enhance the global consistency among images. On multiple datasets we show that the proposed approach consistently leads to significant improvements on top of various state-of-the-art image translation models.
Object-aware Feature Aggregation for Video Object Detection
Oct 23, 2020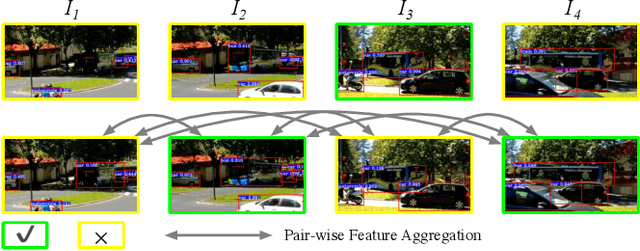

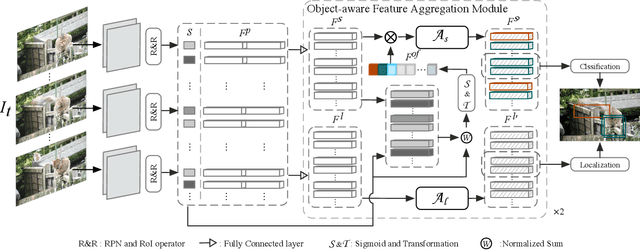
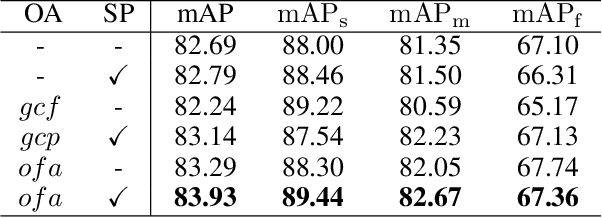
We present an Object-aware Feature Aggregation (OFA) module for video object detection (VID). Our approach is motivated by the intriguing property that video-level object-aware knowledge can be employed as a powerful semantic prior to help object recognition. As a consequence, augmenting features with such prior knowledge can effectively improve the classification and localization performance. To make features get access to more content about the whole video, we first capture the object-aware knowledge of proposals and incorporate such knowledge with the well-established pair-wise contexts. With extensive experimental results on the ImageNet VID dataset, our approach demonstrates the effectiveness of object-aware knowledge with the superior performance of 83.93% and 86.09% mAP with ResNet-101 and ResNeXt-101, respectively. When further equipped with Sequence DIoU NMS, we obtain the best-reported mAP of 85.07% and 86.88% upon the paper submitted. The code to reproduce our results will be released after acceptance.
Gated Path Selection Network for Semantic Segmentation
Jan 19, 2020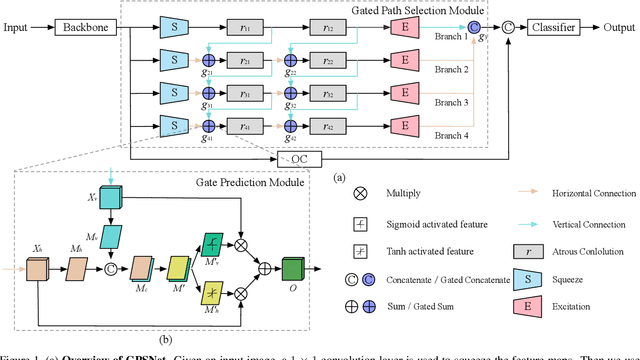
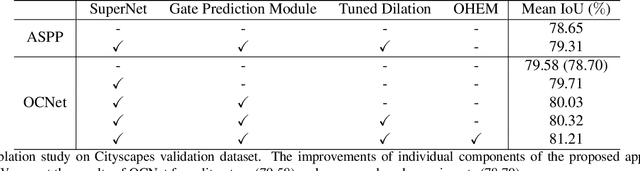
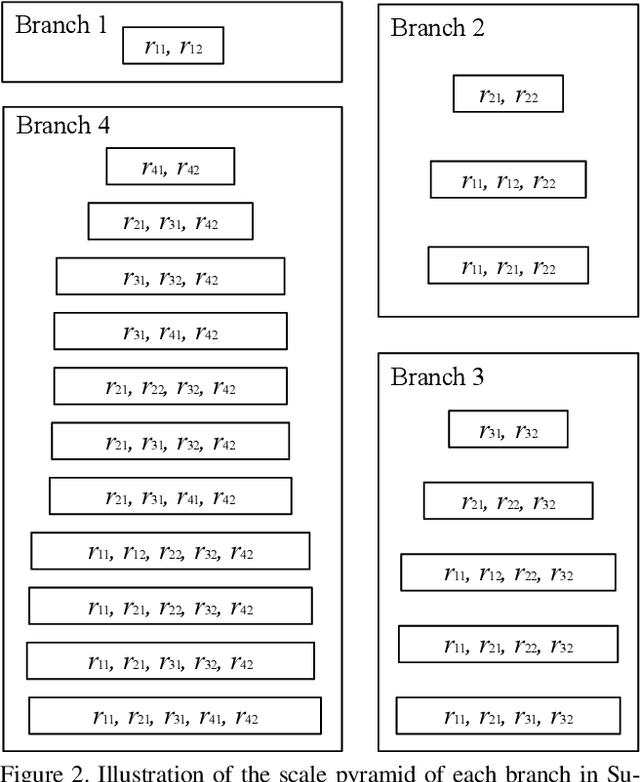
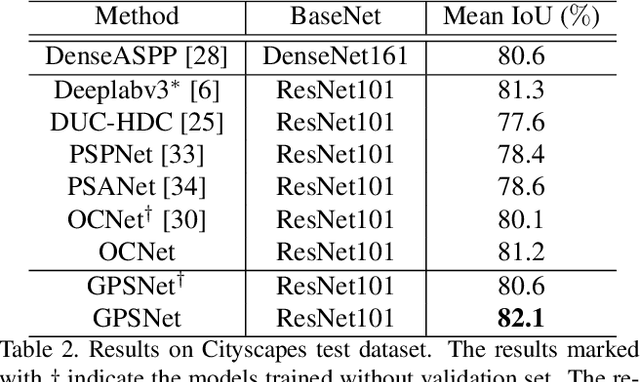
Semantic segmentation is a challenging task that needs to handle large scale variations, deformations and different viewpoints. In this paper, we develop a novel network named Gated Path Selection Network (GPSNet), which aims to learn adaptive receptive fields. In GPSNet, we first design a two-dimensional multi-scale network - SuperNet, which densely incorporates features from growing receptive fields. To dynamically select desirable semantic context, a gate prediction module is further introduced. In contrast to previous works that focus on optimizing sample positions on the regular grids, GPSNet can adaptively capture free form dense semantic contexts. The derived adaptive receptive fields are data-dependent, and are flexible that can model different object geometric transformations. On two representative semantic segmentation datasets, i.e., Cityscapes, and ADE20K, we show that the proposed approach consistently outperforms previous methods and achieves competitive performance without bells and whistles.
AADS: Augmented Autonomous Driving Simulation using Data-driven Algorithms
Jan 23, 2019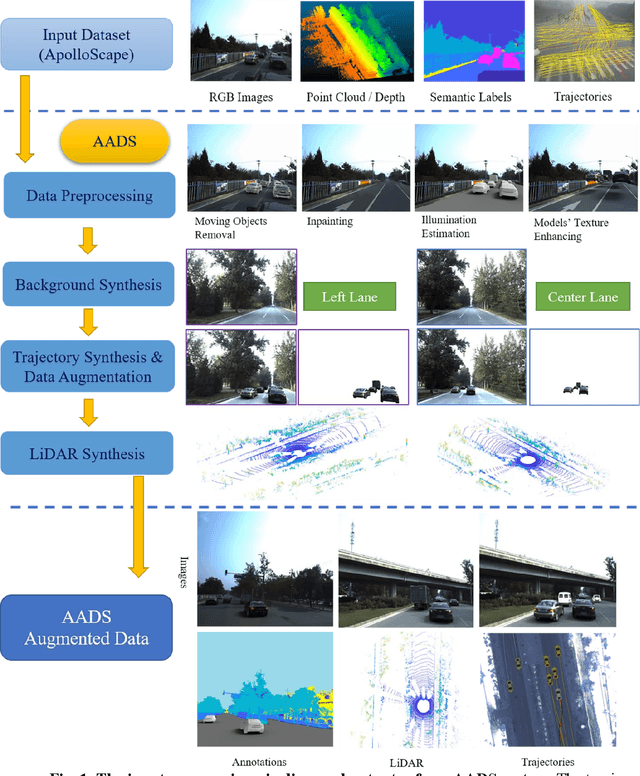

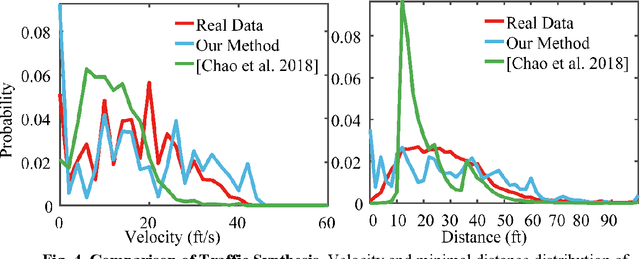
Simulation systems have become an essential component in the development and validation of autonomous driving technologies. The prevailing state-of-the-art approach for simulation is to use game engines or high-fidelity computer graphics (CG) models to create driving scenarios. However, creating CG models and vehicle movements (e.g., the assets for simulation) remains a manual task that can be costly and time-consuming. In addition, the fidelity of CG images still lacks the richness and authenticity of real-world images and using these images for training leads to degraded performance. In this paper we present a novel approach to address these issues: Augmented Autonomous Driving Simulation (AADS). Our formulation augments real-world pictures with a simulated traffic flow to create photo-realistic simulation images and renderings. More specifically, we use LiDAR and cameras to scan street scenes. From the acquired trajectory data, we generate highly plausible traffic flows for cars and pedestrians and compose them into the background. The composite images can be re-synthesized with different viewpoints and sensor models. The resulting images are photo-realistic, fully annotated, and ready for end-to-end training and testing of autonomous driving systems from perception to planning. We explain our system design and validate our algorithms with a number of autonomous driving tasks from detection to segmentation and predictions. Compared to traditional approaches, our method offers unmatched scalability and realism. Scalability is particularly important for AD simulation and we believe the complexity and diversity of the real world cannot be realistically captured in a virtual environment. Our augmented approach combines the flexibility in a virtual environment (e.g., vehicle movements) with the richness of the real world to allow effective simulation of anywhere on earth.
Part-level Car Parsing and Reconstruction from Single Street View
Nov 27, 2018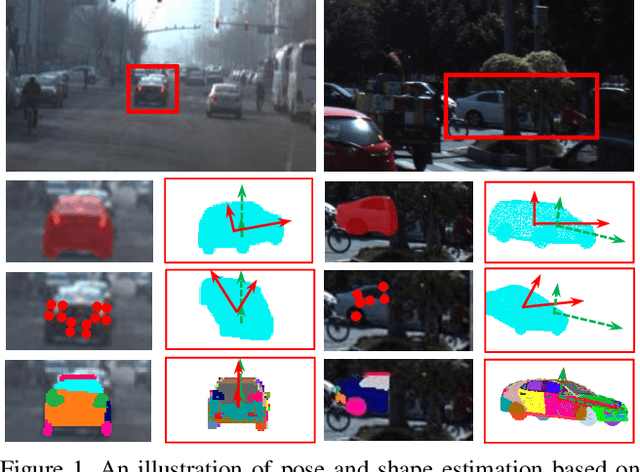
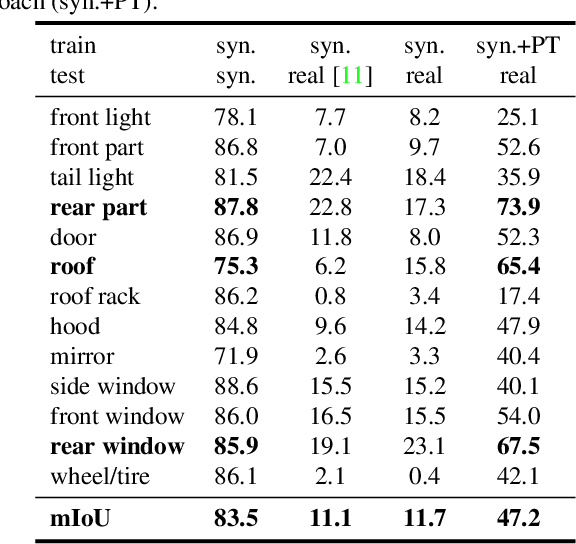
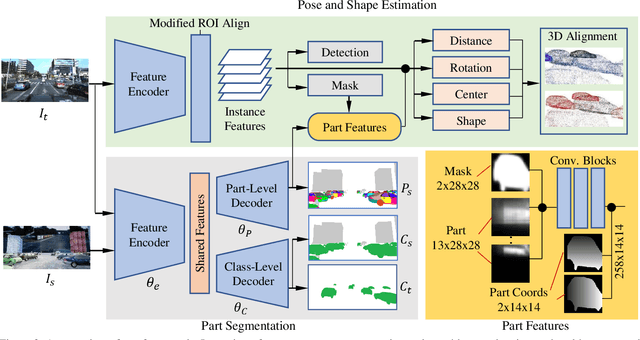
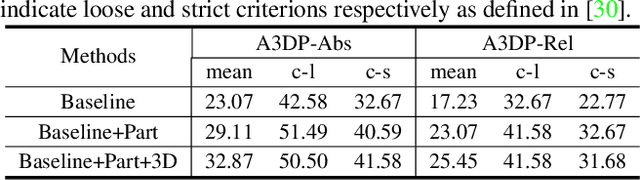
In this paper, we make the first attempt to build a framework to simultaneously estimate semantic parts, shape, translation, and orientation of cars from single street view. Our framework contains three major contributions. Firstly, a novel domain adaptation approach based on the class consistency loss is developed to transfer our part segmentation model from the synthesized images to the real images. Secondly, we propose a novel network structure that leverages part-level features from street views and 3D losses for pose and shape estimation. Thirdly, we construct a high quality dataset that contains more than 300 different car models with physical dimensions and part-level annotations based on global and local deformations. We have conducted experiments on both synthesized data and real images. Our results show that the domain adaptation approach can bring 35.5 percentage point performance improvement in terms of mean intersection-over-union score (mIoU) comparing with the baseline network using domain randomization only. Our network for translation and orientation estimation achieves competitive performance on highly complex street views (e.g., 11 cars per image on average). Moreover, our network is able to reconstruct a list of 3D car models with part-level details from street views, which could benefit various applications such as fine-grained car recognition, vehicle re-identification, and traffic simulation.
The ApolloScape Open Dataset for Autonomous Driving and its Application
Sep 26, 2018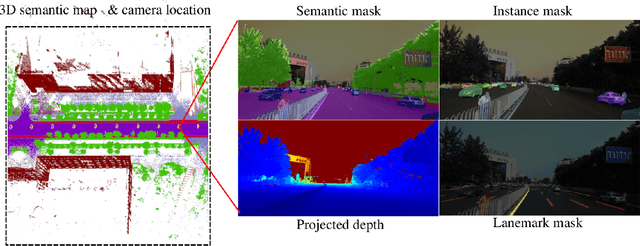
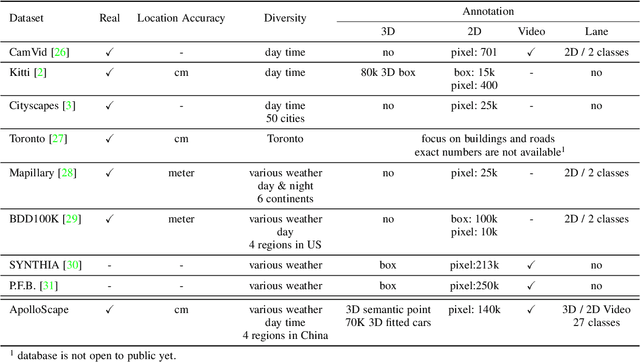
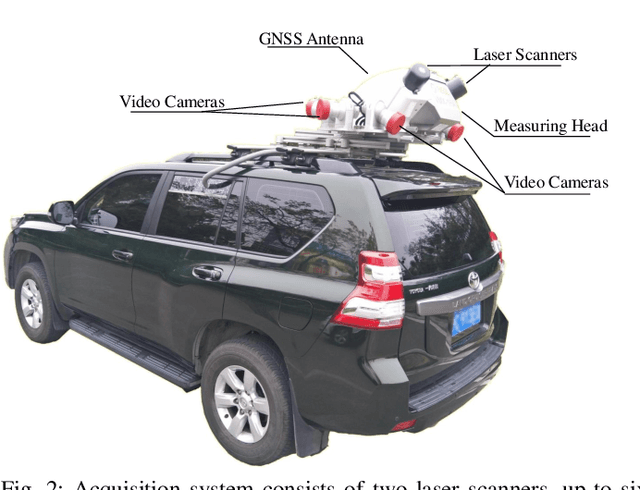
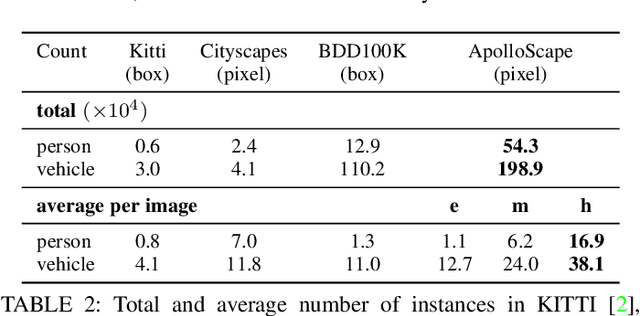
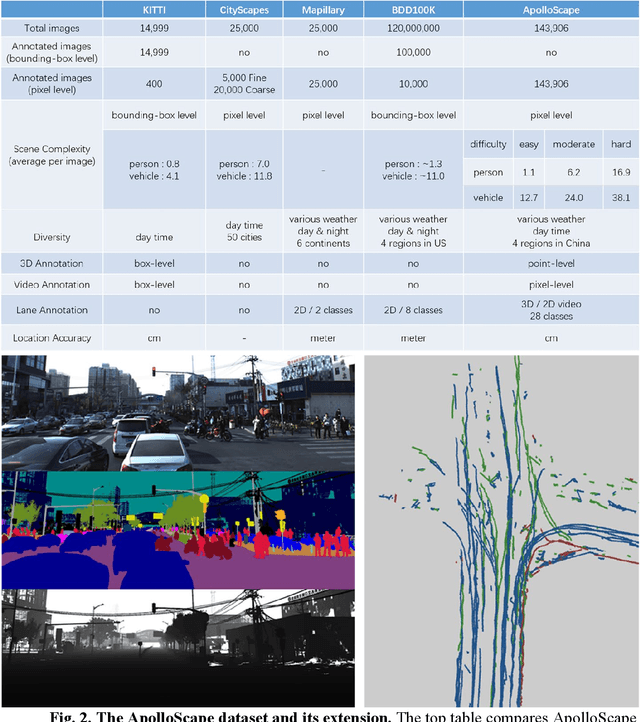
Autonomous driving has attracted tremendous attention especially in the past few years. The key techniques for a self-driving car include solving tasks like 3D map construction, self-localization, parsing the driving road and understanding objects, which enable vehicles to reason and act. However, large scale data set for training and system evaluation is still a bottleneck for developing robust perception models. In this paper, we present the ApolloScape dataset [1] and its applications for autonomous driving. Compared with existing public datasets from real scenes, e.g. KITTI [2] or Cityscapes [3], ApolloScape contains much large and richer labelling including holistic semantic dense point cloud for each site, stereo, per-pixel semantic labelling, lanemark labelling, instance segmentation, 3D car instance, high accurate location for every frame in various driving videos from multiple sites, cities and daytimes. For each task, it contains at lease 15x larger amount of images than SOTA datasets. To label such a complete dataset, we develop various tools and algorithms specified for each task to accelerate the labelling process, such as 3D-2D segment labeling tools, active labelling in videos etc. Depend on ApolloScape, we are able to develop algorithms jointly consider the learning and inference of multiple tasks. In this paper, we provide a sensor fusion scheme integrating camera videos, consumer-grade motion sensors (GPS/IMU), and a 3D semantic map in order to achieve robust self-localization and semantic segmentation for autonomous driving. We show that practically, sensor fusion and joint learning of multiple tasks are beneficial to achieve a more robust and accurate system. We expect our dataset and proposed relevant algorithms can support and motivate researchers for further development of multi-sensor fusion and multi-task learning in the field of computer vision.
A Network Structure to Explicitly Reduce Confusion Errors in Semantic Segmentation
Aug 01, 2018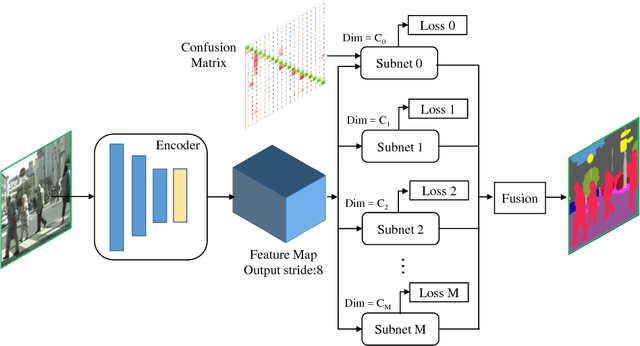
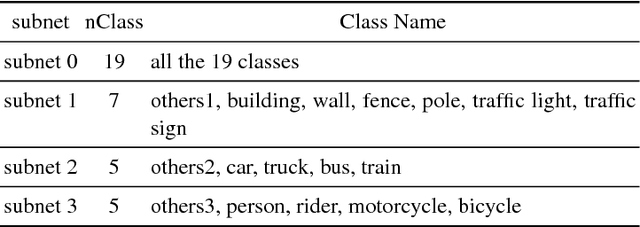
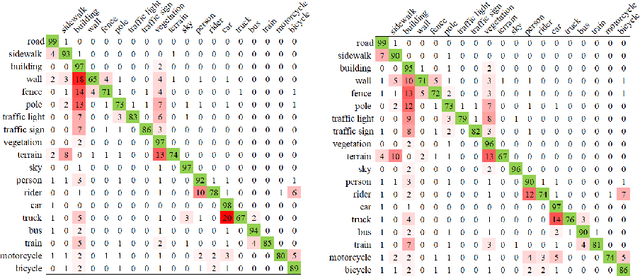
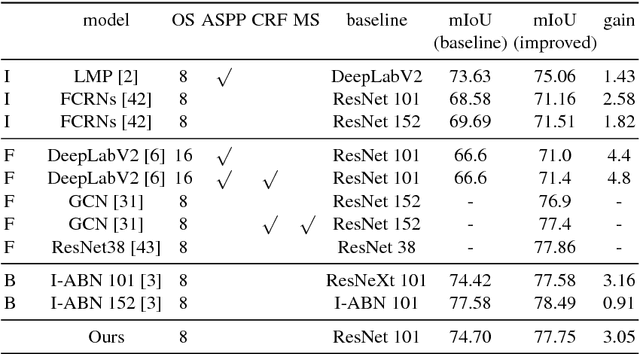
Confusing classes that are ubiquitous in real world often degrade performance for many vision related applications like object detection, classification, and segmentation. The confusion errors are not only caused by similar visual patterns but also amplified by various factors during the training of our designed models, such as reduced feature resolution in the encoding process or imbalanced data distributions. A large amount of deep learning based network structures has been proposed in recent years to deal with these individual factors and improve network performance. However, to our knowledge, no existing work in semantic image segmentation is designed to tackle confusion errors explicitly. In this paper, we present a novel and general network structure that reduces confusion errors in more direct manner and apply the network for semantic segmentation. There are two major contributions in our network structure: 1) We ensemble subnets with heterogeneous output spaces based on the discriminative confusing groups. The training for each subnet can distinguish confusing classes within the group without affecting unrelated classes outside the group. 2) We propose an improved cross-entropy loss function that maximizes the probability assigned to the correct class and penalizes the probabilities assigned to the confusing classes at the same time. Our network structure is a general structure and can be easily adapted to any other networks to further reduce confusion errors. Without any changes in the feature encoder and post-processing steps, our experiments demonstrate consistent and significant improvements on different baseline models on Cityscapes and PASCAL VOC datasets (e.g., 3.05% over ResNet-101 and 1.30% over ResNet-38).