 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Network Structure to Explicitly Reduce Confusion Errors in Semantic Segmentation
Paper and Code
Aug 01, 2018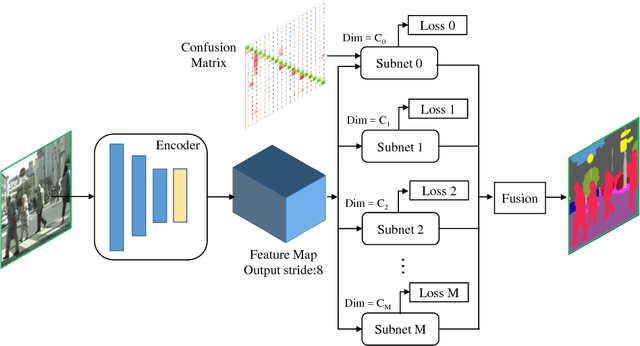
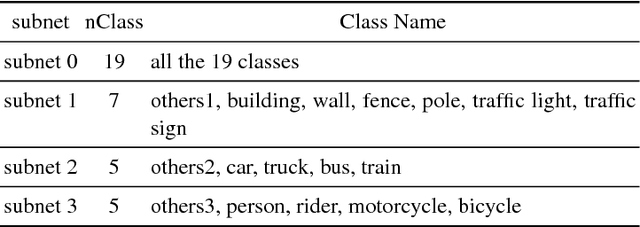
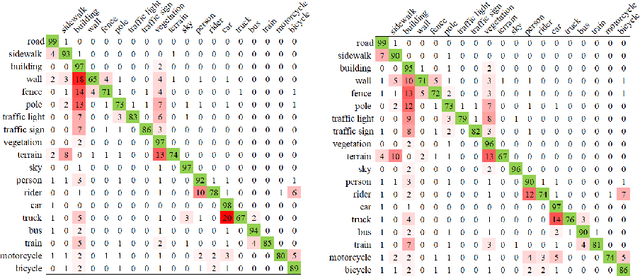
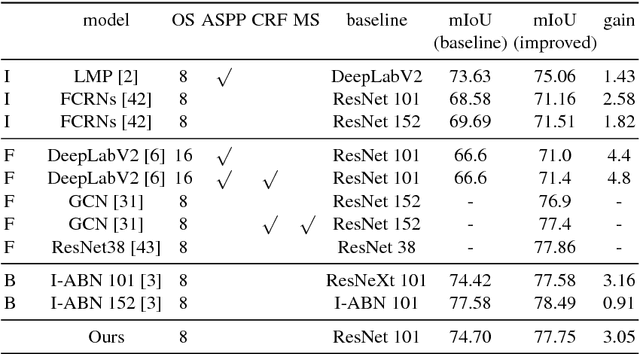
Confusing classes that are ubiquitous in real world often degrade performance for many vision related applications like object detection, classification, and segmentation. The confusion errors are not only caused by similar visual patterns but also amplified by various factors during the training of our designed models, such as reduced feature resolution in the encoding process or imbalanced data distributions. A large amount of deep learning based network structures has been proposed in recent years to deal with these individual factors and improve network performance. However, to our knowledge, no existing work in semantic image segmentation is designed to tackle confusion errors explicitly. In this paper, we present a novel and general network structure that reduces confusion errors in more direct manner and apply the network for semantic segmentation. There are two major contributions in our network structure: 1) We ensemble subnets with heterogeneous output spaces based on the discriminative confusing groups. The training for each subnet can distinguish confusing classes within the group without affecting unrelated classes outside the group. 2) We propose an improved cross-entropy loss function that maximizes the probability assigned to the correct class and penalizes the probabilities assigned to the confusing classes at the same time. Our network structure is a general structure and can be easily adapted to any other networks to further reduce confusion errors. Without any changes in the feature encoder and post-processing steps, our experiments demonstrate consistent and significant improvements on different baseline models on Cityscapes and PASCAL VOC datasets (e.g., 3.05% over ResNet-101 and 1.30% over ResNet-38).