 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStairMaster: Learning to Conquer Risky Hollow Stairs for Agile Quadrupedal Robots
Jun 24, 2026Climbing hollow stairs remains a challenging problem for quadruped robots due to the high risk of leg trapping, severe depth sparsity, and high-frequency depth-sensing noise. In this paper, we propose StairMaster, a novel three-stage reinforcement learning framework for stable locomotion on such extreme discontinuous terrains. Our architecture integrates a Cross-Attention mechanism to extract structural features from noisy depth data, alongside a Spatial-aware Recurrent Unit (SRU) that maintains robust spatio-temporal memory to mitigate perception blind spots. To bridge the sim-to-real gap in depth perception, we propose a high-fidelity sim-to-real depth sensor modeling pipeline that faithfully replicates real-world sensor artifacts. Additionally, we employ a 3D waypoint-guided active perception reward for proactive sensing, alongside hollow gap kinematic and stair edge penalties to ensure precise foothold placement. We successfully deployed StairMaster on a Unitree Go2 robot, demonstrating its ability to conquer hollow stairs with an unprecedented incline of up to 55$^\circ$ through zero-shot transfer. To the best of our knowledge, this is the first RL-based policy to achieve such steep hollow stair climbing in real-world environments. Project Website: https://sivan666666.github.io/StairMaster/.
SimWeaver: Zero-Shot RGB Sim-to-Real for Deformable Manipulation
Jun 13, 2026RGB sim-to-real for deformable manipulation has remained largely unsolved without real-world fine-tuning. We present SimWeaver, which trains zero-shot RGB VLA policies on 200 simulated demonstrations per task, reaching above 80% per-task and 91% average real-world success across 5 diverse deformable tasks including plastic-bag manipulation, without teleoperation or per-task calibration. SimWeaver combines a reliable measurement-backed simulator (SimWeaver-Sim) with an extensible asset framework supporting single-image generation(SimWeaver-Asset), a deterministic topology-aware trajectory synthesizer (SimWeaver-Syn), and a sim-to-real protocol with ISP-aware photometric augmentation (SimWeaver-Real). On silk grasping, the sim-trained policy reaches 100% under visual distribution shifts where real-data baselines drop to 9-70%, at two orders of magnitude lower per-trajectory cost. We will release SimWeaver and a representative asset subset. Project page: https://simweaver.github.io/
ISAP-3D: Identity-Slot Aligned Part-Aware 3D Generation
Jun 10, 2026Part-aware 3D generation aims to synthesize structured objects with semantically meaningful components, yet often suffers from structural ambiguity due to identity-layout entanglement. Existing methods either infer part identity and spatial layout implicitly, which can lead to unstable part allocation (e.g., slot swapping or part merging), or rely on strong layout conditions that are difficult to obtain in practice. We attribute this ambiguity to identity-slot permutation freedom: without explicit identity-slot alignment, the correspondence between semantic parts and generation slots is not identifiable during training, allowing multiple slot assignments to fit the same supervision and leading to inconsistent decomposition. Based on this insight, we argue that stable part-aware generation requires identity-aligned one-to-one slot modelling. We therefore propose an identity-slot aligned framework, ISAP-3D, which anchors each part with semantic identity tokens and performs identity-conditioned one-to-one layout prediction, followed by layout-conditioned geometry synthesis. Structured local-global conditioning maintains identity alignment across semantic, spatial, and geometric stages. We also construct a part-level dataset with a unified semantic protocol to enable learnable and consistent identity-slot alignment. Extensive experiments demonstrate improved structural stability, controllability, and robustness over state-of-the-art part-aware generation baselines.
SocialMirror: Reconstructing 3D Human Interaction Behaviors from Monocular Videos with Semantic and Geometric Guidance
Apr 15, 2026Accurately reconstructing human behavior in close-interaction scenarios is crucial for enabling realistic virtual interactions in augmented reality, precise motion analysis in sports, and natural collaborative behavior in human-robot tasks. Reliable reconstruction in these contexts significantly enhances the realism and effectiveness of AI-driven interactive applications. However, human reconstruction from monocular videos in close-interaction scenarios remains challenging due to severe mutual occlusions, leading local motion ambiguity, disrupted temporal continuity and spatial relationship error. In this paper, we propose SocialMirror, a diffusion-based framework that integrates semantic and geometric cues to effectively address these issues. Specifically, we first leverage high-level interaction descriptions generated by a vision-language model to guide a semantic-guided motion infiller, hallucinating occluded bodies and resolving local pose ambiguities. Next, we propose a sequence-level temporal refiner that enforces smooth, jitter-free motions, while incorporating geometric constraints during sampling to ensure plausible contact and spatial relationships. Evaluations on multiple interaction benchmarks show that SocialMirror achieves state-of-the-art performance in reconstructing interactive human meshes, demonstrating strong generalization across unseen datasets and in-the-wild scenarios. The code will be released upon publication.
Real Garment Benchmark (RGBench): A Comprehensive Benchmark for Robotic Garment Manipulation featuring a High-Fidelity Scalable Simulator
Nov 12, 2025While there has been significant progress to use simulated data to learn robotic manipulation of rigid objects, applying its success to deformable objects has been hindered by the lack of both deformable object models and realistic non-rigid body simulators. In this paper, we present Real Garment Benchmark (RGBench), a comprehensive benchmark for robotic manipulation of garments. It features a diverse set of over 6000 garment mesh models, a new high-performance simulator, and a comprehensive protocol to evaluate garment simulation quality with carefully measured real garment dynamics. Our experiments demonstrate that our simulator outperforms currently available cloth simulators by a large margin, reducing simulation error by 20% while maintaining a speed of 3 times faster. We will publicly release RGBench to accelerate future research in robotic garment manipulation. Website: https://rgbench.github.io/
A Survey: Learning Embodied Intelligence from Physical Simulators and World Models
Jul 01, 2025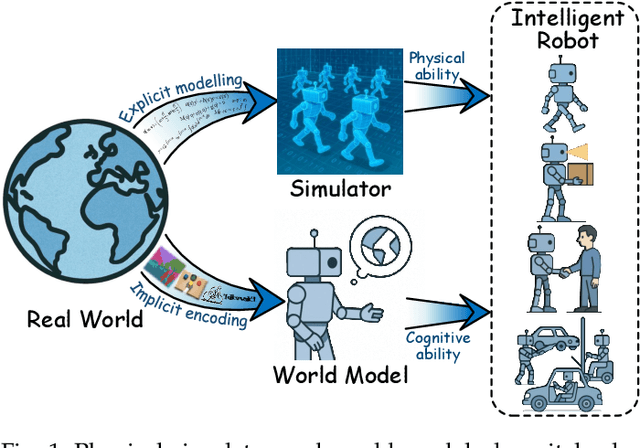
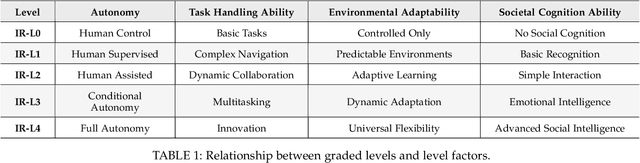
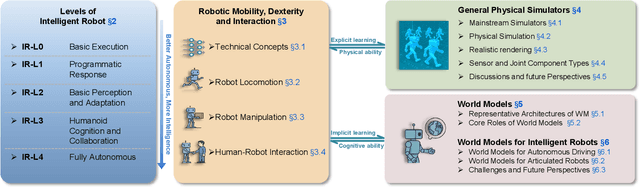

The pursuit of artificial general intelligence (AGI) has placed embodied intelligence at the forefront of robotics research. Embodied intelligence focuses on agents capable of perceiving, reasoning, and acting within the physical world. Achieving robust embodied intelligence requires not only advanced perception and control, but also the ability to ground abstract cognition in real-world interactions. Two foundational technologies, physical simulators and world models, have emerged as critical enablers in this quest. Physical simulators provide controlled, high-fidelity environments for training and evaluating robotic agents, allowing safe and efficient development of complex behaviors. In contrast, world models empower robots with internal representations of their surroundings, enabling predictive planning and adaptive decision-making beyond direct sensory input. This survey systematically reviews recent advances in learning embodied AI through the integration of physical simulators and world models. We analyze their complementary roles in enhancing autonomy, adaptability, and generalization in intelligent robots, and discuss the interplay between external simulation and internal modeling in bridging the gap between simulated training and real-world deployment. By synthesizing current progress and identifying open challenges, this survey aims to provide a comprehensive perspective on the path toward more capable and generalizable embodied AI systems. We also maintain an active repository that contains up-to-date literature and open-source projects at https://github.com/NJU3DV-LoongGroup/Embodied-World-Models-Survey.
OLiDM: Object-aware LiDAR Diffusion Models for Autonomous Driving
Dec 23, 2024



To enhance autonomous driving safety in complex scenarios, various methods have been proposed to simulate LiDAR point cloud data. Nevertheless, these methods often face challenges in producing high-quality, diverse, and controllable foreground objects. To address the needs of object-aware tasks in 3D perception, we introduce OLiDM, a novel framework capable of generating high-fidelity LiDAR data at both the object and the scene levels. OLiDM consists of two pivotal components: the Object-Scene Progressive Generation (OPG) module and the Object Semantic Alignment (OSA) module. OPG adapts to user-specific prompts to generate desired foreground objects, which are subsequently employed as conditions in scene generation, ensuring controllable outputs at both the object and scene levels. This also facilitates the association of user-defined object-level annotations with the generated LiDAR scenes. Moreover, OSA aims to rectify the misalignment between foreground objects and background scenes, enhancing the overall quality of the generated objects. The broad effectiveness of OLiDM is demonstrated across various LiDAR generation tasks, as well as in 3D perception tasks. Specifically, on the KITTI-360 dataset, OLiDM surpasses prior state-of-the-art methods such as UltraLiDAR by 17.5 in FPD. Additionally, in sparse-to-dense LiDAR completion, OLiDM achieves a significant improvement over LiDARGen, with a 57.47\% increase in semantic IoU. Moreover, OLiDM enhances the performance of mainstream 3D detectors by 2.4\% in mAP and 1.9\% in NDS, underscoring its potential in advancing object-aware 3D tasks. Code is available at: https://yanty123.github.io/OLiDM.
NPC: Neural Predictive Control for Fuel-Efficient Autonomous Trucks
Dec 18, 2024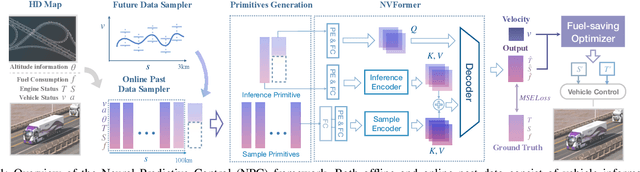
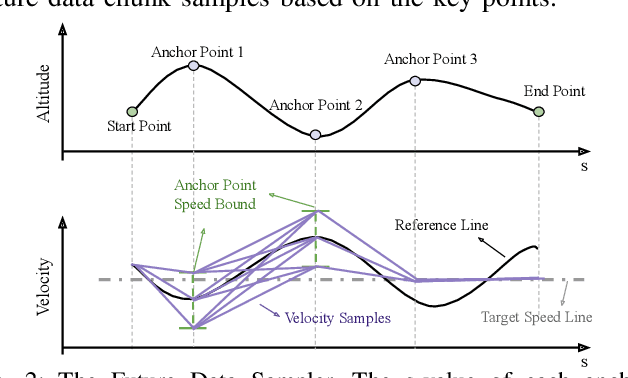
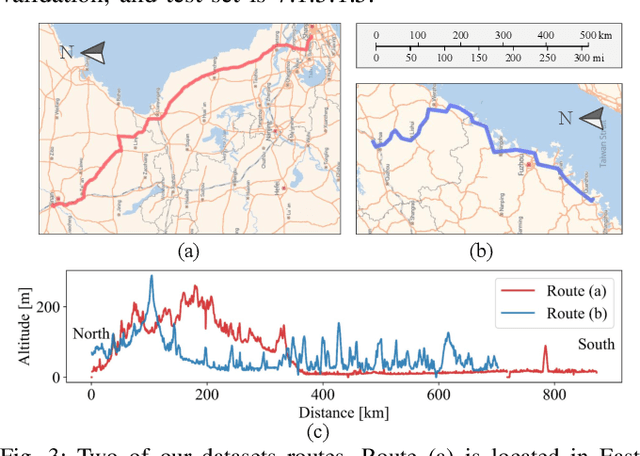

Fuel efficiency is a crucial aspect of long-distance cargo transportation by oil-powered trucks that economize on costs and decrease carbon emissions. Current predictive control methods depend on an accurate model of vehicle dynamics and engine, including weight, drag coefficient, and the Brake-specific Fuel Consumption (BSFC) map of the engine. We propose a pure data-driven method, Neural Predictive Control (NPC), which does not use any physical model for the vehicle. After training with over 20,000 km of historical data, the novel proposed NVFormer implicitly models the relationship between vehicle dynamics, road slope, fuel consumption, and control commands using the attention mechanism. Based on the online sampled primitives from the past of the current freight trip and anchor-based future data synthesis, the NVFormer can infer optimal control command for reasonable fuel consumption. The physical model-free NPC outperforms the base PCC method with 2.41% and 3.45% more significant fuel saving in simulation and open-road highway testing, respectively.
* 7 pages, 6 figures, for associated mpeg file, see https://www.youtube.com/watch?v=hqgpj7LhiL4
ESP: Extro-Spective Prediction for Long-term Behavior Reasoning in Emergency Scenarios
May 07, 2024



Emergent-scene safety is the key milestone for fully autonomous driving, and reliable on-time prediction is essential to maintain safety in emergency scenarios. However, these emergency scenarios are long-tailed and hard to collect, which restricts the system from getting reliable predictions. In this paper, we build a new dataset, which aims at the long-term prediction with the inconspicuous state variation in history for the emergency event, named the Extro-Spective Prediction (ESP) problem. Based on the proposed dataset, a flexible feature encoder for ESP is introduced to various prediction methods as a seamless plug-in, and its consistent performance improvement underscores its efficacy. Furthermore, a new metric named clamped temporal error (CTE) is proposed to give a more comprehensive evaluation of prediction performance, especially in time-sensitive emergency events of subseconds. Interestingly, as our ESP features can be described in human-readable language naturally, the application of integrating into ChatGPT also shows huge potential. The ESP-dataset and all benchmarks are released at https://dingrui-wang.github.io/ESP-Dataset/.
IS-Fusion: Instance-Scene Collaborative Fusion for Multimodal 3D Object Detection
Mar 22, 2024



Bird's eye view (BEV) representation has emerged as a dominant solution for describing 3D space in autonomous driving scenarios. However, objects in the BEV representation typically exhibit small sizes, and the associated point cloud context is inherently sparse, which leads to great challenges for reliable 3D perception. In this paper, we propose IS-Fusion, an innovative multimodal fusion framework that jointly captures the Instance- and Scene-level contextual information. IS-Fusion essentially differs from existing approaches that only focus on the BEV scene-level fusion by explicitly incorporating instance-level multimodal information, thus facilitating the instance-centric tasks like 3D object detection. It comprises a Hierarchical Scene Fusion (HSF) module and an Instance-Guided Fusion (IGF) module. HSF applies Point-to-Grid and Grid-to-Region transformers to capture the multimodal scene context at different granularities. IGF mines instance candidates, explores their relationships, and aggregates the local multimodal context for each instance. These instances then serve as guidance to enhance the scene feature and yield an instance-aware BEV representation. On the challenging nuScenes benchmark, IS-Fusion outperforms all the published multimodal works to date. Code is available at: https://github.com/yinjunbo/IS-Fusion.