 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistent Sheaf Laplacian Analysis of Protein Stability and Solubility Changes upon Mutation
Jan 18, 2026Genetic mutations frequently disrupt protein structure, stability, and solubility, acting as primary drivers for a wide spectrum of diseases. Despite the critical importance of these molecular alterations, existing computational models often lack interpretability, and fail to integrate essential physicochemical interaction. To overcome these limitations, we propose SheafLapNet, a unified predictive framework grounded in the mathematical theory of Topological Deep Learning (TDL) and Persistent Sheaf Laplacian (PSL). Unlike standard Topological Data Analysis (TDA) tools such as persistent homology, which are often insensitive to heterogeneous information, PSL explicitly encodes specific physical and chemical information such as partial charges directly into the topological analysis. SheafLapNet synergizes these sheaf-theoretic invariants with advanced protein transformer features and auxiliary physical descriptors to capture intrinsic molecular interactions in a multiscale and mechanistic manner. To validate our framework, we employ rigorous benchmarks for both regression and classification tasks. For stability prediction, we utilize the comprehensive S2648 and S350 datasets. For solubility prediction, we employ the PON-Sol2 dataset, which provides annotations for increased, decreased, or neutral solubility changes. By integrating these multi-perspective features, SheafLapNet achieves state-of-the-art performance across these diverse benchmarks, demonstrating that sheaf-theoretic modeling significantly enhances both interpretability and generalizability in predicting mutation-induced structural and functional changes.
SIN-Bench: Tracing Native Evidence Chains in Long-Context Multimodal Scientific Interleaved Literature
Jan 15, 2026Evaluating whether multimodal large language models truly understand long-form scientific papers remains challenging: answer-only metrics and synthetic "Needle-In-A-Haystack" tests often reward answer matching without requiring a causal, evidence-linked reasoning trace in the document. We propose the "Fish-in-the-Ocean" (FITO) paradigm, which requires models to construct explicit cross-modal evidence chains within native scientific documents. To operationalize FITO, we build SIN-Data, a scientific interleaved corpus that preserves the native interleaving of text and figures. On top of it, we construct SIN-Bench with four progressive tasks covering evidence discovery (SIN-Find), hypothesis verification (SIN-Verify), grounded QA (SIN-QA), and evidence-anchored synthesis (SIN-Summary). We further introduce "No Evidence, No Score", scoring predictions when grounded to verifiable anchors and diagnosing evidence quality via matching, relevance, and logic. Experiments on eight MLLMs show that grounding is the primary bottleneck: Gemini-3-pro achieves the best average overall score (0.573), while GPT-5 attains the highest SIN-QA answer accuracy (0.767) but underperforms on evidence-aligned overall scores, exposing a gap between correctness and traceable support.
SymbioSim: Human-in-the-loop Simulation Platform for Bidirectional Continuing Learning in Human-Robot Interaction
Feb 11, 2025The development of intelligent robots seeks to seamlessly integrate them into the human world, providing assistance and companionship in daily life and work, with the ultimate goal of achieving human-robot symbiosis. To realize this vision, robots must continuously learn and evolve through consistent interaction and collaboration with humans, while humans need to gradually develop an understanding of and trust in robots through shared experiences. However, training and testing algorithms directly on physical robots involve substantial costs and safety risks. Moreover, current robotic simulators fail to support real human participation, limiting their ability to provide authentic interaction experiences and gather valuable human feedback. In this paper, we introduce SymbioSim, a novel human-in-the-loop robotic simulation platform designed to enable the safe and efficient development, evaluation, and optimization of human-robot interactions. By leveraging a carefully designed system architecture and modules, SymbioSim delivers a natural and realistic interaction experience, facilitating bidirectional continuous learning and adaptation for both humans and robots. Extensive experiments and user studies demonstrate the platform's promising performance and highlight its potential to significantly advance research on human-robot symbiosis.
NPC: Neural Predictive Control for Fuel-Efficient Autonomous Trucks
Dec 18, 2024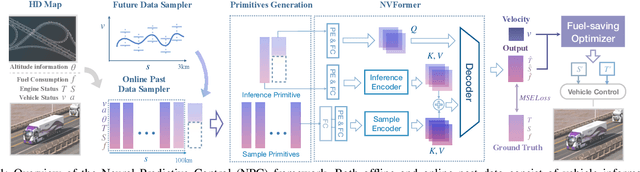
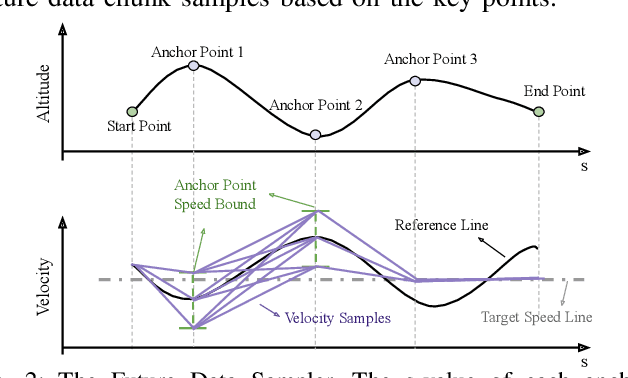
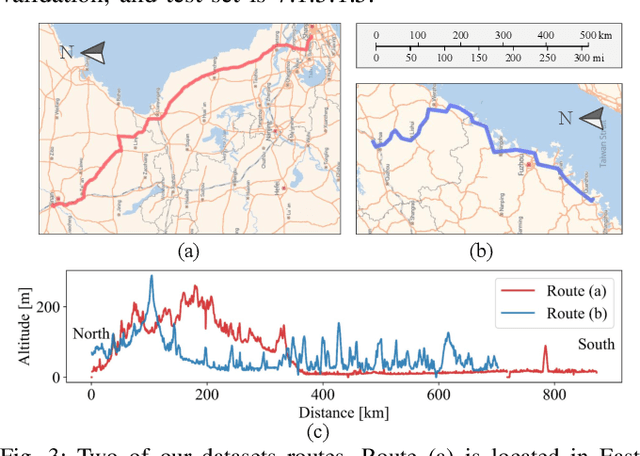

Fuel efficiency is a crucial aspect of long-distance cargo transportation by oil-powered trucks that economize on costs and decrease carbon emissions. Current predictive control methods depend on an accurate model of vehicle dynamics and engine, including weight, drag coefficient, and the Brake-specific Fuel Consumption (BSFC) map of the engine. We propose a pure data-driven method, Neural Predictive Control (NPC), which does not use any physical model for the vehicle. After training with over 20,000 km of historical data, the novel proposed NVFormer implicitly models the relationship between vehicle dynamics, road slope, fuel consumption, and control commands using the attention mechanism. Based on the online sampled primitives from the past of the current freight trip and anchor-based future data synthesis, the NVFormer can infer optimal control command for reasonable fuel consumption. The physical model-free NPC outperforms the base PCC method with 2.41% and 3.45% more significant fuel saving in simulation and open-road highway testing, respectively.
* 7 pages, 6 figures, for associated mpeg file, see https://www.youtube.com/watch?v=hqgpj7LhiL4
FreeCap: Hybrid Calibration-Free Motion Capture in Open Environments
Nov 07, 2024
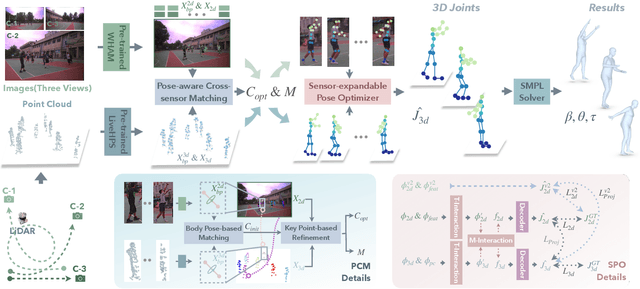
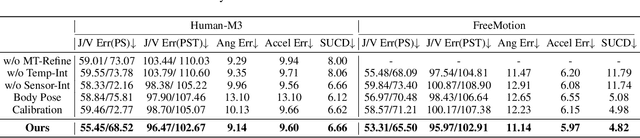

We propose a novel hybrid calibration-free method FreeCap to accurately capture global multi-person motions in open environments. Our system combines a single LiDAR with expandable moving cameras, allowing for flexible and precise motion estimation in a unified world coordinate. In particular, We introduce a local-to-global pose-aware cross-sensor human-matching module that predicts the alignment among each sensor, even in the absence of calibration. Additionally, our coarse-to-fine sensor-expandable pose optimizer further optimizes the 3D human key points and the alignments, it is also capable of incorporating additional cameras to enhance accuracy. Extensive experiments on Human-M3 and FreeMotion datasets demonstrate that our method significantly outperforms state-of-the-art single-modal methods, offering an expandable and efficient solution for multi-person motion capture across various applications.
Mini-InternVL: A Flexible-Transfer Pocket Multimodal Model with 5% Parameters and 90% Performance
Oct 21, 2024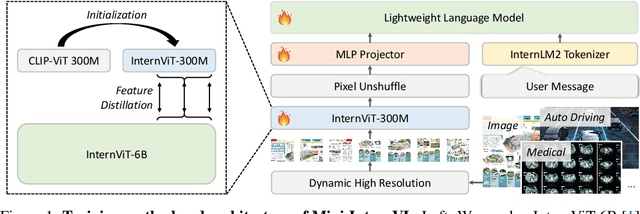
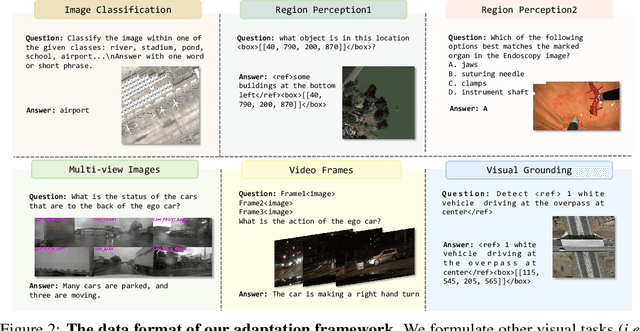
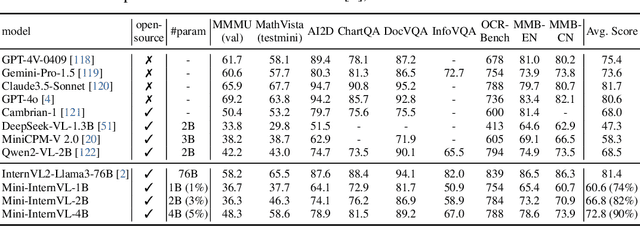
Multimodal large language models (MLLMs) have demonstrated impressive performance in vision-language tasks across a broad spectrum of domains. However, the large model scale and associated high computational costs pose significant challenges for training and deploying MLLMs on consumer-grade GPUs or edge devices, thereby hindering their widespread application. In this work, we introduce Mini-InternVL, a series of MLLMs with parameters ranging from 1B to 4B, which achieves 90% of the performance with only 5% of the parameters. This significant improvement in efficiency and effectiveness makes our models more accessible and applicable in various real-world scenarios. To further promote the adoption of our models, we develop a unified adaptation framework for Mini-InternVL, which enables our models to transfer and outperform specialized models in downstream tasks, including autonomous driving, medical images, and remote sensing. We believe that our study can provide valuable insights and resources to advance the development of efficient and effective MLLMs. Code is available at https://github.com/OpenGVLab/InternVL.
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024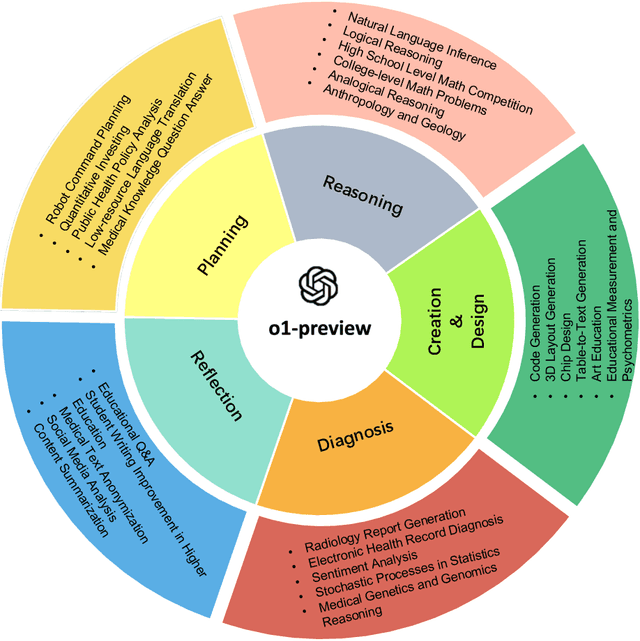


This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.
Towards Practical Human Motion Prediction with LiDAR Point Clouds
Aug 15, 2024



Human motion prediction is crucial for human-centric multimedia understanding and interacting. Current methods typically rely on ground truth human poses as observed input, which is not practical for real-world scenarios where only raw visual sensor data is available. To implement these methods in practice, a pre-phrase of pose estimation is essential. However, such two-stage approaches often lead to performance degradation due to the accumulation of errors. Moreover, reducing raw visual data to sparse keypoint representations significantly diminishes the density of information, resulting in the loss of fine-grained features. In this paper, we propose \textit{LiDAR-HMP}, the first single-LiDAR-based 3D human motion prediction approach, which receives the raw LiDAR point cloud as input and forecasts future 3D human poses directly. Building upon our novel structure-aware body feature descriptor, LiDAR-HMP adaptively maps the observed motion manifold to future poses and effectively models the spatial-temporal correlations of human motions for further refinement of prediction results. Extensive experiments show that our method achieves state-of-the-art performance on two public benchmarks and demonstrates remarkable robustness and efficacy in real-world deployments.
LiveHPS++: Robust and Coherent Motion Capture in Dynamic Free Environment
Jul 13, 2024



LiDAR-based human motion capture has garnered significant interest in recent years for its practicability in large-scale and unconstrained environments. However, most methods rely on cleanly segmented human point clouds as input, the accuracy and smoothness of their motion results are compromised when faced with noisy data, rendering them unsuitable for practical applications. To address these limitations and enhance the robustness and precision of motion capture with noise interference, we introduce LiveHPS++, an innovative and effective solution based on a single LiDAR system. Benefiting from three meticulously designed modules, our method can learn dynamic and kinematic features from human movements, and further enable the precise capture of coherent human motions in open settings, making it highly applicable to real-world scenarios. Through extensive experiments, LiveHPS++ has proven to significantly surpass existing state-of-the-art methods across various datasets, establishing a new benchmark in the field.
Needle In A Multimodal Haystack
Jun 11, 2024With the rapid advancement of multimodal large language models (MLLMs), their evaluation has become increasingly comprehensive. However, understanding long multimodal content, as a foundational ability for real-world applications, remains underexplored. In this work, we present Needle In A Multimodal Haystack (MM-NIAH), the first benchmark specifically designed to systematically evaluate the capability of existing MLLMs to comprehend long multimodal documents. Our benchmark includes three types of evaluation tasks: multimodal retrieval, counting, and reasoning. In each task, the model is required to answer the questions according to different key information scattered throughout the given multimodal document. Evaluating the leading MLLMs on MM-NIAH, we observe that existing models still have significant room for improvement on these tasks, especially on vision-centric evaluation. We hope this work can provide a platform for further research on long multimodal document comprehension and contribute to the advancement of MLLMs. Code and benchmark are released at https://github.com/OpenGVLab/MM-NIAH.