 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond External Guidance: Unleashing the Semantic Richness Inside Diffusion Transformers for Improved Training
Jan 12, 2026Recent works such as REPA have shown that guiding diffusion models with external semantic features (e.g., DINO) can significantly accelerate the training of diffusion transformers (DiTs). However, this requires the use of pretrained external networks, introducing additional dependencies and reducing flexibility. In this work, we argue that DiTs actually have the power to guide the training of themselves, and propose \textbf{Self-Transcendence}, a simple yet effective method that achieves fast convergence using internal feature supervision only. It is found that the slow convergence in DiT training primarily stems from the difficulty of representation learning in shallow layers. To address this, we initially train the DiT model by aligning its shallow features with the latent representations from the pretrained VAE for a short phase (e.g., 40 epochs), then apply classifier-free guidance to the intermediate features, enhancing their discriminative capability and semantic expressiveness. These enriched internal features, learned entirely within the model, are used as supervision signals to guide a new DiT training. Compared to existing self-contained methods, our approach brings a significant performance boost. It can even surpass REPA in terms of generation quality and convergence speed, but without the need for any external pretrained models. Our method is not only more flexible for different backbones but also has the potential to be adopted for a wider range of diffusion-based generative tasks. The source code of our method can be found at https://github.com/csslc/Self-Transcendence.
One-Step Diffusion for Detail-Rich and Temporally Consistent Video Super-Resolution
Jun 18, 2025

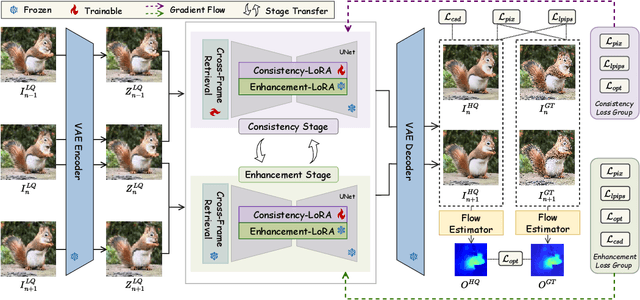

It is a challenging problem to reproduce rich spatial details while maintaining temporal consistency in real-world video super-resolution (Real-VSR), especially when we leverage pre-trained generative models such as stable diffusion (SD) for realistic details synthesis. Existing SD-based Real-VSR methods often compromise spatial details for temporal coherence, resulting in suboptimal visual quality. We argue that the key lies in how to effectively extract the degradation-robust temporal consistency priors from the low-quality (LQ) input video and enhance the video details while maintaining the extracted consistency priors. To achieve this, we propose a Dual LoRA Learning (DLoRAL) paradigm to train an effective SD-based one-step diffusion model, achieving realistic frame details and temporal consistency simultaneously. Specifically, we introduce a Cross-Frame Retrieval (CFR) module to aggregate complementary information across frames, and train a Consistency-LoRA (C-LoRA) to learn robust temporal representations from degraded inputs. After consistency learning, we fix the CFR and C-LoRA modules and train a Detail-LoRA (D-LoRA) to enhance spatial details while aligning with the temporal space defined by C-LoRA to keep temporal coherence. The two phases alternate iteratively for optimization, collaboratively delivering consistent and detail-rich outputs. During inference, the two LoRA branches are merged into the SD model, allowing efficient and high-quality video restoration in a single diffusion step. Experiments show that DLoRAL achieves strong performance in both accuracy and speed. Code and models are available at https://github.com/yjsunnn/DLoRAL.
HUMOF: Human Motion Forecasting in Interactive Social Scenes
Jun 05, 2025Complex scenes present significant challenges for predicting human behaviour due to the abundance of interaction information, such as human-human and humanenvironment interactions. These factors complicate the analysis and understanding of human behaviour, thereby increasing the uncertainty in forecasting human motions. Existing motion prediction methods thus struggle in these complex scenarios. In this paper, we propose an effective method for human motion forecasting in interactive scenes. To achieve a comprehensive representation of interactions, we design a hierarchical interaction feature representation so that high-level features capture the overall context of the interactions, while low-level features focus on fine-grained details. Besides, we propose a coarse-to-fine interaction reasoning module that leverages both spatial and frequency perspectives to efficiently utilize hierarchical features, thereby enhancing the accuracy of motion predictions. Our method achieves state-of-the-art performance across four public datasets. Code will be released when this paper is published.
UniDemoiré: Towards Universal Image Demoiréing with Data Generation and Synthesis
Feb 10, 2025Image demoir\'eing poses one of the most formidable challenges in image restoration, primarily due to the unpredictable and anisotropic nature of moir\'e patterns. Limited by the quantity and diversity of training data, current methods tend to overfit to a single moir\'e domain, resulting in performance degradation for new domains and restricting their robustness in real-world applications. In this paper, we propose a universal image demoir\'eing solution, UniDemoir\'e, which has superior generalization capability. Notably, we propose innovative and effective data generation and synthesis methods that can automatically provide vast high-quality moir\'e images to train a universal demoir\'eing model. Our extensive experiments demonstrate the cutting-edge performance and broad potential of our approach for generalized image demoir\'eing.
Generalizable Single-view Object Pose Estimation by Two-side Generating and Matching
Nov 24, 2024
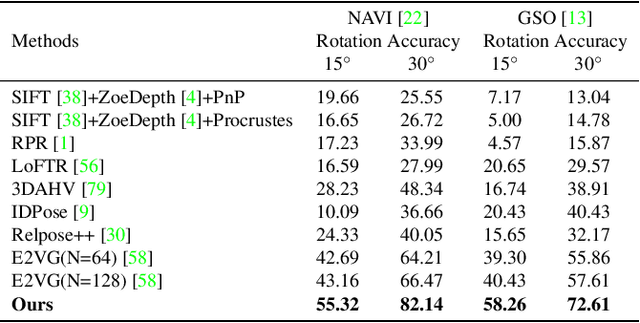
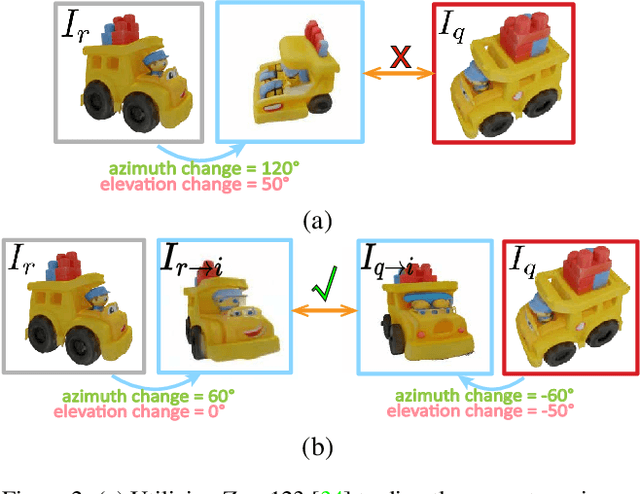
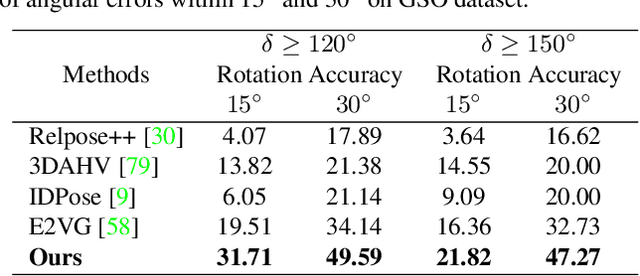
In this paper, we present a novel generalizable object pose estimation method to determine the object pose using only one RGB image. Unlike traditional approaches that rely on instance-level object pose estimation and necessitate extensive training data, our method offers generalization to unseen objects without extensive training, operates with a single reference image of the object, and eliminates the need for 3D object models or multiple views of the object. These characteristics are achieved by utilizing a diffusion model to generate novel-view images and conducting a two-sided matching on these generated images. Quantitative experiments demonstrate the superiority of our method over existing pose estimation techniques across both synthetic and real-world datasets. Remarkably, our approach maintains strong performance even in scenarios with significant viewpoint changes, highlighting its robustness and versatility in challenging conditions. The code will be re leased at https://github.com/scy639/Gen2SM.
Towards Practical Human Motion Prediction with LiDAR Point Clouds
Aug 15, 2024



Human motion prediction is crucial for human-centric multimedia understanding and interacting. Current methods typically rely on ground truth human poses as observed input, which is not practical for real-world scenarios where only raw visual sensor data is available. To implement these methods in practice, a pre-phrase of pose estimation is essential. However, such two-stage approaches often lead to performance degradation due to the accumulation of errors. Moreover, reducing raw visual data to sparse keypoint representations significantly diminishes the density of information, resulting in the loss of fine-grained features. In this paper, we propose \textit{LiDAR-HMP}, the first single-LiDAR-based 3D human motion prediction approach, which receives the raw LiDAR point cloud as input and forecasts future 3D human poses directly. Building upon our novel structure-aware body feature descriptor, LiDAR-HMP adaptively maps the observed motion manifold to future poses and effectively models the spatial-temporal correlations of human motions for further refinement of prediction results. Extensive experiments show that our method achieves state-of-the-art performance on two public benchmarks and demonstrates remarkable robustness and efficacy in real-world deployments.
LiveHPS++: Robust and Coherent Motion Capture in Dynamic Free Environment
Jul 13, 2024



LiDAR-based human motion capture has garnered significant interest in recent years for its practicability in large-scale and unconstrained environments. However, most methods rely on cleanly segmented human point clouds as input, the accuracy and smoothness of their motion results are compromised when faced with noisy data, rendering them unsuitable for practical applications. To address these limitations and enhance the robustness and precision of motion capture with noise interference, we introduce LiveHPS++, an innovative and effective solution based on a single LiDAR system. Benefiting from three meticulously designed modules, our method can learn dynamic and kinematic features from human movements, and further enable the precise capture of coherent human motions in open settings, making it highly applicable to real-world scenarios. Through extensive experiments, LiveHPS++ has proven to significantly surpass existing state-of-the-art methods across various datasets, establishing a new benchmark in the field.
LaserHuman: Language-guided Scene-aware Human Motion Generation in Free Environment
Mar 21, 2024Language-guided scene-aware human motion generation has great significance for entertainment and robotics. In response to the limitations of existing datasets, we introduce LaserHuman, a pioneering dataset engineered to revolutionize Scene-Text-to-Motion research. LaserHuman stands out with its inclusion of genuine human motions within 3D environments, unbounded free-form natural language descriptions, a blend of indoor and outdoor scenarios, and dynamic, ever-changing scenes. Diverse modalities of capture data and rich annotations present great opportunities for the research of conditional motion generation, and can also facilitate the development of real-life applications. Moreover, to generate semantically consistent and physically plausible human motions, we propose a multi-conditional diffusion model, which is simple but effective, achieving state-of-the-art performance on existing datasets.
HUNTER: Unsupervised Human-centric 3D Detection via Transferring Knowledge from Synthetic Instances to Real Scenes
Mar 15, 2024



Human-centric 3D scene understanding has recently drawn increasing attention, driven by its critical impact on robotics. However, human-centric real-life scenarios are extremely diverse and complicated, and humans have intricate motions and interactions. With limited labeled data, supervised methods are difficult to generalize to general scenarios, hindering real-life applications. Mimicking human intelligence, we propose an unsupervised 3D detection method for human-centric scenarios by transferring the knowledge from synthetic human instances to real scenes. To bridge the gap between the distinct data representations and feature distributions of synthetic models and real point clouds, we introduce novel modules for effective instance-to-scene representation transfer and synthetic-to-real feature alignment. Remarkably, our method exhibits superior performance compared to current state-of-the-art techniques, achieving 87.8% improvement in mAP and closely approaching the performance of fully supervised methods (62.15 mAP vs. 69.02 mAP) on HuCenLife Dataset.
Extreme Two-View Geometry From Object Poses with Diffusion Models
Feb 05, 2024Human has an incredible ability to effortlessly perceive the viewpoint difference between two images containing the same object, even when the viewpoint change is astonishingly vast with no co-visible regions in the images. This remarkable skill, however, has proven to be a challenge for existing camera pose estimation methods, which often fail when faced with large viewpoint differences due to the lack of overlapping local features for matching. In this paper, we aim to effectively harness the power of object priors to accurately determine two-view geometry in the face of extreme viewpoint changes. In our method, we first mathematically transform the relative camera pose estimation problem to an object pose estimation problem. Then, to estimate the object pose, we utilize the object priors learned from a diffusion model Zero123 to synthesize novel-view images of the object. The novel-view images are matched to determine the object pose and thus the two-view camera pose. In experiments, our method has demonstrated extraordinary robustness and resilience to large viewpoint changes, consistently estimating two-view poses with exceptional generalization ability across both synthetic and real-world datasets. Code will be available at https://github.com/scy639/Extreme-Two-View-Geometry-From-Object-Poses-with-Diffusion-Models.