 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDemoiré: Towards Universal Image Demoiréing with Data Generation and Synthesis
Feb 10, 2025Image demoir\'eing poses one of the most formidable challenges in image restoration, primarily due to the unpredictable and anisotropic nature of moir\'e patterns. Limited by the quantity and diversity of training data, current methods tend to overfit to a single moir\'e domain, resulting in performance degradation for new domains and restricting their robustness in real-world applications. In this paper, we propose a universal image demoir\'eing solution, UniDemoir\'e, which has superior generalization capability. Notably, we propose innovative and effective data generation and synthesis methods that can automatically provide vast high-quality moir\'e images to train a universal demoir\'eing model. Our extensive experiments demonstrate the cutting-edge performance and broad potential of our approach for generalized image demoir\'eing.
SAM-guided Unsupervised Domain Adaptation for 3D Segmentation
Oct 16, 2023Unsupervised domain adaptation (UDA) in 3D segmentation tasks presents a formidable challenge, primarily stemming from the sparse and unordered nature of point cloud data. Especially for LiDAR point clouds, the domain discrepancy becomes obvious across varying capture scenes, fluctuating weather conditions, and the diverse array of LiDAR devices in use. While previous UDA methodologies have often sought to mitigate this gap by aligning features between source and target domains, this approach falls short when applied to 3D segmentation due to the substantial domain variations. Inspired by the remarkable generalization capabilities exhibited by the vision foundation model, SAM, in the realm of image segmentation, our approach leverages the wealth of general knowledge embedded within SAM to unify feature representations across diverse 3D domains and further solves the 3D domain adaptation problem. Specifically, we harness the corresponding images associated with point clouds to facilitate knowledge transfer and propose an innovative hybrid feature augmentation methodology, which significantly enhances the alignment between the 3D feature space and SAM's feature space, operating at both the scene and instance levels. Our method is evaluated on many widely-recognized datasets and achieves state-of-the-art performance.
WildRefer: 3D Object Localization in Large-scale Dynamic Scenes with Multi-modal Visual Data and Natural Language
Apr 12, 2023We introduce the task of 3D visual grounding in large-scale dynamic scenes based on natural linguistic descriptions and online captured multi-modal visual data, including 2D images and 3D LiDAR point clouds. We present a novel method, WildRefer, for this task by fully utilizing the appearance features in images, the location and geometry features in point clouds, and the dynamic features in consecutive input frames to match the semantic features in language. In particular, we propose two novel datasets, STRefer and LifeRefer, which focus on large-scale human-centric daily-life scenarios with abundant 3D object and natural language annotations. Our datasets are significant for the research of 3D visual grounding in the wild and has huge potential to boost the development of autonomous driving and service robots. Extensive comparisons and ablation studies illustrate that our method achieves state-of-the-art performance on two proposed datasets. Code and dataset will be released when the paper is published.
CL3D: Unsupervised Domain Adaptation for Cross-LiDAR 3D Detection
Dec 01, 2022Domain adaptation for Cross-LiDAR 3D detection is challenging due to the large gap on the raw data representation with disparate point densities and point arrangements. By exploring domain-invariant 3D geometric characteristics and motion patterns, we present an unsupervised domain adaptation method that overcomes above difficulties. First, we propose the Spatial Geometry Alignment module to extract similar 3D shape geometric features of the same object class to align two domains, while eliminating the effect of distinct point distributions. Second, we present Temporal Motion Alignment module to utilize motion features in sequential frames of data to match two domains. Prototypes generated from two modules are incorporated into the pseudo-label reweighting procedure and contribute to our effective self-training framework for the target domain. Extensive experiments show that our method achieves state-of-the-art performance on cross-device datasets, especially for the datasets with large gaps captured by mechanical scanning LiDARs and solid-state LiDARs in various scenes. Project homepage is at https://github.com/4DVLab/CL3D.git
STCrowd: A Multimodal Dataset for Pedestrian Perception in Crowded Scenes
Apr 03, 2022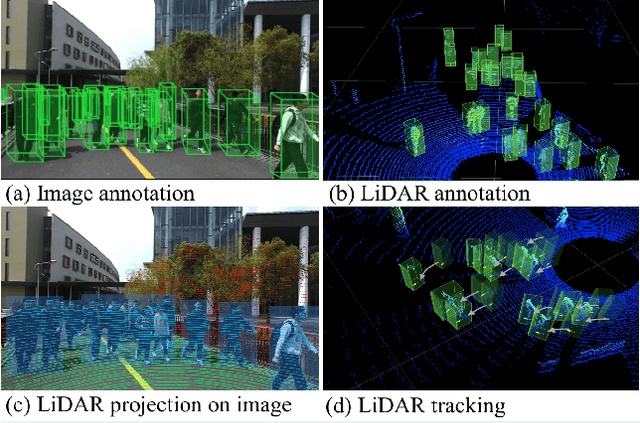
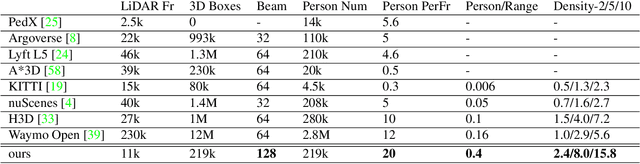

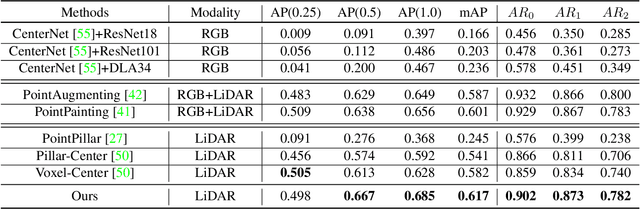
Accurately detecting and tracking pedestrians in 3D space is challenging due to large variations in rotations, poses and scales. The situation becomes even worse for dense crowds with severe occlusions. However, existing benchmarks either only provide 2D annotations, or have limited 3D annotations with low-density pedestrian distribution, making it difficult to build a reliable pedestrian perception system especially in crowded scenes. To better evaluate pedestrian perception algorithms in crowded scenarios, we introduce a large-scale multimodal dataset,STCrowd. Specifically, in STCrowd, there are a total of 219 K pedestrian instances and 20 persons per frame on average, with various levels of occlusion. We provide synchronized LiDAR point clouds and camera images as well as their corresponding 3D labels and joint IDs. STCrowd can be used for various tasks, including LiDAR-only, image-only, and sensor-fusion based pedestrian detection and tracking. We provide baselines for most of the tasks. In addition, considering the property of sparse global distribution and density-varying local distribution of pedestrians, we further propose a novel method, Density-aware Hierarchical heatmap Aggregation (DHA), to enhance pedestrian perception in crowded scenes. Extensive experiments show that our new method achieves state-of-the-art performance for pedestrian detection on various datasets.
SIDE: Center-based Stereo 3D Detector with Structure-aware Instance Depth Estimation
Aug 24, 2021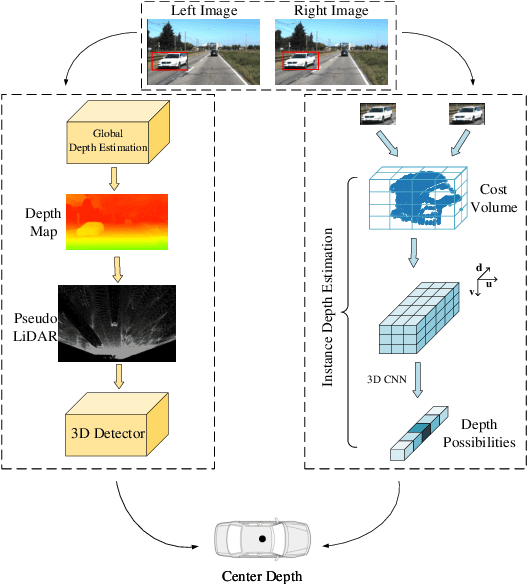
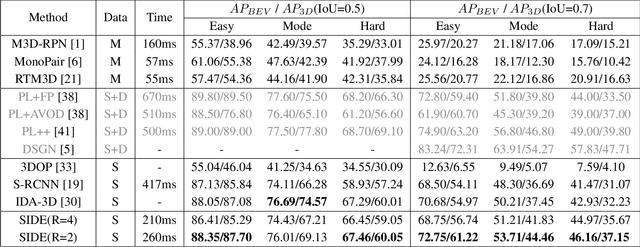
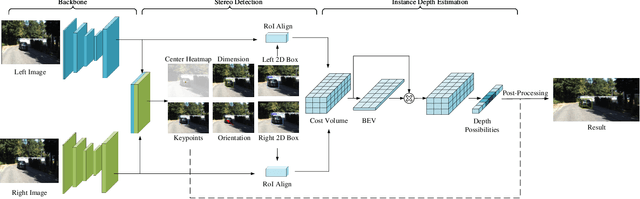
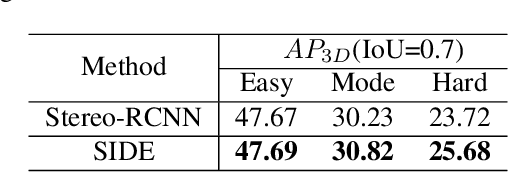
3D detection plays an indispensable role in environment perception. Due to the high cost of commonly used LiDAR sensor, stereo vision based 3D detection, as an economical yet effective setting, attracts more attention recently. For these approaches based on 2D images, accurate depth information is the key to achieve 3D detection, and most existing methods resort to a preliminary stage for depth estimation. They mainly focus on the global depth and neglect the property of depth information in this specific task, namely, sparsity and locality, where exactly accurate depth is only needed for these 3D bounding boxes. Motivated by this finding, we propose a stereo-image based anchor-free 3D detection method, called structure-aware stereo 3D detector (termed as SIDE), where we explore the instance-level depth information via constructing the cost volume from RoIs of each object. Due to the information sparsity of local cost volume, we further introduce match reweighting and structure-aware attention, to make the depth information more concentrated. Experiments conducted on the KITTI dataset show that our method achieves the state-of-the-art performance compared to existing methods without depth map supervision.