 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrack2View: 4D-Consistent Camera-Controlled Video Generation via Paired 3D Point Tracks
Jun 14, 2026Re-rendering an existing video from a novel camera viewpoint requires the output to follow the prescribed camera trajectory while preserving the appearance and dynamics of the original scene across every frame. Existing methods rely on per-frame pose embeddings, noisy point-cloud renderings, or implicit learned correspondences, none of which provides an explicit, temporally continuous link between source and target pixels. We propose Track2View, which conditions a video diffusion transformer on paired 3D point tracks: sparse trajectories of scene points projected into both the source and target camera views. These tracks provide explicit spatiotemporal correspondences that are temporally continuous by construction, encoding what content should appear where and when. At the core of Track2View is a dual-view track conditioner that transfers visual context from source to target view through parameter-free geometric operations and learned temporal aggregation, ensuring generalization to arbitrary camera trajectories without memorizing specific motions. We further introduce a data curation pipeline that extracts one-to-one track correspondences by running a 3D point tracker on temporally concatenated multi-camera view pairs. On a 400-video benchmark spanning static and dynamic scenes, Track2View achieves state-of-the-art results across visual quality, view synchronization, and camera accuracy, reducing rotation error by 30-65% and translation error by 61-72% relative to leading baselines. Project page is available at this https URL: https://qjizhi.github.io/track2view
StereoGenBench: A Synthetic Multi-Camera Benchmark for Stereo Generation under Controlled Baseline Regimes
May 22, 2026Stereo image and video generation, stereo geometry estimation, and condition-controlled view synthesis require paired data in which the variables that determine binocular geometry -- camera baseline, intrinsics, scene depth, and camera motion -- are known and controllable. Existing stereo resources provide subsets of these variables, but resources commonly used for stereo generation evaluation do not, to our knowledge, provide scene-paired, calibrated multi-baseline right-view ground truth with jointly recorded intrinsics, dense metric depth, and per-frame poses in a single controlled source. We introduce StereoGenBench, a synthetic Unreal Engine benchmark designed to make baseline-regime sensitivity and target-camera consistency measurable under matched scene content. Each scene is rendered with a rigid six-camera lateral array, yielding up to 15 calibrated view pairs; adjacent baselines are sampled from inter-pupillary to wide-baseline regimes; focal length is sampled independently; and every view is released with RGB, metric depth, intrinsics, per-pair baselines, and per-frame poses. The splits include two evaluation families for narrow and wide baseline regimes and a train-only family for broader all-pairs coverage. We release the dataset, evaluation code, reference results, Croissant metadata, and generation code/configuration for extension with compatible assets. The dataset is available at https://huggingface.co/datasets/stereo-dataset/stereo-dataset
GenOpticalFlow: A Generative Approach to Unsupervised Optical Flow Learning
Mar 23, 2026Optical flow estimation is a fundamental problem in computer vision, yet the reliance on expensive ground-truth annotations limits the scalability of supervised approaches. Although unsupervised and semi-supervised methods alleviate this issue, they often suffer from unreliable supervision signals based on brightness constancy and smoothness assumptions, leading to inaccurate motion estimation in complex real-world scenarios. To overcome these limitations, we introduce \textbf{\modelname}, a novel framework that synthesizes large-scale, perfectly aligned frame--flow data pairs for supervised optical flow training without human annotations. Specifically, our method leverages a pre-trained depth estimation network to generate pseudo optical flows, which serve as conditioning inputs for a next-frame generation model trained to produce high-fidelity, pixel-aligned subsequent frames. This process enables the creation of abundant, high-quality synthetic data with precise motion correspondence. Furthermore, we propose an \textit{inconsistent pixel filtering} strategy that identifies and removes unreliable pixels in generated frames, effectively enhancing fine-tuning performance on real-world datasets. Extensive experiments on KITTI2012, KITTI2015, and Sintel demonstrate that \textbf{\modelname} achieves competitive or superior results compared to existing unsupervised and semi-supervised approaches, highlighting its potential as a scalable and annotation-free solution for optical flow learning. We will release our code upon acceptance.
Video Understanding: From Geometry and Semantics to Unified Models
Mar 18, 2026Video understanding aims to enable models to perceive, reason about, and interact with the dynamic visual world. In contrast to image understanding, video understanding inherently requires modeling temporal dynamics and evolving visual context, placing stronger demands on spatiotemporal reasoning and making it a foundational problem in computer vision. In this survey, we present a structured overview of video understanding by organizing the literature into three complementary perspectives: low-level video geometry understanding, high-level semantic understanding, and unified video understanding models. We further highlight a broader shift from isolated, task-specific pipelines toward unified modeling paradigms that can be adapted to diverse downstream objectives, enabling a more systematic view of recent progress. By consolidating these perspectives, this survey provides a coherent map of the evolving video understanding landscape, summarizes key modeling trends and design principles, and outlines open challenges toward building robust, scalable, and unified video foundation models.
* A comprehensive survey of video understanding, spanning low-level geometry, high-level semantics, and unified understanding models
PhysAlign: Physics-Coherent Image-to-Video Generation through Feature and 3D Representation Alignment
Mar 14, 2026Video Diffusion Models (VDMs) offer a promising approach for simulating dynamic scenes and environments, with broad applications in robotics and media generation. However, existing models often generate temporally incoherent content that violates basic physical intuition, significantly limiting their practical applicability. We propose PhysAlign, an efficient framework for physics-coherent image-to-video (I2V) generation that explicitly addresses this limitation. To overcome the critical scarcity of physics-annotated videos, we first construct a fully controllable synthetic data generation pipeline based on rigid-body simulation, yielding a highly-curated dataset with accurate, fine-grained physics and 3D annotations. Leveraging this data, PhysAlign constructs a unified physical latent space by coupling explicit 3D geometry constraints with a Gram-based spatio-temporal relational alignment that extracts kinematic priors from video foundation models. Extensive experiments demonstrate that PhysAlign significantly outperforms existing VDMs on tasks requiring complex physical reasoning and temporal stability, without compromising zero-shot visual quality. PhysAlign shows the potential to bridge the gap between raw visual synthesis and rigid-body kinematics, establishing a practical paradigm for genuinely physics-grounded video generation. The project page is available at https://physalign.github.io/PhysAlign.
GenStereo: Towards Open-World Generation of Stereo Images and Unsupervised Matching
Mar 17, 2025Stereo images are fundamental to numerous applications, including extended reality (XR) devices, autonomous driving, and robotics. Unfortunately, acquiring high-quality stereo images remains challenging due to the precise calibration requirements of dual-camera setups and the complexity of obtaining accurate, dense disparity maps. Existing stereo image generation methods typically focus on either visual quality for viewing or geometric accuracy for matching, but not both. We introduce GenStereo, a diffusion-based approach, to bridge this gap. The method includes two primary innovations (1) conditioning the diffusion process on a disparity-aware coordinate embedding and a warped input image, allowing for more precise stereo alignment than previous methods, and (2) an adaptive fusion mechanism that intelligently combines the diffusion-generated image with a warped image, improving both realism and disparity consistency. Through extensive training on 11 diverse stereo datasets, GenStereo demonstrates strong generalization ability. GenStereo achieves state-of-the-art performance in both stereo image generation and unsupervised stereo matching tasks. Our framework eliminates the need for complex hardware setups while enabling high-quality stereo image generation, making it valuable for both real-world applications and unsupervised learning scenarios. Project page is available at https://qjizhi.github.io/genstereo
MCPDepth: Omnidirectional Depth Estimation via Stereo Matching from Multi-Cylindrical Panoramas
Aug 03, 2024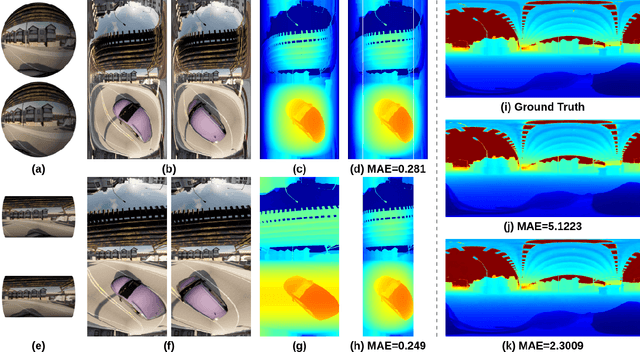
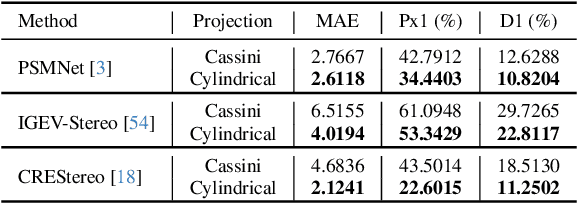
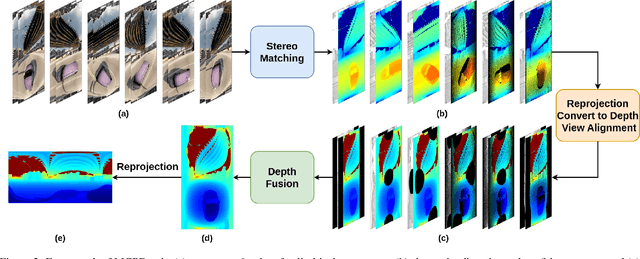
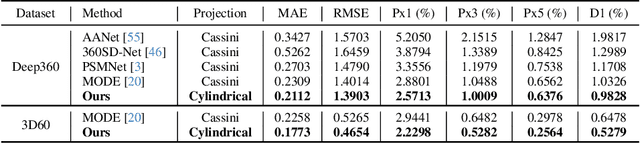
We introduce Multi-Cylindrical Panoramic Depth Estimation (MCPDepth), a two-stage framework for omnidirectional depth estimation via stereo matching between multiple cylindrical panoramas. MCPDepth uses cylindrical panoramas for initial stereo matching and then fuses the resulting depth maps across views. A circular attention module is employed to overcome the distortion along the vertical axis. MCPDepth exclusively utilizes standard network components, simplifying deployment to embedded devices and outperforming previous methods that require custom kernels. We theoretically and experimentally compare spherical and cylindrical projections for stereo matching, highlighting the advantages of the cylindrical projection. MCPDepth achieves state-of-the-art performance with an 18.8% reduction in mean absolute error (MAE) for depth on the outdoor synthetic dataset Deep360 and a 19.9% reduction on the indoor real-scene dataset 3D60.
SAM-guided Unsupervised Domain Adaptation for 3D Segmentation
Oct 16, 2023Unsupervised domain adaptation (UDA) in 3D segmentation tasks presents a formidable challenge, primarily stemming from the sparse and unordered nature of point cloud data. Especially for LiDAR point clouds, the domain discrepancy becomes obvious across varying capture scenes, fluctuating weather conditions, and the diverse array of LiDAR devices in use. While previous UDA methodologies have often sought to mitigate this gap by aligning features between source and target domains, this approach falls short when applied to 3D segmentation due to the substantial domain variations. Inspired by the remarkable generalization capabilities exhibited by the vision foundation model, SAM, in the realm of image segmentation, our approach leverages the wealth of general knowledge embedded within SAM to unify feature representations across diverse 3D domains and further solves the 3D domain adaptation problem. Specifically, we harness the corresponding images associated with point clouds to facilitate knowledge transfer and propose an innovative hybrid feature augmentation methodology, which significantly enhances the alignment between the 3D feature space and SAM's feature space, operating at both the scene and instance levels. Our method is evaluated on many widely-recognized datasets and achieves state-of-the-art performance.
StereoFlowGAN: Co-training for Stereo and Flow with Unsupervised Domain Adaptation
Sep 04, 2023



We introduce a novel training strategy for stereo matching and optical flow estimation that utilizes image-to-image translation between synthetic and real image domains. Our approach enables the training of models that excel in real image scenarios while relying solely on ground-truth information from synthetic images. To facilitate task-agnostic domain adaptation and the training of task-specific components, we introduce a bidirectional feature warping module that handles both left-right and forward-backward directions. Experimental results show competitive performance over previous domain translation-based methods, which substantiate the efficacy of our proposed framework, effectively leveraging the benefits of unsupervised domain adaptation, stereo matching, and optical flow estimation.
DUFormer: A Novel Architecture for Power Line Segmentation of Aerial Images
Apr 12, 2023Power lines pose a significant safety threat to unmanned aerial vehicles (UAVs) operating at low altitudes. However, detecting power lines in aerial images is challenging due to the small size of the foreground data (i.e., power lines) and the abundance of background information. To address this challenge, we propose DUFormer, a semantic segmentation algorithm designed specifically for power line detection in aerial images. We assume that performing sufficient feature extraction with a convolutional neural network (CNN) that has a strong inductive bias is beneficial for training an efficient Transformer model. To this end, we propose a heavy token encoder responsible for overlapping feature re-mining and tokenization. The encoder comprises a pyramid CNN feature extraction module and a power line feature enhancement module. Following sufficient feature extraction for power lines, the feature fusion is carried out, and then the Transformer block is used for global modeling. The final segmentation result is obtained by fusing local and global features in the decode head. Additionally, we demonstrate the significance of the joint multi-weight loss function in power line segmentation. The experimental results demonstrate that our proposed method achieves the state-of-the-art performance in power line segmentation on the publicly available TTPLA dataset.