 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Transfer with Self-Supervised Spectral-Spatial Modeling for Hyperspectral Image Classification
Jan 26, 2026Self-supervised learning has demonstrated considerable potential in hyperspectral representation, yet its application in cross-domain transfer scenarios remains under-explored. Existing methods, however, still rely on source domain annotations and are susceptible to distribution shifts, leading to degraded generalization performance in the target domain. To address this, this paper proposes a self-supervised cross-domain transfer framework that learns transferable spectral-spatial joint representations without source labels and achieves efficient adaptation under few samples in the target domain. During the self-supervised pre-training phase, a Spatial-Spectral Transformer (S2Former) module is designed. It adopts a dual-branch spatial-spectral transformer and introduces a bidirectional cross-attention mechanism to achieve spectral-spatial collaborative modeling: the spatial branch enhances structural awareness through random masking, while the spectral branch captures fine-grained differences. Both branches mutually guide each other to improve semantic consistency. We further propose a Frequency Domain Constraint (FDC) to maintain frequency-domain consistency through real Fast Fourier Transform (rFFT) and high-frequency magnitude loss, thereby enhancing the model's capability to discern fine details and boundaries. During the fine-tuning phase, we introduce a Diffusion-Aligned Fine-tuning (DAFT) distillation mechanism. This aligns semantic evolution trajectories through a teacher-student structure, enabling robust transfer learning under low-label conditions. Experimental results demonstrate stable classification performance and strong cross-domain adaptability across four hyperspectral datasets, validating the method's effectiveness under resource-constrained conditions.
Style Adaptation for Domain-adaptive Semantic Segmentation
Apr 25, 2024Unsupervised Domain Adaptation (UDA) refers to the method that utilizes annotated source domain data and unlabeled target domain data to train a model capable of generalizing to the target domain data. Domain discrepancy leads to a significant decrease in the performance of general network models trained on the source domain data when applied to the target domain. We introduce a straightforward approach to mitigate the domain discrepancy, which necessitates no additional parameter calculations and seamlessly integrates with self-training-based UDA methods. Through the transfer of the target domain style to the source domain in the latent feature space, the model is trained to prioritize the target domain style during the decision-making process. We tackle the problem at both the image-level and shallow feature map level by transferring the style information from the target domain to the source domain data. As a result, we obtain a model that exhibits superior performance on the target domain. Our method yields remarkable enhancements in the state-of-the-art performance for synthetic-to-real UDA tasks. For example, our proposed method attains a noteworthy UDA performance of 76.93 mIoU on the GTA->Cityscapes dataset, representing a notable improvement of +1.03 percentage points over the previous state-of-the-art results.
DUFormer: A Novel Architecture for Power Line Segmentation of Aerial Images
Apr 12, 2023Power lines pose a significant safety threat to unmanned aerial vehicles (UAVs) operating at low altitudes. However, detecting power lines in aerial images is challenging due to the small size of the foreground data (i.e., power lines) and the abundance of background information. To address this challenge, we propose DUFormer, a semantic segmentation algorithm designed specifically for power line detection in aerial images. We assume that performing sufficient feature extraction with a convolutional neural network (CNN) that has a strong inductive bias is beneficial for training an efficient Transformer model. To this end, we propose a heavy token encoder responsible for overlapping feature re-mining and tokenization. The encoder comprises a pyramid CNN feature extraction module and a power line feature enhancement module. Following sufficient feature extraction for power lines, the feature fusion is carried out, and then the Transformer block is used for global modeling. The final segmentation result is obtained by fusing local and global features in the decode head. Additionally, we demonstrate the significance of the joint multi-weight loss function in power line segmentation. The experimental results demonstrate that our proposed method achieves the state-of-the-art performance in power line segmentation on the publicly available TTPLA dataset.
Keypoint Encoding for Improved Feature Extraction from Compressed Video at Low Bitrates
Mar 04, 2016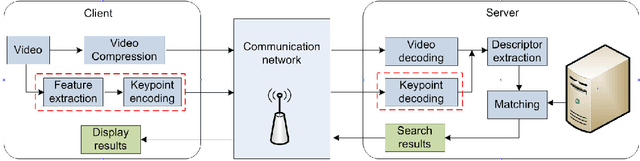
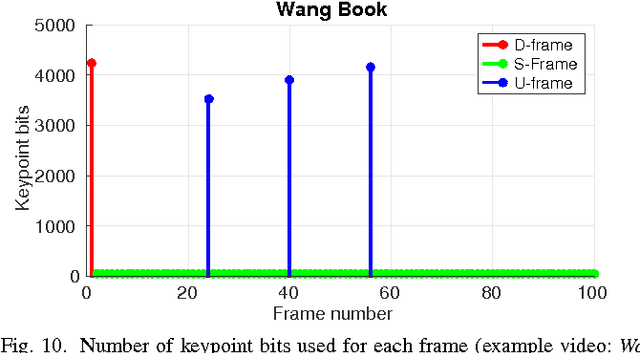
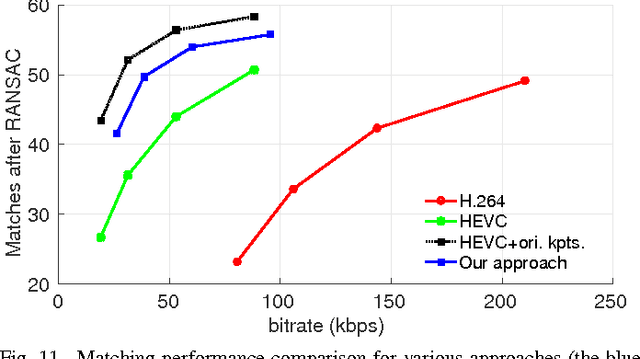
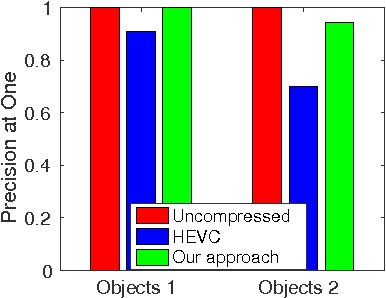
In many mobile visual analysis applications, compressed video is transmitted over a communication network and analyzed by a server. Typical processing steps performed at the server include keypoint detection, descriptor calculation, and feature matching. Video compression has been shown to have an adverse effect on feature-matching performance. The negative impact of compression can be reduced by using the keypoints extracted from the uncompressed video to calculate descriptors from the compressed video. Based on this observation, we propose to provide these keypoints to the server as side information and to extract only the descriptors from the compressed video. First, we introduce four different frame types for keypoint encoding to address different types of changes in video content. These frame types represent a new scene, the same scene, a slowly changing scene, or a rapidly moving scene and are determined by comparing features between successive video frames. Then, we propose Intra, Skip and Inter modes of encoding the keypoints for different frame types. For example, keypoints for new scenes are encoded using the Intra mode, and keypoints for unchanged scenes are skipped. As a result, the bitrate of the side information related to keypoint encoding is significantly reduced. Finally, we present pairwise matching and image retrieval experiments conducted to evaluate the performance of the proposed approach using the Stanford mobile augmented reality dataset and 720p format videos. The results show that the proposed approach offers significantly improved feature matching and image retrieval performance at a given bitrate.