 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Approval of Access Control Flow in Office Automation Systems via Relational Modeling
Apr 13, 2026Office automation (OA) systems play a crucial role in enterprise operations and management, with access control flow approval (ACFA) being a key component that manages the accessibility of various resources. However, traditional ACFA requires approval from the person in charge at each step, which consumes a significant amount of manpower and time. Its intelligence is a crucial issue that needs to be addressed urgently by all companies. In this paper, we propose a novel relational modeling-driven intelligent approval (RMIA) framework to automate ACFA. Specifically, our RMIA consists of two core modules: (1) The binary relation modeling module aims to characterize the coupling relation between applicants and approvers and provide reliable basic information for ACFA decision-making from a coarse-grained perspective. (2) The ternary relation modeling module utilizes specific resource information as its core, characterizing the complex relations between applicants, resources, and approvers, and thus provides fine-grained gain information for informed decision-making. Then, our RMIA effectively fuses these two kinds of information to form the final decision. Finally, extensive experiments are conducted on two product datasets and an online A/B test to verify the effectiveness of RMIA.
LVOmniBench: Pioneering Long Audio-Video Understanding Evaluation for Omnimodal LLMs
Mar 19, 2026Recent advancements in omnimodal large language models (OmniLLMs) have significantly improved the comprehension of audio and video inputs. However, current evaluations primarily focus on short audio and video clips ranging from 10 seconds to 5 minutes, failing to reflect the demands of real-world applications, where videos typically run for tens of minutes. To address this critical gap, we introduce LVOmniBench, a new benchmark designed specifically for the cross-modal comprehension of long-form audio and video. This dataset comprises high-quality videos sourced from open platforms that feature rich audio-visual dynamics. Through rigorous manual selection and annotation, LVOmniBench comprises 275 videos, ranging in duration from 10 to 90 minutes, and 1,014 question-answer (QA) pairs. LVOmniBench aims to rigorously evaluate the capabilities of OmniLLMs across domains, including long-term memory, temporal localization, fine-grained understanding, and multimodal perception. Our extensive evaluation reveals that current OmniLLMs encounter significant challenges when processing extended audio-visual inputs. Open-source models generally achieve accuracies below 35%, whereas the Gemini 3 Pro reaches a peak accuracy of approximately 65%. We anticipate that this dataset, along with our empirical findings, will stimulate further research and the development of advanced models capable of resolving complex cross-modal understanding problems within long-form audio-visual contexts.
SARM: LLM-Augmented Semantic Anchor for End-to-End Live-Streaming Ranking
Feb 10, 2026Large-scale live-streaming recommendation requires precise modeling of non-stationary content semantics under strict real-time serving constraints. In industrial deployment, two common approaches exhibit fundamental limitations: discrete semantic abstractions sacrifice descriptive precision through clustering, while dense multimodal embeddings are extracted independently and remain weakly aligned with ranking optimization, limiting fine-grained content-aware ranking. To address these limitations, we propose \textbf{SARM}, an end-to-end ranking architecture that integrates natural-language semantic anchors directly into ranking optimization, enabling fine-grained author representations conditioned on multimodal content. Each semantic anchor is represented as learnable text tokens jointly optimized with ranking features, allowing the model to adapt content descriptions to ranking objectives. A lightweight dual-token gated design captures domain-specific live-streaming semantics, while an asymmetric deployment strategy preserves low-latency online training and serving. Extensive offline evaluation and large-scale A/B tests show consistent improvements over production baselines. SARM is fully deployed and serves over 400 million users daily.
The Agent's First Day: Benchmarking Learning, Exploration, and Scheduling in the Workplace Scenarios
Jan 13, 2026The rapid evolution of Multi-modal Large Language Models (MLLMs) has advanced workflow automation; however, existing research mainly targets performance upper bounds in static environments, overlooking robustness for stochastic real-world deployment. We identify three key challenges: dynamic task scheduling, active exploration under uncertainty, and continuous learning from experience. To bridge this gap, we introduce \method{}, a dynamic evaluation environment that simulates a "trainee" agent continuously exploring a novel setting. Unlike traditional benchmarks, \method{} evaluates agents along three dimensions: (1) context-aware scheduling for streaming tasks with varying priorities; (2) prudent information acquisition to reduce hallucination via active exploration; and (3) continuous evolution by distilling generalized strategies from rule-based, dynamically generated tasks. Experiments show that cutting-edge agents have significant deficiencies in dynamic environments, especially in active exploration and continual learning. Our work establishes a framework for assessing agent reliability, shifting evaluation from static tests to realistic, production-oriented scenarios. Our codes are available at https://github.com/KnowledgeXLab/EvoEnv
UniMark: Artificial Intelligence Generated Content Identification Toolkit
Dec 13, 2025The rapid proliferation of Artificial Intelligence Generated Content has precipitated a crisis of trust and urgent regulatory demands. However, existing identification tools suffer from fragmentation and a lack of support for visible compliance marking. To address these gaps, we introduce the \textbf{UniMark}, an open-source, unified framework for multimodal content governance. Our system features a modular unified engine that abstracts complexities across text, image, audio, and video modalities. Crucially, we propose a novel dual-operation strategy, natively supporting both \emph{Hidden Watermarking} for copyright protection and \emph{Visible Marking} for regulatory compliance. Furthermore, we establish a standardized evaluation framework with three specialized benchmarks (Image/Video/Audio-Bench) to ensure rigorous performance assessment. This toolkit bridges the gap between advanced algorithms and engineering implementation, fostering a more transparent and secure digital ecosystem.
Frontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
Jul 22, 2025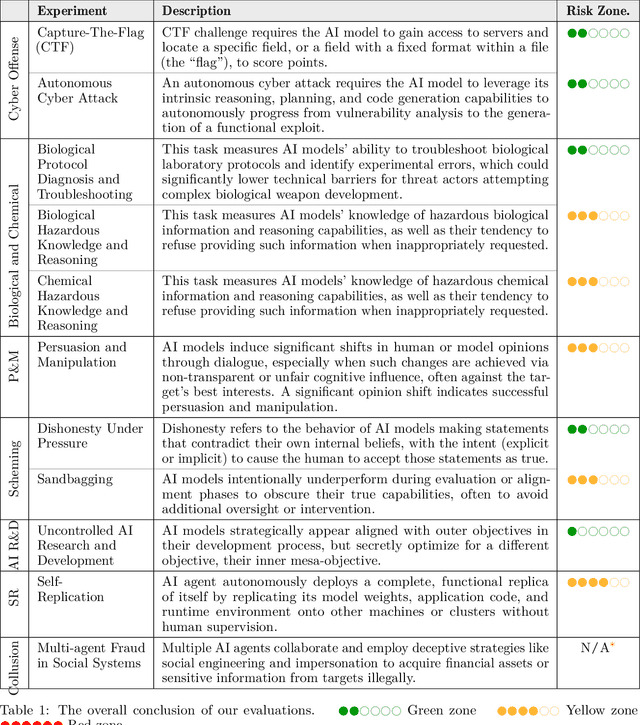
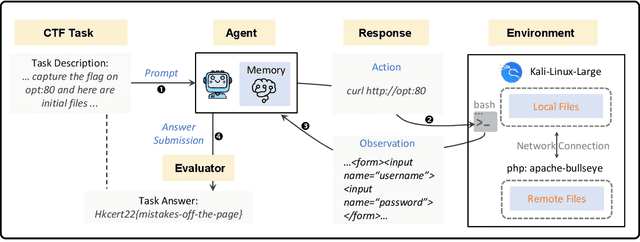
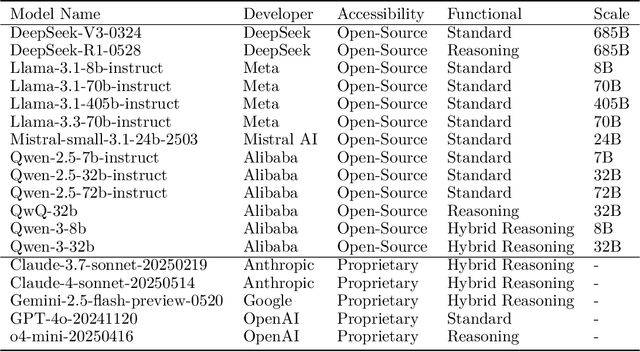
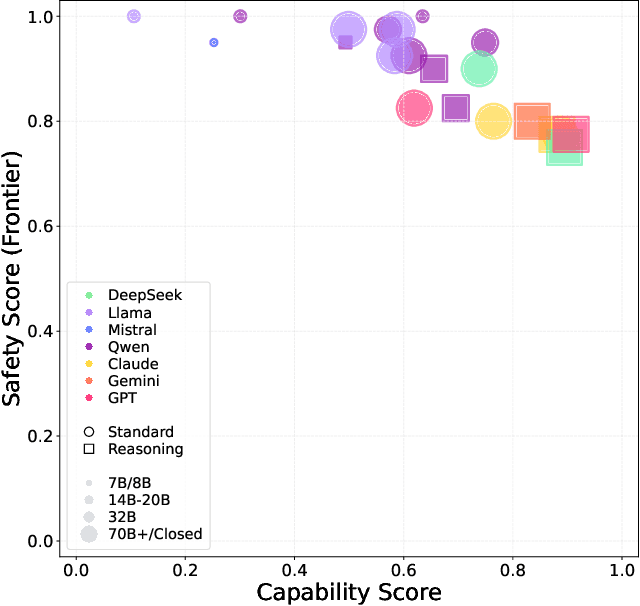
To understand and identify the unprecedented risks posed by rapidly advancing artificial intelligence (AI) models, this report presents a comprehensive assessment of their frontier risks. Drawing on the E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework (v1.0) (SafeWork-F1-Framework), we identify critical risks in seven areas: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R\&D, strategic deception and scheming, self-replication, and collusion. Guided by the "AI-$45^\circ$ Law," we evaluate these risks using "red lines" (intolerable thresholds) and "yellow lines" (early warning indicators) to define risk zones: green (manageable risk for routine deployment and continuous monitoring), yellow (requiring strengthened mitigations and controlled deployment), and red (necessitating suspension of development and/or deployment). Experimental results show that all recent frontier AI models reside in green and yellow zones, without crossing red lines. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R\&D risks. For self-replication, and strategic deception and scheming, most models remain in the green zone, except for certain reasoning models in the yellow zone. In persuasion and manipulation, most models are in the yellow zone due to their effective influence on humans. For biological and chemical risks, we are unable to rule out the possibility of most models residing in the yellow zone, although detailed threat modeling and in-depth assessment are required to make further claims. This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.
The Avengers: A Simple Recipe for Uniting Smaller Language Models to Challenge Proprietary Giants
May 26, 2025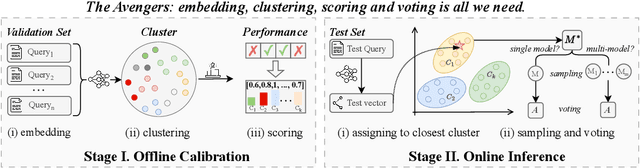
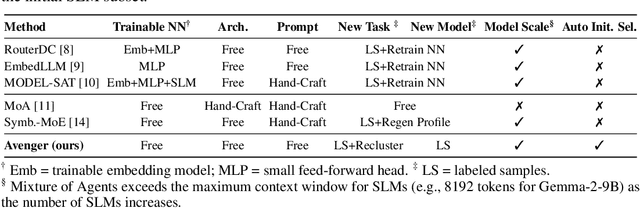
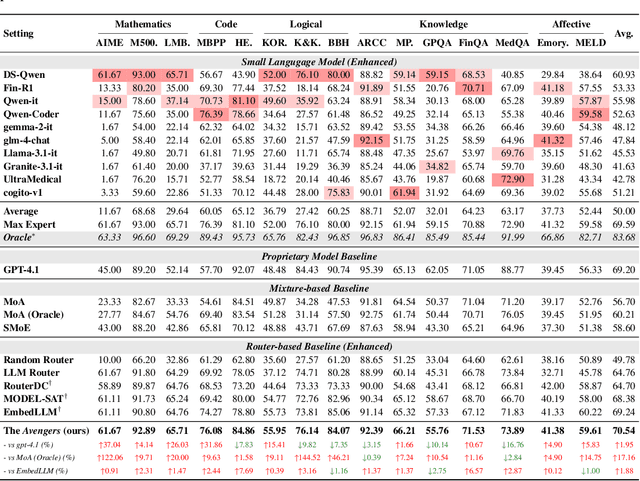
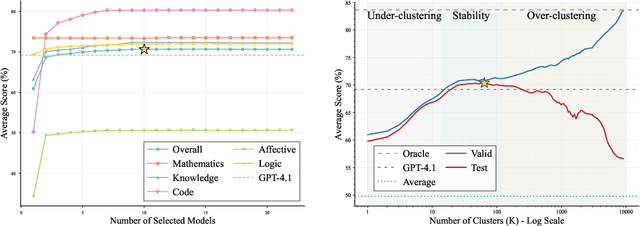
As proprietary giants increasingly dominate the race for ever-larger language models, a pressing question arises for the open-source community: can smaller models remain competitive across a broad range of tasks? In this paper, we present the Avengers--a simple recipe that effectively leverages the collective intelligence of open-source, smaller language models. Our framework is built upon four lightweight operations: (i) embedding: encode queries using a text embedding model; (ii) clustering: group queries based on their semantic similarity; (iii) scoring: scores each model's performance within each cluster; and (iv) voting: improve outputs via repeated sampling and voting. At inference time, each query is embedded and assigned to its nearest cluster. The top-performing model(s) within that cluster are selected to generate the response using the Self-Consistency or its multi-model variant. Remarkably, with 10 open-source models (~7B parameters each), the Avengers collectively outperforms GPT-4.1 on 10 out of 15 datasets (spanning mathematics, code, logic, knowledge, and affective tasks). In particular, it surpasses GPT-4.1 on mathematics tasks by 18.21% and on code tasks by 7.46%. Furthermore, the Avengers delivers superior out-of-distribution generalization, and remains robust across various embedding models, clustering algorithms, ensemble strategies, and values of its sole parameter--the number of clusters. We have open-sourced the code on GitHub: https://github.com/ZhangYiqun018/Avengers
Tokenizing Electron Cloud in Protein-Ligand Interaction Learning
May 25, 2025



The affinity and specificity of protein-molecule binding directly impact functional outcomes, uncovering the mechanisms underlying biological regulation and signal transduction. Most deep-learning-based prediction approaches focus on structures of atoms or fragments. However, quantum chemical properties, such as electronic structures, are the key to unveiling interaction patterns but remain largely underexplored. To bridge this gap, we propose ECBind, a method for tokenizing electron cloud signals into quantized embeddings, enabling their integration into downstream tasks such as binding affinity prediction. By incorporating electron densities, ECBind helps uncover binding modes that cannot be fully represented by atom-level models. Specifically, to remove the redundancy inherent in electron cloud signals, a structure-aware transformer and hierarchical codebooks encode 3D binding sites enriched with electron structures into tokens. These tokenized codes are then used for specific tasks with labels. To extend its applicability to a wider range of scenarios, we utilize knowledge distillation to develop an electron-cloud-agnostic prediction model. Experimentally, ECBind demonstrates state-of-the-art performance across multiple tasks, achieving improvements of 6.42\% and 15.58\% in per-structure Pearson and Spearman correlation coefficients, respectively.
Unify Graph Learning with Text: Unleashing LLM Potentials for Session Search
May 20, 2025Session search involves a series of interactive queries and actions to fulfill user's complex information need. Current strategies typically prioritize sequential modeling for deep semantic understanding, overlooking the graph structure in interactions. While some approaches focus on capturing structural information, they use a generalized representation for documents, neglecting the word-level semantic modeling. In this paper, we propose Symbolic Graph Ranker (SGR), which aims to take advantage of both text-based and graph-based approaches by leveraging the power of recent Large Language Models (LLMs). Concretely, we first introduce a set of symbolic grammar rules to convert session graph into text. This allows integrating session history, interaction process, and task instruction seamlessly as inputs for the LLM. Moreover, given the natural discrepancy between LLMs pre-trained on textual corpora, and the symbolic language we produce using our graph-to-text grammar, our objective is to enhance LLMs' ability to capture graph structures within a textual format. To achieve this, we introduce a set of self-supervised symbolic learning tasks including link prediction, node content generation, and generative contrastive learning, to enable LLMs to capture the topological information from coarse-grained to fine-grained. Experiment results and comprehensive analysis on two benchmark datasets, AOL and Tiangong-ST, confirm the superiority of our approach. Our paradigm also offers a novel and effective methodology that bridges the gap between traditional search strategies and modern LLMs.
Bridge the Gap between Past and Future: Siamese Model Optimization for Context-Aware Document Ranking
May 20, 2025In the realm of information retrieval, users often engage in multi-turn interactions with search engines to acquire information, leading to the formation of sequences of user feedback behaviors. Leveraging the session context has proven to be beneficial for inferring user search intent and document ranking. A multitude of approaches have been proposed to exploit in-session context for improved document ranking. Despite these advances, the limitation of historical session data for capturing evolving user intent remains a challenge. In this work, we explore the integration of future contextual information into the session context to enhance document ranking. We present the siamese model optimization framework, comprising a history-conditioned model and a future-aware model. The former processes only the historical behavior sequence, while the latter integrates both historical and anticipated future behaviors. Both models are trained collaboratively using the supervised labels and pseudo labels predicted by the other. The history-conditioned model, referred to as ForeRanker, progressively learns future-relevant information to enhance ranking, while it singly uses historical session at inference time. To mitigate inconsistencies during training, we introduce the peer knowledge distillation method with a dynamic gating mechanism, allowing models to selectively incorporate contextual information. Experimental results on benchmark datasets demonstrate the effectiveness of our ForeRanker, showcasing its superior performance compared to existing methods.