 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA hybrid framework for effective and efficient machine unlearning
Dec 19, 2024Recently machine unlearning (MU) is proposed to remove the imprints of revoked samples from the already trained model parameters, to solve users' privacy concern. Different from the runtime expensive retraining from scratch, there exist two research lines, exact MU and approximate MU with different favorites in terms of accuracy and efficiency. In this paper, we present a novel hybrid strategy on top of them to achieve an overall success. It implements the unlearning operation with an acceptable computation cost, while simultaneously improving the accuracy as much as possible. Specifically, it runs reasonable unlearning techniques by estimating the retraining workloads caused by revocations. If the workload is lightweight, it performs retraining to derive the model parameters consistent with the accurate ones retrained from scratch. Otherwise, it outputs the unlearned model by directly modifying the current parameters, for better efficiency. In particular, to improve the accuracy in the latter case, we propose an optimized version to amend the output model with lightweight runtime penalty. We particularly study the boundary of two approaches in our frameworks to adaptively make the smart selection. Extensive experiments on real datasets validate that our proposals can improve the unlearning efficiency by 1.5$\times$ to 8$\times$ while achieving comparable accuracy.
Enhancing the Transferability via Feature-Momentum Adversarial Attack
Apr 22, 2022

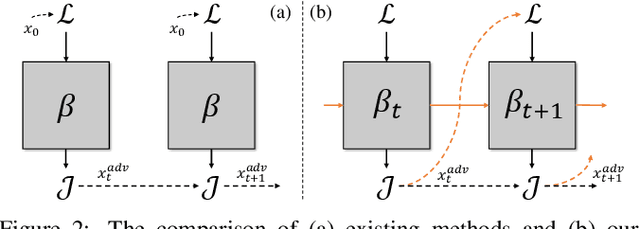
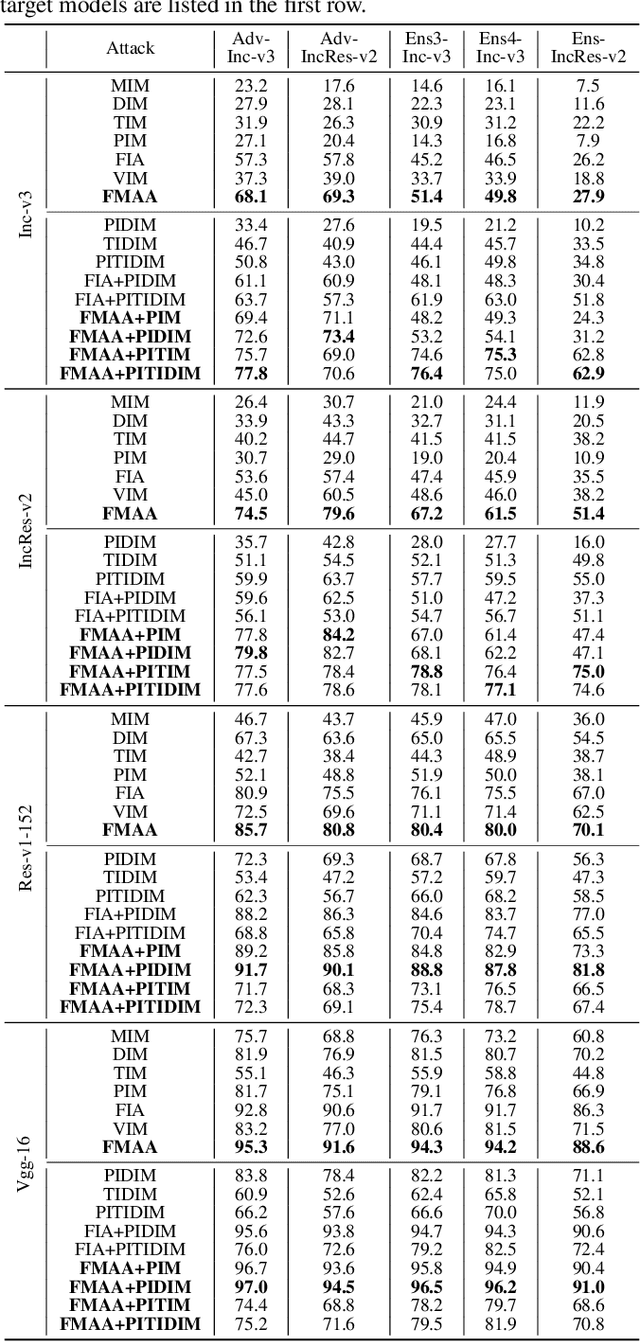
Transferable adversarial attack has drawn increasing attention due to their practical threaten to real-world applications. In particular, the feature-level adversarial attack is one recent branch that can enhance the transferability via disturbing the intermediate features. The existing methods usually create a guidance map for features, where the value indicates the importance of the corresponding feature element and then employs an iterative algorithm to disrupt the features accordingly. However, the guidance map is fixed in existing methods, which can not consistently reflect the behavior of networks as the image is changed during iteration. In this paper, we describe a new method called Feature-Momentum Adversarial Attack (FMAA) to further improve transferability. The key idea of our method is that we estimate a guidance map dynamically at each iteration using momentum to effectively disturb the category-relevant features. Extensive experiments demonstrate that our method significantly outperforms other state-of-the-art methods by a large margin on different target models.