 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZK-HybridFL: Zero-Knowledge Proof-Enhanced Hybrid Ledger for Federated Learning
Jan 29, 2026Federated learning (FL) enables collaborative model training while preserving data privacy, yet both centralized and decentralized approaches face challenges in scalability, security, and update validation. We propose ZK-HybridFL, a secure decentralized FL framework that integrates a directed acyclic graph (DAG) ledger with dedicated sidechains and zero-knowledge proofs (ZKPs) for privacy-preserving model validation. The framework uses event-driven smart contracts and an oracle-assisted sidechain to verify local model updates without exposing sensitive data. A built-in challenge mechanism efficiently detects adversarial behavior. In experiments on image classification and language modeling tasks, ZK-HybridFL achieves faster convergence, higher accuracy, lower perplexity, and reduced latency compared to Blade-FL and ChainFL. It remains robust against substantial fractions of adversarial and idle nodes, supports sub-second on-chain verification with efficient gas usage, and prevents invalid updates and orphanage-style attacks. This makes ZK-HybridFL a scalable and secure solution for decentralized FL across diverse environments.
LiViBench: An Omnimodal Benchmark for Interactive Livestream Video Understanding
Jan 21, 2026The development of multimodal large language models (MLLMs) has advanced general video understanding. However, existing video evaluation benchmarks primarily focus on non-interactive videos, such as movies and recordings. To fill this gap, this paper proposes the first omnimodal benchmark for interactive livestream videos, LiViBench. It features a diverse set of 24 tasks, highlighting the perceptual, reasoning, and livestream-specific challenges. To efficiently construct the dataset, we design a standardized semi-automatic annotation workflow that incorporates the human-in-the-loop at multiple stages. The workflow leverages multiple MLLMs to form a multi-agent system for comprehensive video description and uses a seed-question-driven method to construct high-quality annotations. All interactive videos in the benchmark include audio, speech, and real-time comments modalities. To enhance models' understanding of interactive videos, we design tailored two-stage instruction-tuning and propose a Video-to-Comment Retrieval (VCR) module to improve the model's ability to utilize real-time comments. Based on these advancements, we develop LiVi-LLM-7B, an MLLM with enhanced knowledge of interactive livestreams. Experiments show that our model outperforms larger open-source models with up to 72B parameters, narrows the gap with leading proprietary models on LiViBench, and achieves enhanced performance on general video benchmarks, including VideoMME, LongVideoBench, MLVU, and VideoEval-Pro.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
SiamMM: A Mixture Model Perspective on Deep Unsupervised Learning
Nov 07, 2025Recent studies have demonstrated the effectiveness of clustering-based approaches for self-supervised and unsupervised learning. However, the application of clustering is often heuristic, and the optimal methodology remains unclear. In this work, we establish connections between these unsupervised clustering methods and classical mixture models from statistics. Through this framework, we demonstrate significant enhancements to these clustering methods, leading to the development of a novel model named SiamMM. Our method attains state-of-the-art performance across various self-supervised learning benchmarks. Inspection of the learned clusters reveals a strong resemblance to unseen ground truth labels, uncovering potential instances of mislabeling.
Texture-aware Intrinsic Image Decomposition with Model- and Learning-based Priors
Sep 11, 2025This paper aims to recover the intrinsic reflectance layer and shading layer given a single image. Though this intrinsic image decomposition problem has been studied for decades, it remains a significant challenge in cases of complex scenes, i.e. spatially-varying lighting effect and rich textures. In this paper, we propose a novel method for handling severe lighting and rich textures in intrinsic image decomposition, which enables to produce high-quality intrinsic images for real-world images. Specifically, we observe that previous learning-based methods tend to produce texture-less and over-smoothing intrinsic images, which can be used to infer the lighting and texture information given a RGB image. In this way, we design a texture-guided regularization term and formulate the decomposition problem into an optimization framework, to separate the material textures and lighting effect. We demonstrate that combining the novel texture-aware prior can produce superior results to existing approaches.
Plug-and-play Diffusion Models for Image Compressive Sensing with Data Consistency Projection
Sep 11, 2025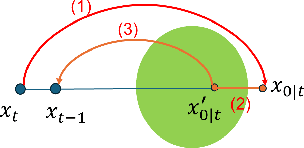
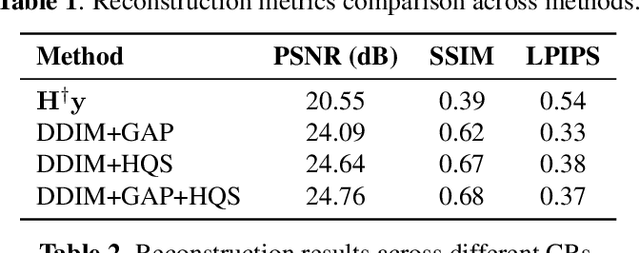

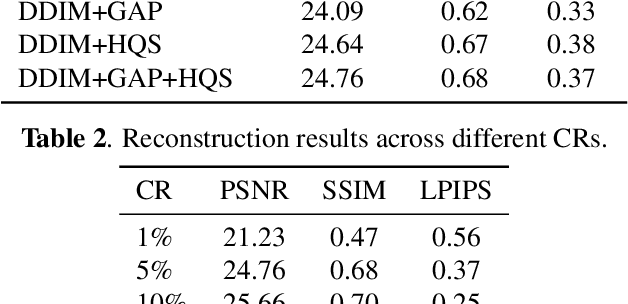
We explore the connection between Plug-and-Play (PnP) methods and Denoising Diffusion Implicit Models (DDIM) for solving ill-posed inverse problems, with a focus on single-pixel imaging. We begin by identifying key distinctions between PnP and diffusion models-particularly in their denoising mechanisms and sampling procedures. By decoupling the diffusion process into three interpretable stages: denoising, data consistency enforcement, and sampling, we provide a unified framework that integrates learned priors with physical forward models in a principled manner. Building upon this insight, we propose a hybrid data-consistency module that linearly combines multiple PnP-style fidelity terms. This hybrid correction is applied directly to the denoised estimate, improving measurement consistency without disrupting the diffusion sampling trajectory. Experimental results on single-pixel imaging tasks demonstrate that our method achieves better reconstruction quality.
Unfolding Framework with Complex-Valued Deformable Attention for High-Quality Computer-Generated Hologram Generation
Aug 29, 2025Computer-generated holography (CGH) has gained wide attention with deep learning-based algorithms. However, due to its nonlinear and ill-posed nature, challenges remain in achieving accurate and stable reconstruction. Specifically, ($i$) the widely used end-to-end networks treat the reconstruction model as a black box, ignoring underlying physical relationships, which reduces interpretability and flexibility. ($ii$) CNN-based CGH algorithms have limited receptive fields, hindering their ability to capture long-range dependencies and global context. ($iii$) Angular spectrum method (ASM)-based models are constrained to finite near-fields.In this paper, we propose a Deep Unfolding Network (DUN) that decomposes gradient descent into two modules: an adaptive bandwidth-preserving model (ABPM) and a phase-domain complex-valued denoiser (PCD), providing more flexibility. ABPM allows for wider working distances compared to ASM-based methods. At the same time, PCD leverages its complex-valued deformable self-attention module to capture global features and enhance performance, achieving a PSNR over 35 dB. Experiments on simulated and real data show state-of-the-art results.
See What You Need: Query-Aware Visual Intelligence through Reasoning-Perception Loops
Aug 25, 2025Human video comprehension demonstrates dynamic coordination between reasoning and visual attention, adaptively focusing on query-relevant details. However, current long-form video question answering systems employ rigid pipelines that decouple reasoning from perception, leading to either information loss through premature visual abstraction or computational inefficiency through exhaustive processing. The core limitation lies in the inability to adapt visual extraction to specific reasoning requirements, different queries demand fundamentally different visual evidence from the same video content. In this work, we present CAVIA, a training-free framework that revolutionizes video understanding through reasoning, perception coordination. Unlike conventional approaches where visual processing operates independently of reasoning, CAVIA creates a closed-loop system where reasoning continuously guides visual extraction based on identified information gaps. CAVIA introduces three innovations: (1) hierarchical reasoning, guided localization to precise frames; (2) cross-modal semantic bridging for targeted extraction; (3) confidence-driven iterative synthesis. CAVIA achieves state-of-the-art performance on challenging benchmarks: EgoSchema (65.7%, +5.3%), NExT-QA (76.1%, +2.6%), and IntentQA (73.8%, +6.9%), demonstrating that dynamic reasoning-perception coordination provides a scalable paradigm for video understanding.
Efficient Speculative Decoding for Llama at Scale: Challenges and Solutions
Aug 11, 2025Speculative decoding is a standard method for accelerating the inference speed of large language models. However, scaling it for production environments poses several engineering challenges, including efficiently implementing different operations (e.g., tree attention and multi-round speculative decoding) on GPU. In this paper, we detail the training and inference optimization techniques that we have implemented to enable EAGLE-based speculative decoding at a production scale for Llama models. With these changes, we achieve a new state-of-the-art inference latency for Llama models. For example, Llama4 Maverick decodes at a speed of about 4 ms per token (with a batch size of one) on 8 NVIDIA H100 GPUs, which is 10% faster than the previously best known method. Furthermore, for EAGLE-based speculative decoding, our optimizations enable us to achieve a speed-up for large batch sizes between 1.4x and 2.0x at production scale.
Align-for-Fusion: Harmonizing Triple Preferences via Dual-oriented Diffusion for Cross-domain Sequential Recommendation
Aug 07, 2025Personalized sequential recommendation aims to predict appropriate items for users based on their behavioral sequences. To alleviate data sparsity and interest drift issues, conventional approaches typically incorporate auxiliary behaviors from other domains via cross-domain transition. However, existing cross-domain sequential recommendation (CDSR) methods often follow an align-then-fusion paradigm that performs representation-level alignment across multiple domains and combines them mechanically for recommendation, overlooking the fine-grained fusion of domain-specific preferences. Inspired by recent advances in diffusion models (DMs) for distribution matching, we propose an align-for-fusion framework for CDSR to harmonize triple preferences via dual-oriented DMs, termed HorizonRec. Specifically, we investigate the uncertainty injection of DMs and identify stochastic noise as a key source of instability in existing DM-based recommenders. To address this, we introduce a mixed-conditioned distribution retrieval strategy that leverages distributions retrieved from users' authentic behavioral logic as semantic bridges across domains, enabling consistent multi-domain preference modeling. Furthermore, we propose a dual-oriented preference diffusion method to suppress potential noise and emphasize target-relevant interests during multi-domain user representation fusion. Extensive experiments on four CDSR datasets from two distinct platforms demonstrate the effectiveness and robustness of HorizonRec in fine-grained triple-domain preference fusion.