 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupporting renewable energy planning and operation with data-driven high-resolution ensemble weather forecast
May 07, 2025The planning and operation of renewable energy, especially wind power, depend crucially on accurate, timely, and high-resolution weather information. Coarse-grid global numerical weather forecasts are typically downscaled to meet these requirements, introducing challenges of scale inconsistency, process representation error, computation cost, and entanglement of distinct uncertainty sources from chaoticity, model bias, and large-scale forcing. We address these challenges by learning the climatological distribution of a target wind farm using its high-resolution numerical weather simulations. An optimal combination of this learned high-resolution climatological prior with coarse-grid large scale forecasts yields highly accurate, fine-grained, full-variable, large ensemble of weather pattern forecasts. Using observed meteorological records and wind turbine power outputs as references, the proposed methodology verifies advantageously compared to existing numerical/statistical forecasting-downscaling pipelines, regarding either deterministic/probabilistic skills or economic gains. Moreover, a 100-member, 10-day forecast with spatial resolution of 1 km and output frequency of 15 min takes < 1 hour on a moderate-end GPU, as contrast to $\mathcal{O}(10^3)$ CPU hours for conventional numerical simulation. By drastically reducing computational costs while maintaining accuracy, our method paves the way for more efficient and reliable renewable energy planning and operation.
DABench: A Benchmark Dataset for Data-Driven Weather Data Assimilation
Aug 21, 2024



Recent advancements in deep learning (DL) have led to the development of several Large Weather Models (LWMs) that rival state-of-the-art (SOTA) numerical weather prediction (NWP) systems. Up to now, these models still rely on traditional NWP-generated analysis fields as input and are far from being an autonomous system. While researchers are exploring data-driven data assimilation (DA) models to generate accurate initial fields for LWMs, the lack of a standard benchmark impedes the fair evaluation among different data-driven DA algorithms. Here, we introduce DABench, a benchmark dataset utilizing ERA5 data as ground truth to guide the development of end-to-end data-driven weather prediction systems. DABench contributes four standard features: (1) sparse and noisy simulated observations under the guidance of the observing system simulation experiment method; (2) a skillful pre-trained weather prediction model to generate background fields while fairly evaluating the impact of assimilation outcomes on predictions; (3) standardized evaluation metrics for model comparison; (4) a strong baseline called the DA Transformer (DaT). DaT integrates the four-dimensional variational DA prior knowledge into the Transformer model and outperforms the SOTA in physical state reconstruction, named 4DVarNet. Furthermore, we exemplify the development of an end-to-end data-driven weather prediction system by integrating DaT with the prediction model. Researchers can leverage DABench to develop their models and compare performance against established baselines, which will benefit the future advancements of data-driven weather prediction systems. The code is available on this Github repository and the dataset is available at the Baidu Drive.
Long-Term Prediction Accuracy Improvement of Data-Driven Medium-Range Global Weather Forecast
Jun 26, 2024



Long-term stability stands as a crucial requirement in data-driven medium-range global weather forecasting. Spectral bias is recognized as the primary contributor to instabilities, as data-driven methods difficult to learn small-scale dynamics. In this paper, we reveal that the universal mechanism for these instabilities is not only related to spectral bias but also to distortions brought by processing spherical data using conventional convolution. These distortions lead to a rapid amplification of errors over successive long-term iterations, resulting in a significant decline in forecast accuracy. To address this issue, a universal neural operator called the Spherical Harmonic Neural Operator (SHNO) is introduced to improve long-term iterative forecasts. SHNO uses the spherical harmonic basis to mitigate distortions for spherical data and uses gated residual spectral attention (GRSA) to correct spectral bias caused by spurious correlations across different scales. The effectiveness and merit of the proposed method have been validated through its application for spherical Shallow Water Equations (SWEs) and medium-range global weather forecasting. Our findings highlight the benefits and potential of SHNO to improve the accuracy of long-term prediction.
A Local Similarity-Preserving Framework for Nonlinear Dimensionality Reduction with Neural Networks
Mar 10, 2021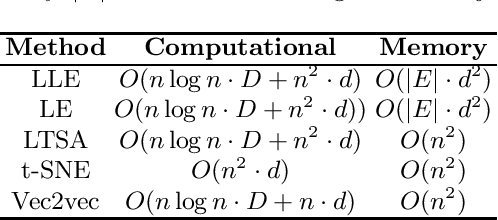
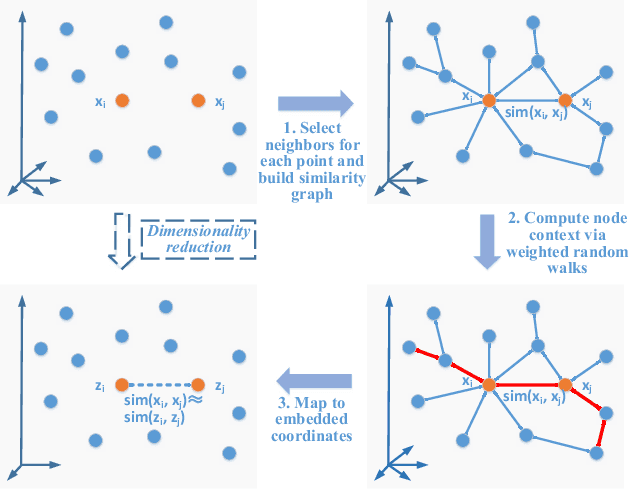
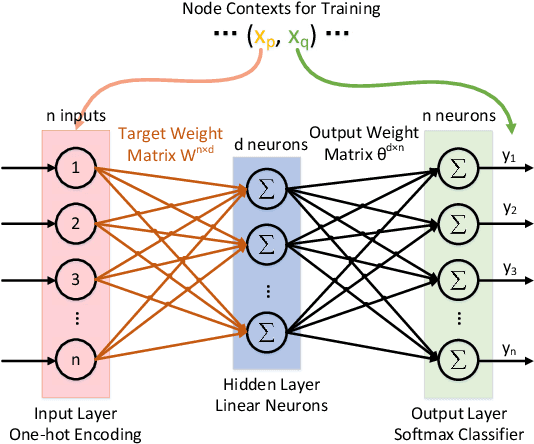
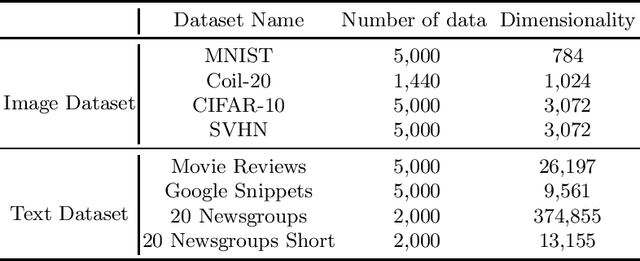
Real-world data usually have high dimensionality and it is important to mitigate the curse of dimensionality. High-dimensional data are usually in a coherent structure and make the data in relatively small true degrees of freedom. There are global and local dimensionality reduction methods to alleviate the problem. Most of existing methods for local dimensionality reduction obtain an embedding with the eigenvalue or singular value decomposition, where the computational complexities are very high for a large amount of data. Here we propose a novel local nonlinear approach named Vec2vec for general purpose dimensionality reduction, which generalizes recent advancements in embedding representation learning of words to dimensionality reduction of matrices. It obtains the nonlinear embedding using a neural network with only one hidden layer to reduce the computational complexity. To train the neural network, we build the neighborhood similarity graph of a matrix and define the context of data points by exploiting the random walk properties. Experiments demenstrate that Vec2vec is more efficient than several state-of-the-art local dimensionality reduction methods in a large number of high-dimensional data. Extensive experiments of data classification and clustering on eight real datasets show that Vec2vec is better than several classical dimensionality reduction methods in the statistical hypothesis test, and it is competitive with recently developed state-of-the-art UMAP.