 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Local Similarity-Preserving Framework for Nonlinear Dimensionality Reduction with Neural Networks
Paper and Code
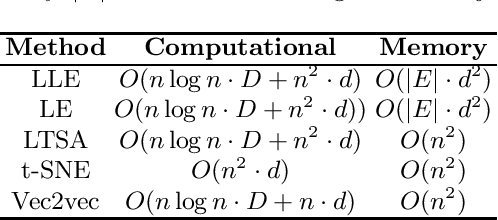
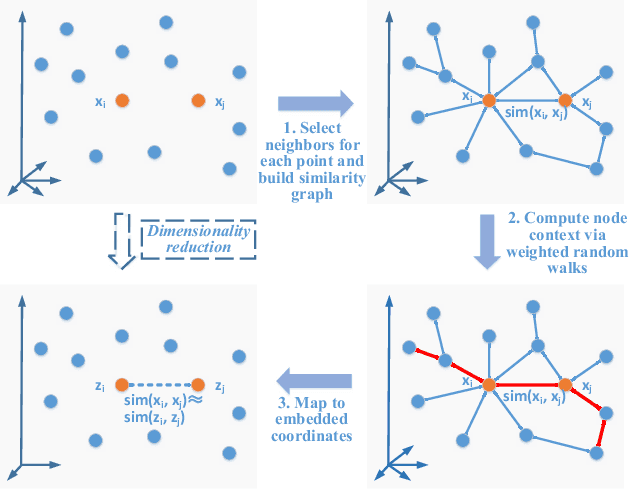
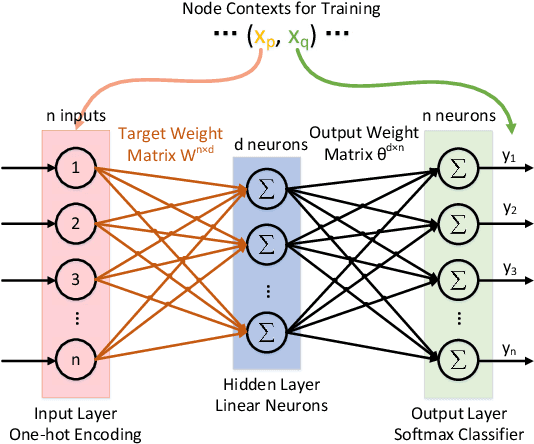
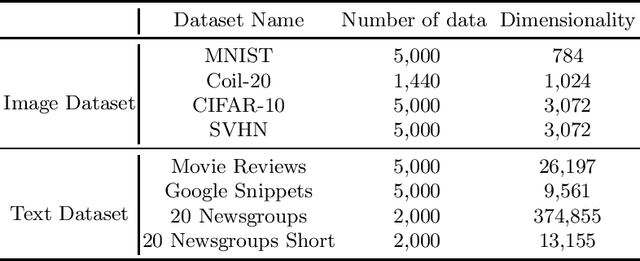
Real-world data usually have high dimensionality and it is important to mitigate the curse of dimensionality. High-dimensional data are usually in a coherent structure and make the data in relatively small true degrees of freedom. There are global and local dimensionality reduction methods to alleviate the problem. Most of existing methods for local dimensionality reduction obtain an embedding with the eigenvalue or singular value decomposition, where the computational complexities are very high for a large amount of data. Here we propose a novel local nonlinear approach named Vec2vec for general purpose dimensionality reduction, which generalizes recent advancements in embedding representation learning of words to dimensionality reduction of matrices. It obtains the nonlinear embedding using a neural network with only one hidden layer to reduce the computational complexity. To train the neural network, we build the neighborhood similarity graph of a matrix and define the context of data points by exploiting the random walk properties. Experiments demenstrate that Vec2vec is more efficient than several state-of-the-art local dimensionality reduction methods in a large number of high-dimensional data. Extensive experiments of data classification and clustering on eight real datasets show that Vec2vec is better than several classical dimensionality reduction methods in the statistical hypothesis test, and it is competitive with recently developed state-of-the-art UMAP.