 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI4Reading: Chinese Audiobook Interpretation System Based on Multi-Agent Collaboration
Dec 29, 2025Audiobook interpretations are attracting increasing attention, as they provide accessible and in-depth analyses of books that offer readers practical insights and intellectual inspiration. However, their manual creation process remains time-consuming and resource-intensive. To address this challenge, we propose AI4Reading, a multi-agent collaboration system leveraging large language models (LLMs) and speech synthesis technology to generate podcast, like audiobook interpretations. The system is designed to meet three key objectives: accurate content preservation, enhanced comprehensibility, and a logical narrative structure. To achieve these goals, we develop a framework composed of 11 specialized agents,including topic analysts, case analysts, editors, a narrator, and proofreaders that work in concert to explore themes, extract real world cases, refine content organization, and synthesize natural spoken language. By comparing expert interpretations with our system's output, the results show that although AI4Reading still has a gap in speech generation quality, the generated interpretative scripts are simpler and more accurate.
Redefining Simplicity: Benchmarking Large Language Models from Lexical to Document Simplification
Feb 12, 2025

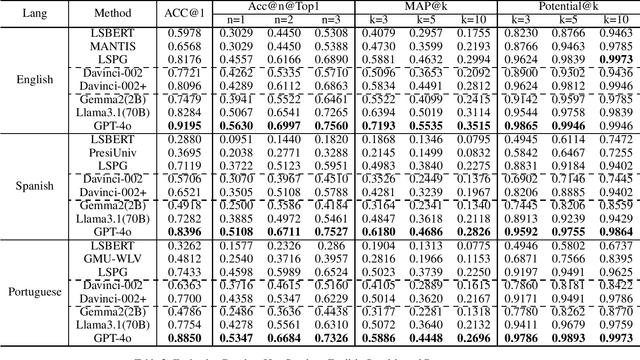
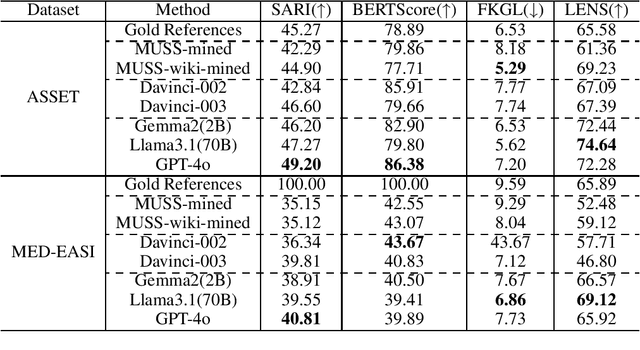
Text simplification (TS) refers to the process of reducing the complexity of a text while retaining its original meaning and key information. Existing work only shows that large language models (LLMs) have outperformed supervised non-LLM-based methods on sentence simplification. This study offers the first comprehensive analysis of LLM performance across four TS tasks: lexical, syntactic, sentence, and document simplification. We compare lightweight, closed-source and open-source LLMs against traditional non-LLM methods using automatic metrics and human evaluations. Our experiments reveal that LLMs not only outperform non-LLM approaches in all four tasks but also often generate outputs that exceed the quality of existing human-annotated references. Finally, we present some future directions of TS in the era of LLMs.
Boosting Explainability through Selective Rationalization in Pre-trained Language Models
Jan 03, 2025



The widespread application of pre-trained language models (PLMs) in natural language processing (NLP) has led to increasing concerns about their explainability. Selective rationalization is a self-explanatory framework that selects human-intelligible input subsets as rationales for predictions. Recent studies have shown that applying existing rationalization frameworks to PLMs will result in severe degeneration and failure problems, producing sub-optimal or meaningless rationales. Such failures severely damage trust in rationalization methods and constrain the application of rationalization techniques on PLMs. In this paper, we find that the homogeneity of tokens in the sentences produced by PLMs is the primary contributor to these problems. To address these challenges, we propose a method named Pre-trained Language Model's Rationalization (PLMR), which splits PLMs into a generator and a predictor to deal with NLP tasks while providing interpretable rationales. The generator in PLMR also alleviates homogeneity by pruning irrelevant tokens, while the predictor uses full-text information to standardize predictions. Experiments conducted on two widely used datasets across multiple PLMs demonstrate the effectiveness of the proposed method PLMR in addressing the challenge of applying selective rationalization to PLMs. Codes: https://github.com/ylb777/PLMR.
Hybrid Local Causal Discovery
Dec 27, 2024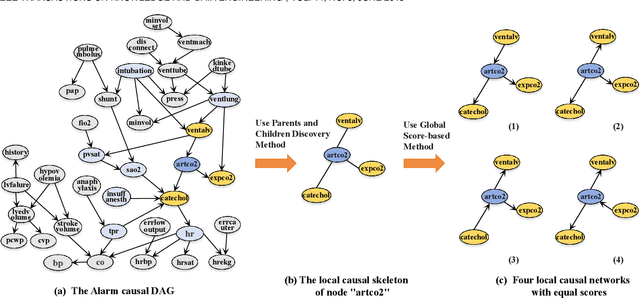
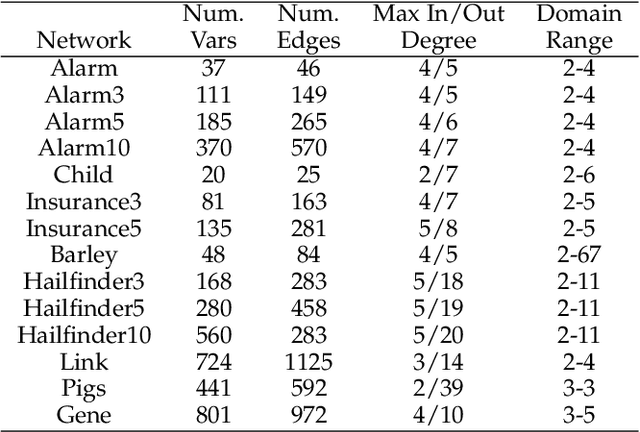
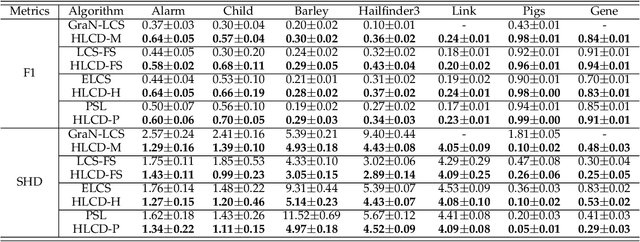
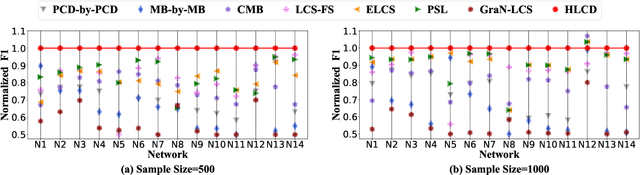
Local causal discovery aims to learn and distinguish the direct causes and effects of a target variable from observed data. Existing constraint-based local causal discovery methods use AND or OR rules in constructing the local causal skeleton, but using either rule alone is prone to produce cascading errors in the learned local causal skeleton, and thus impacting the inference of local causal relationships. On the other hand, directly applying score-based global causal discovery methods to local causal discovery may randomly return incorrect results due to the existence of local equivalence classes. To address the above issues, we propose a Hybrid Local Causal Discovery algorithm, called HLCD. Specifically, HLCD initially utilizes a constraint-based approach combined with the OR rule to obtain a candidate skeleton and then employs a score-based method to eliminate redundant portions in the candidate skeleton. Furthermore, during the local causal orientation phase, HLCD distinguishes between V-structures and equivalence classes by comparing the local structure scores between the two, thereby avoiding orientation interference caused by local equivalence classes. We conducted extensive experiments with seven state-of-the-art competitors on 14 benchmark Bayesian network datasets, and the experimental results demonstrate that HLCD significantly outperforms existing local causal discovery algorithms.
Towards Effective Graph Rationalization via Boosting Environment Diversity
Dec 17, 2024



Graph Neural Networks (GNNs) perform effectively when training and testing graphs are drawn from the same distribution, but struggle to generalize well in the face of distribution shifts. To address this issue, existing mainstreaming graph rationalization methods first identify rationale and environment subgraphs from input graphs, and then diversify training distributions by augmenting the environment subgraphs. However, these methods merely combine the learned rationale subgraphs with environment subgraphs in the representation space to produce augmentation samples, failing to produce sufficiently diverse distributions. Thus, in this paper, we propose to achieve an effective Graph Rationalization by Boosting Environmental diversity, a GRBE approach that generates the augmented samples in the original graph space to improve the diversity of the environment subgraph. Firstly, to ensure the effectiveness of augmentation samples, we propose a precise rationale subgraph extraction strategy in GRBE to refine the rationale subgraph learning process in the original graph space. Secondly, to ensure the diversity of augmented samples, we propose an environment diversity augmentation strategy in GRBE that mixes the environment subgraphs of different graphs in the original graph space and then combines the new environment subgraphs with rationale subgraphs to generate augmented graphs. The average improvements of 7.65% and 6.11% in rationalization and classification performance on benchmark datasets demonstrate the superiority of GRBE over state-of-the-art approaches.
Prompt Transfer for Dual-Aspect Cross Domain Cognitive Diagnosis
Dec 06, 2024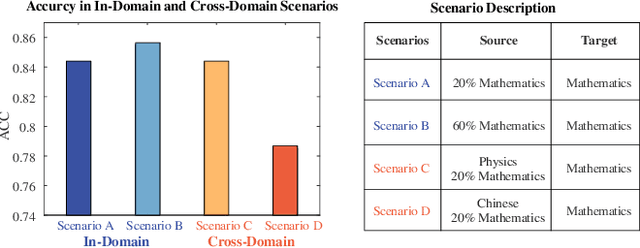
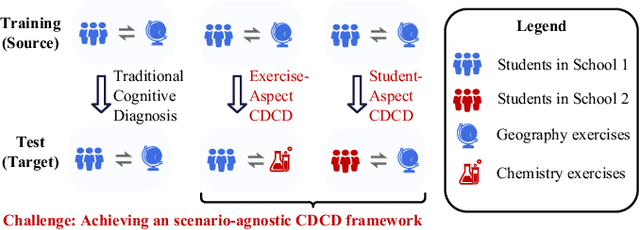
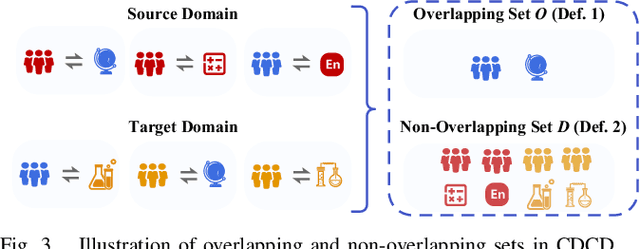
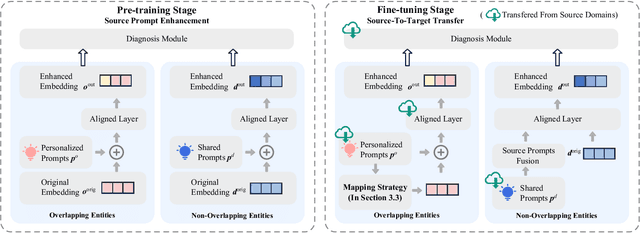
Cognitive Diagnosis (CD) aims to evaluate students' cognitive states based on their interaction data, enabling downstream applications such as exercise recommendation and personalized learning guidance. However, existing methods often struggle with accuracy drops in cross-domain cognitive diagnosis (CDCD), a practical yet challenging task. While some efforts have explored exercise-aspect CDCD, such as crosssubject scenarios, they fail to address the broader dual-aspect nature of CDCD, encompassing both student- and exerciseaspect variations. This diversity creates significant challenges in developing a scenario-agnostic framework. To address these gaps, we propose PromptCD, a simple yet effective framework that leverages soft prompt transfer for cognitive diagnosis. PromptCD is designed to adapt seamlessly across diverse CDCD scenarios, introducing PromptCD-S for student-aspect CDCD and PromptCD-E for exercise-aspect CDCD. Extensive experiments on real-world datasets demonstrate the robustness and effectiveness of PromptCD, consistently achieving superior performance across various CDCD scenarios. Our work offers a unified and generalizable approach to CDCD, advancing both theoretical and practical understanding in this critical domain. The implementation of our framework is publicly available at https://github.com/Publisher-PromptCD/PromptCD.
Linking Model Intervention to Causal Interpretation in Model Explanation
Oct 21, 2024

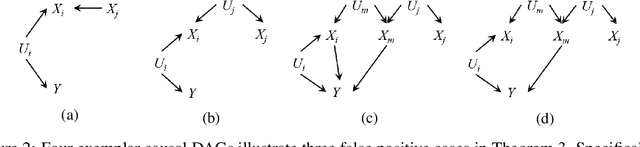

Intervention intuition is often used in model explanation where the intervention effect of a feature on the outcome is quantified by the difference of a model prediction when the feature value is changed from the current value to the baseline value. Such a model intervention effect of a feature is inherently association. In this paper, we will study the conditions when an intuitive model intervention effect has a causal interpretation, i.e., when it indicates whether a feature is a direct cause of the outcome. This work links the model intervention effect to the causal interpretation of a model. Such an interpretation capability is important since it indicates whether a machine learning model is trustworthy to domain experts. The conditions also reveal the limitations of using a model intervention effect for causal interpretation in an environment with unobserved features. Experiments on semi-synthetic datasets have been conducted to validate theorems and show the potential for using the model intervention effect for model interpretation.
Causal Multi-Label Feature Selection in Federated Setting
Mar 11, 2024Multi-label feature selection serves as an effective mean for dealing with high-dimensional multi-label data. To achieve satisfactory performance, existing methods for multi-label feature selection often require the centralization of substantial data from multiple sources. However, in Federated setting, centralizing data from all sources and merging them into a single dataset is not feasible. To tackle this issue, in this paper, we study a challenging problem of causal multi-label feature selection in federated setting and propose a Federated Causal Multi-label Feature Selection (FedCMFS) algorithm with three novel subroutines. Specifically, FedCMFS first uses the FedCFL subroutine that considers the correlations among label-label, label-feature, and feature-feature to learn the relevant features (candidate parents and children) of each class label while preserving data privacy without centralizing data. Second, FedCMFS employs the FedCFR subroutine to selectively recover the missed true relevant features. Finally, FedCMFS utilizes the FedCFC subroutine to remove false relevant features. The extensive experiments on 8 datasets have shown that FedCMFS is effect for causal multi-label feature selection in federated setting.
Causal Inference with Conditional Front-Door Adjustment and Identifiable Variational Autoencoder
Oct 03, 2023An essential and challenging problem in causal inference is causal effect estimation from observational data. The problem becomes more difficult with the presence of unobserved confounding variables. The front-door adjustment is a practical approach for dealing with unobserved confounding variables. However, the restriction for the standard front-door adjustment is difficult to satisfy in practice. In this paper, we relax some of the restrictions by proposing the concept of conditional front-door (CFD) adjustment and develop the theorem that guarantees the causal effect identifiability of CFD adjustment. Furthermore, as it is often impossible for a CFD variable to be given in practice, it is desirable to learn it from data. By leveraging the ability of deep generative models, we propose CFDiVAE to learn the representation of the CFD adjustment variable directly from data with the identifiable Variational AutoEncoder and formally prove the model identifiability. Extensive experiments on synthetic datasets validate the effectiveness of CFDiVAE and its superiority over existing methods. The experiments also show that the performance of CFDiVAE is less sensitive to the causal strength of unobserved confounding variables. We further apply CFDiVAE to a real-world dataset to demonstrate its potential application.
Fair Causal Feature Selection
Jun 17, 2023



Causal feature selection has recently received increasing attention in machine learning. Existing causal feature selection algorithms select unique causal features of a class variable as the optimal feature subset. However, a class variable usually has multiple states, and it is unfair to select the same causal features for different states of a class variable. To address this problem, we employ the class-specific mutual information to evaluate the causal information carried by each state of the class attribute, and theoretically analyze the unique relationship between each state and the causal features. Based on this, a Fair Causal Feature Selection algorithm (FairCFS) is proposed to fairly identifies the causal features for each state of the class variable. Specifically, FairCFS uses the pairwise comparisons of class-specific mutual information and the size of class-specific mutual information values from the perspective of each state, and follows a divide-and-conquer framework to find causal features. The correctness and application condition of FairCFS are theoretically proved, and extensive experiments are conducted to demonstrate the efficiency and superiority of FairCFS compared to the state-of-the-art approaches.