 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI4Reading: Chinese Audiobook Interpretation System Based on Multi-Agent Collaboration
Dec 29, 2025Audiobook interpretations are attracting increasing attention, as they provide accessible and in-depth analyses of books that offer readers practical insights and intellectual inspiration. However, their manual creation process remains time-consuming and resource-intensive. To address this challenge, we propose AI4Reading, a multi-agent collaboration system leveraging large language models (LLMs) and speech synthesis technology to generate podcast, like audiobook interpretations. The system is designed to meet three key objectives: accurate content preservation, enhanced comprehensibility, and a logical narrative structure. To achieve these goals, we develop a framework composed of 11 specialized agents,including topic analysts, case analysts, editors, a narrator, and proofreaders that work in concert to explore themes, extract real world cases, refine content organization, and synthesize natural spoken language. By comparing expert interpretations with our system's output, the results show that although AI4Reading still has a gap in speech generation quality, the generated interpretative scripts are simpler and more accurate.
Redefining Simplicity: Benchmarking Large Language Models from Lexical to Document Simplification
Feb 12, 2025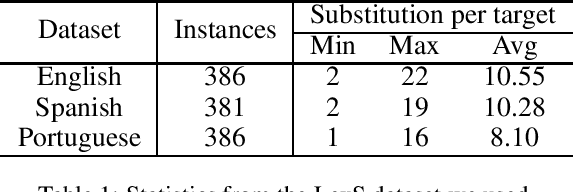

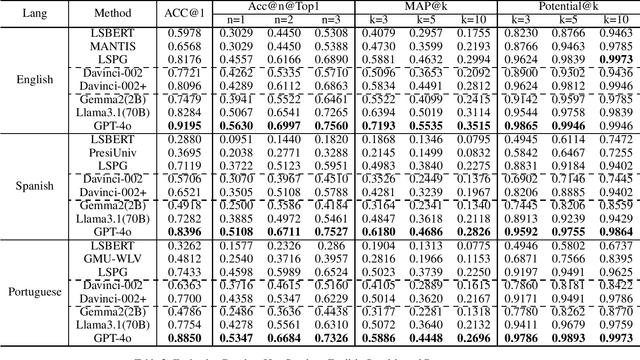
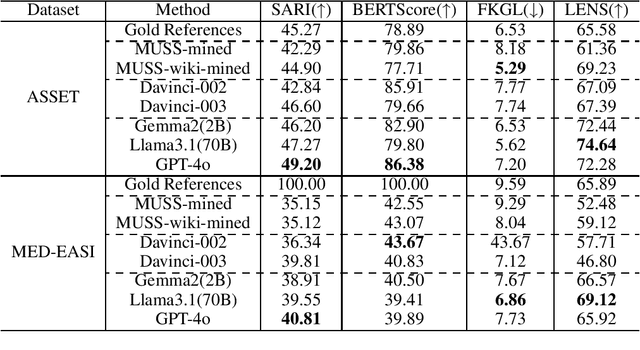
Text simplification (TS) refers to the process of reducing the complexity of a text while retaining its original meaning and key information. Existing work only shows that large language models (LLMs) have outperformed supervised non-LLM-based methods on sentence simplification. This study offers the first comprehensive analysis of LLM performance across four TS tasks: lexical, syntactic, sentence, and document simplification. We compare lightweight, closed-source and open-source LLMs against traditional non-LLM methods using automatic metrics and human evaluations. Our experiments reveal that LLMs not only outperform non-LLM approaches in all four tasks but also often generate outputs that exceed the quality of existing human-annotated references. Finally, we present some future directions of TS in the era of LLMs.
New Evaluation Paradigm for Lexical Simplification
Jan 25, 2025Lexical Simplification (LS) methods use a three-step pipeline: complex word identification, substitute generation, and substitute ranking, each with separate evaluation datasets. We found large language models (LLMs) can simplify sentences directly with a single prompt, bypassing the traditional pipeline. However, existing LS datasets are not suitable for evaluating these LLM-generated simplified sentences, as they focus on providing substitutes for single complex words without identifying all complex words in a sentence. To address this gap, we propose a new annotation method for constructing an all-in-one LS dataset through human-machine collaboration. Automated methods generate a pool of potential substitutes, which human annotators then assess, suggesting additional alternatives as needed. Additionally, we explore LLM-based methods with single prompts, in-context learning, and chain-of-thought techniques. We introduce a multi-LLMs collaboration approach to simulate each step of the LS task. Experimental results demonstrate that LS based on multi-LLMs approaches significantly outperforms existing baselines.