 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMental Health Impacts of AI Companions: Triangulating Social Media Quasi-Experiments, User Perspectives, and Relational Theory
Sep 26, 2025
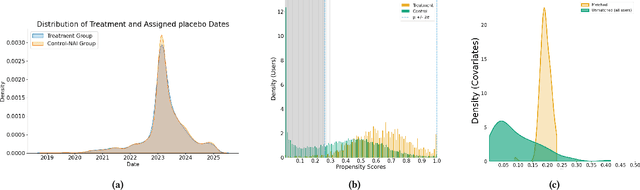
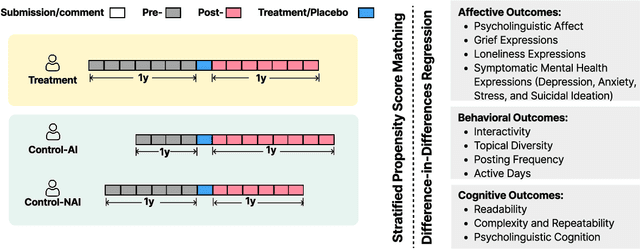
AI-powered companion chatbots (AICCs) such as Replika are increasingly popular, offering empathetic interactions, yet their psychosocial impacts remain unclear. We examined how engaging with AICCs shaped wellbeing and how users perceived these experiences. First, we conducted a large-scale quasi-experimental study of longitudinal Reddit data, applying stratified propensity score matching and Difference-in-Differences regression. Findings revealed mixed effects -- greater affective and grief expression, readability, and interpersonal focus, alongside increases in language about loneliness and suicidal ideation. Second, we complemented these results with 15 semi-structured interviews, which we thematically analyzed and contextualized using Knapp's relationship development model. We identified trajectories of initiation, escalation, and bonding, wherein AICCs provided emotional validation and social rehearsal but also carried risks of over-reliance and withdrawal. Triangulating across methods, we offer design implications for AI companions that scaffold healthy boundaries, support mindful engagement, support disclosure without dependency, and surface relationship stages -- maximizing psychosocial benefits while mitigating risks.
Redefining Simplicity: Benchmarking Large Language Models from Lexical to Document Simplification
Feb 12, 2025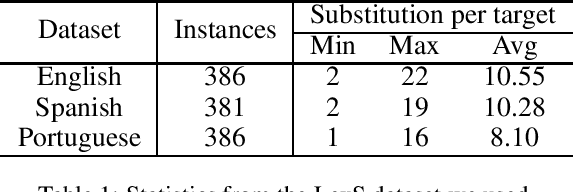

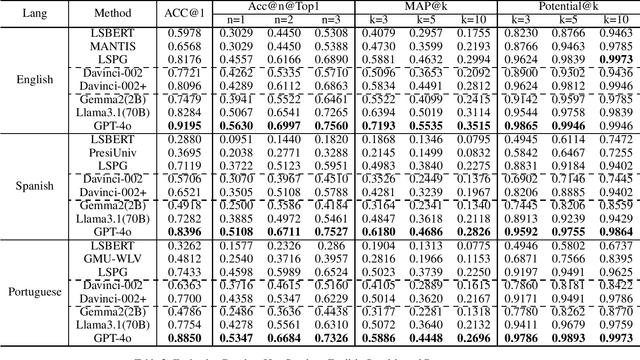
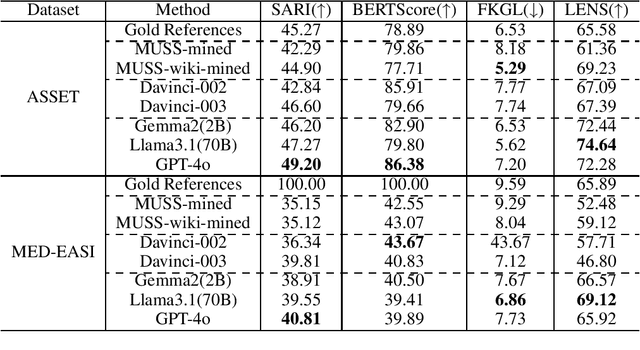
Text simplification (TS) refers to the process of reducing the complexity of a text while retaining its original meaning and key information. Existing work only shows that large language models (LLMs) have outperformed supervised non-LLM-based methods on sentence simplification. This study offers the first comprehensive analysis of LLM performance across four TS tasks: lexical, syntactic, sentence, and document simplification. We compare lightweight, closed-source and open-source LLMs against traditional non-LLM methods using automatic metrics and human evaluations. Our experiments reveal that LLMs not only outperform non-LLM approaches in all four tasks but also often generate outputs that exceed the quality of existing human-annotated references. Finally, we present some future directions of TS in the era of LLMs.
New Evaluation Paradigm for Lexical Simplification
Jan 25, 2025Lexical Simplification (LS) methods use a three-step pipeline: complex word identification, substitute generation, and substitute ranking, each with separate evaluation datasets. We found large language models (LLMs) can simplify sentences directly with a single prompt, bypassing the traditional pipeline. However, existing LS datasets are not suitable for evaluating these LLM-generated simplified sentences, as they focus on providing substitutes for single complex words without identifying all complex words in a sentence. To address this gap, we propose a new annotation method for constructing an all-in-one LS dataset through human-machine collaboration. Automated methods generate a pool of potential substitutes, which human annotators then assess, suggesting additional alternatives as needed. Additionally, we explore LLM-based methods with single prompts, in-context learning, and chain-of-thought techniques. We introduce a multi-LLMs collaboration approach to simulate each step of the LS task. Experimental results demonstrate that LS based on multi-LLMs approaches significantly outperforms existing baselines.
Progressive Document-level Text Simplification via Large Language Models
Jan 07, 2025



Research on text simplification has primarily focused on lexical and sentence-level changes. Long document-level simplification (DS) is still relatively unexplored. Large Language Models (LLMs), like ChatGPT, have excelled in many natural language processing tasks. However, their performance on DS tasks is unsatisfactory, as they often treat DS as merely document summarization. For the DS task, the generated long sequences not only must maintain consistency with the original document throughout, but complete moderate simplification operations encompassing discourses, sentences, and word-level simplifications. Human editors employ a hierarchical complexity simplification strategy to simplify documents. This study delves into simulating this strategy through the utilization of a multi-stage collaboration using LLMs. We propose a progressive simplification method (ProgDS) by hierarchically decomposing the task, including the discourse-level, topic-level, and lexical-level simplification. Experimental results demonstrate that ProgDS significantly outperforms existing smaller models or direct prompting with LLMs, advancing the state-of-the-art in the document simplification task.
Prompt-tuning for Clickbait Detection via Text Summarization
Apr 17, 2024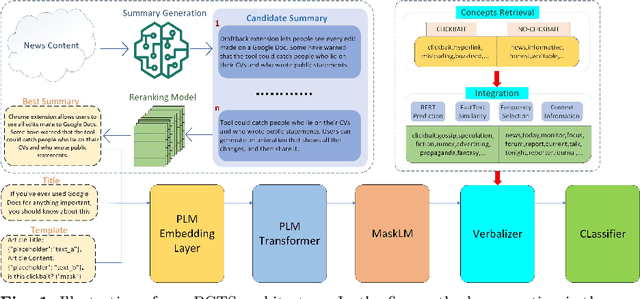

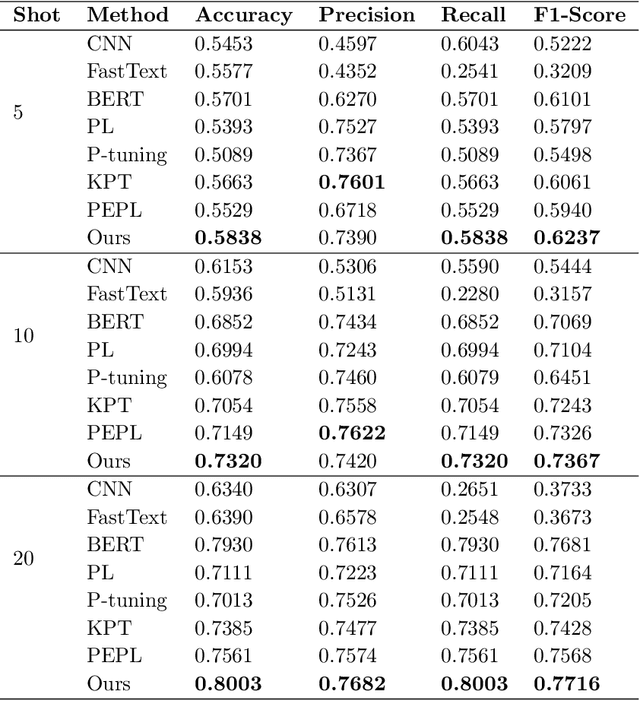
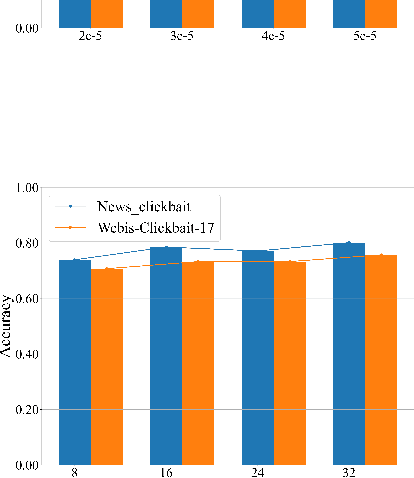
Clickbaits are surprising social posts or deceptive news headlines that attempt to lure users for more clicks, which have posted at unprecedented rates for more profit or commercial revenue. The spread of clickbait has significant negative impacts on the users, which brings users misleading or even click-jacking attacks. Different from fake news, the crucial problem in clickbait detection is determining whether the headline matches the corresponding content. Most existing methods compute the semantic similarity between the headlines and contents for detecting clickbait. However, due to significant differences in length and semantic features between headlines and contents, directly calculating semantic similarity is often difficult to summarize the relationship between them. To address this problem, we propose a prompt-tuning method for clickbait detection via text summarization in this paper, text summarization is introduced to summarize the contents, and clickbait detection is performed based on the similarity between the generated summary and the contents. Specifically, we first introduce a two-stage text summarization model to produce high-quality news summaries based on pre-trained language models, and then both the headlines and new generated summaries are incorporated as the inputs for prompt-tuning. Additionally, a variety of strategies are conducted to incorporate external knowledge for improving the performance of clickbait detection. The extensive experiments on well-known clickbait detection datasets demonstrate that our method achieved state-of-the-art performance.
Multilingual Lexical Simplification via Paraphrase Generation
Jul 28, 2023



Lexical simplification (LS) methods based on pretrained language models have made remarkable progress, generating potential substitutes for a complex word through analysis of its contextual surroundings. However, these methods require separate pretrained models for different languages and disregard the preservation of sentence meaning. In this paper, we propose a novel multilingual LS method via paraphrase generation, as paraphrases provide diversity in word selection while preserving the sentence's meaning. We regard paraphrasing as a zero-shot translation task within multilingual neural machine translation that supports hundreds of languages. After feeding the input sentence into the encoder of paraphrase modeling, we generate the substitutes based on a novel decoding strategy that concentrates solely on the lexical variations of the complex word. Experimental results demonstrate that our approach surpasses BERT-based methods and zero-shot GPT3-based method significantly on English, Spanish, and Portuguese.
Clickbait Detection via Large Language Models
Jun 16, 2023



Clickbait, which aims to induce users with some surprising and even thrilling headlines for increasing click-through rates, permeates almost all online content publishers, such as news portals and social media. Recently, Large Language Models (LLMs) have emerged as a powerful instrument and achieved tremendous success in a serious of NLP downstream tasks. However, it is not yet known whether LLMs can be served as a high-quality clickbait detection system. In this paper, we analyze the performance of LLMs in the few-shot scenarios on a number of English and Chinese benchmark datasets. Experimental results show that LLMs cannot achieve the best results compared to the state-of-the-art deep and fine-tuning PLMs methods. Different from the human intuition, the experiments demonstrated that LLMs cannot make satisfied clickbait detection just by the headlines.
ParaLS: Lexical Substitution via Pretrained Paraphraser
May 14, 2023



Lexical substitution (LS) aims at finding appropriate substitutes for a target word in a sentence. Recently, LS methods based on pretrained language models have made remarkable progress, generating potential substitutes for a target word through analysis of its contextual surroundings. However, these methods tend to overlook the preservation of the sentence's meaning when generating the substitutes. This study explores how to generate the substitute candidates from a paraphraser, as the generated paraphrases from a paraphraser contain variations in word choice and preserve the sentence's meaning. Since we cannot directly generate the substitutes via commonly used decoding strategies, we propose two simple decoding strategies that focus on the variations of the target word during decoding. Experimental results show that our methods outperform state-of-the-art LS methods based on pre-trained language models on three benchmarks.
Sentence Simplification via Large Language Models
Feb 23, 2023



Sentence Simplification aims to rephrase complex sentences into simpler sentences while retaining original meaning. Large Language models (LLMs) have demonstrated the ability to perform a variety of natural language processing tasks. However, it is not yet known whether LLMs can be served as a high-quality sentence simplification system. In this work, we empirically analyze the zero-/few-shot learning ability of LLMs by evaluating them on a number of benchmark test sets. Experimental results show LLMs outperform state-of-the-art sentence simplification methods, and are judged to be on a par with human annotators.
Mental Health Coping Stories on Social Media: A Causal-Inference Study of Papageno Effect
Feb 20, 2023



The Papageno effect concerns how media can play a positive role in preventing and mitigating suicidal ideation and behaviors. With the increasing ubiquity and widespread use of social media, individuals often express and share lived experiences and struggles with mental health. However, there is a gap in our understanding about the existence and effectiveness of the Papageno effect in social media, which we study in this paper. In particular, we adopt a causal-inference framework to examine the impact of exposure to mental health coping stories on individuals on Twitter. We obtain a Twitter dataset with $\sim$2M posts by $\sim$10K individuals. We consider engaging with coping stories as the Treatment intervention, and adopt a stratified propensity score approach to find matched cohorts of Treatment and Control individuals. We measure the psychosocial shifts in affective, behavioral, and cognitive outcomes in longitudinal Twitter data before and after engaging with the coping stories. Our findings reveal that, engaging with coping stories leads to decreased stress and depression, and improved expressive writing, diversity, and interactivity. Our work discusses the practical and platform design implications in supporting mental wellbeing.