 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMental Health Impacts of AI Companions: Triangulating Social Media Quasi-Experiments, User Perspectives, and Relational Theory
Sep 26, 2025
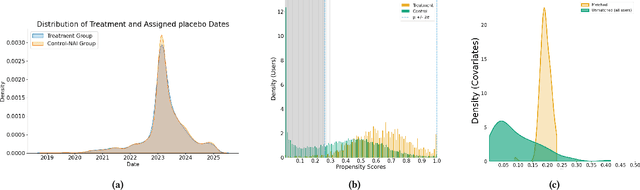
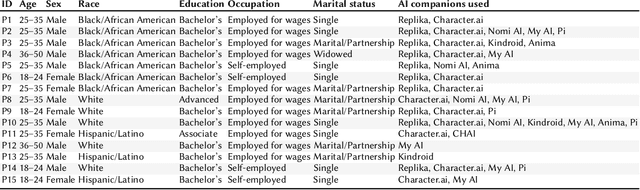
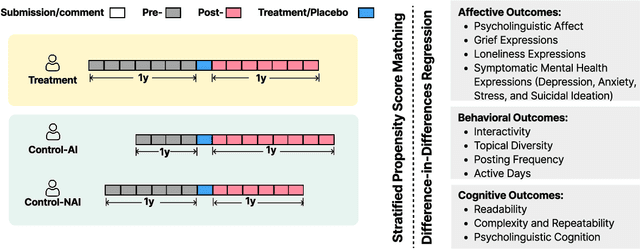
AI-powered companion chatbots (AICCs) such as Replika are increasingly popular, offering empathetic interactions, yet their psychosocial impacts remain unclear. We examined how engaging with AICCs shaped wellbeing and how users perceived these experiences. First, we conducted a large-scale quasi-experimental study of longitudinal Reddit data, applying stratified propensity score matching and Difference-in-Differences regression. Findings revealed mixed effects -- greater affective and grief expression, readability, and interpersonal focus, alongside increases in language about loneliness and suicidal ideation. Second, we complemented these results with 15 semi-structured interviews, which we thematically analyzed and contextualized using Knapp's relationship development model. We identified trajectories of initiation, escalation, and bonding, wherein AICCs provided emotional validation and social rehearsal but also carried risks of over-reliance and withdrawal. Triangulating across methods, we offer design implications for AI companions that scaffold healthy boundaries, support mindful engagement, support disclosure without dependency, and surface relationship stages -- maximizing psychosocial benefits while mitigating risks.
Mental Health Coping Stories on Social Media: A Causal-Inference Study of Papageno Effect
Feb 20, 2023



The Papageno effect concerns how media can play a positive role in preventing and mitigating suicidal ideation and behaviors. With the increasing ubiquity and widespread use of social media, individuals often express and share lived experiences and struggles with mental health. However, there is a gap in our understanding about the existence and effectiveness of the Papageno effect in social media, which we study in this paper. In particular, we adopt a causal-inference framework to examine the impact of exposure to mental health coping stories on individuals on Twitter. We obtain a Twitter dataset with $\sim$2M posts by $\sim$10K individuals. We consider engaging with coping stories as the Treatment intervention, and adopt a stratified propensity score approach to find matched cohorts of Treatment and Control individuals. We measure the psychosocial shifts in affective, behavioral, and cognitive outcomes in longitudinal Twitter data before and after engaging with the coping stories. Our findings reveal that, engaging with coping stories leads to decreased stress and depression, and improved expressive writing, diversity, and interactivity. Our work discusses the practical and platform design implications in supporting mental wellbeing.
Vaccine Discourse on Twitter During the COVID-19 Pandemic
Jul 23, 2022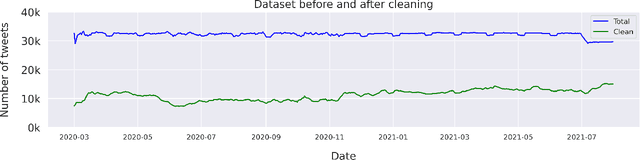



Since the onset of the COVID-19 pandemic, vaccines have been an important topic in public discourse. The discussions around vaccines are polarized as some see them as an important measure to end the pandemic, and others are hesitant or find them harmful. This study investigates posts related to COVID-19 vaccines on Twitter and focuses on those which have a negative stance toward vaccines. A dataset of 16,713,238 English tweets related to COVID-19 vaccines was collected covering the period from March 1, 2020, to July 31, 2021. We used the Scikit-learn Python library to apply a support vector machine (SVM) classifier to identify the tweets with a negative stance toward the COVID-19 vaccines. A total of 5,163 tweets were used to train the classifier, out of which a subset of 2,484 tweets were manually annotated by us and made publicly available. We used the BERTtopic model to extract and investigate the topics discussed within the negative tweets and how they changed over time. We show that the negativity with respect to COVID-19 vaccines has decreased over time along with the vaccine roll-outs. We identify 37 topics of discussion and present their respective importance over time. We show that popular topics consist of conspiratorial discussions such as 5G towers and microchips, but also contain legitimate concerns around vaccination safety and side effects as well as concerns about policies. Our study shows that even unpopular opinions or conspiracy theories can become widespread when paired with a widely popular discussion topic such as COVID-19 vaccines. Understanding the concerns and the discussed topics and how they change over time is essential for policymakers and public health authorities to provide better and in-time information and policies, to facilitate vaccination of the population in future similar crises.
The Impact of COVID-19 Pandemic on LGBTQ Online Communities
May 27, 2022
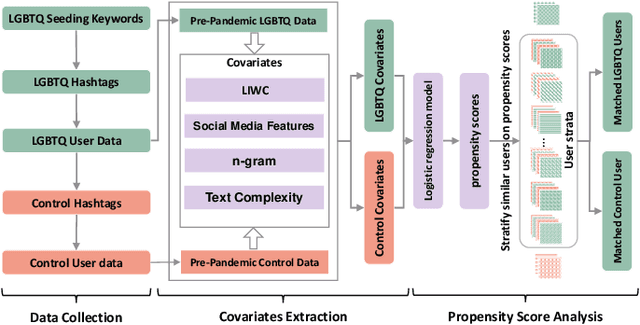
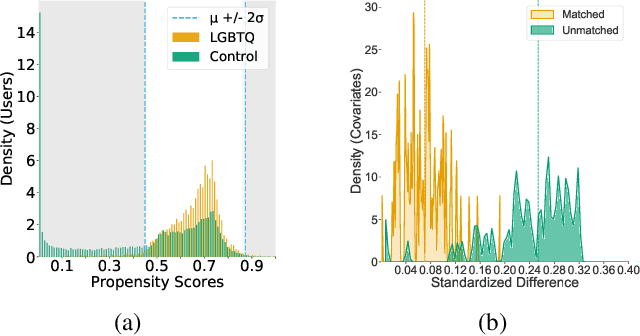
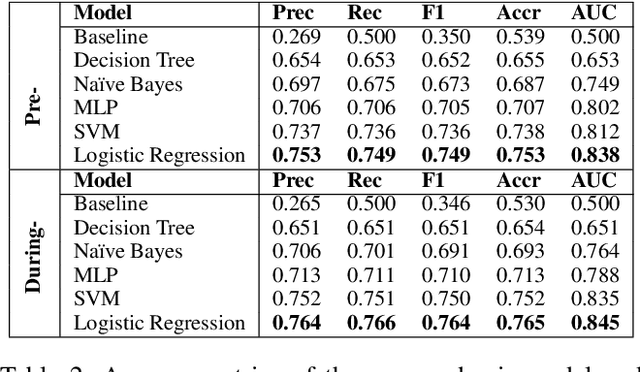
The COVID-19 pandemic has disproportionately impacted the lives of minorities, such as members of the LGBTQ community (lesbian, gay, bisexual, transgender, and queer) due to pre-existing social disadvantages and health disparities. Although extensive research has been carried out on the impact of the COVID-19 pandemic on different aspects of the general population's lives, few studies are focused on the LGBTQ population. In this paper, we identify a group of Twitter users who self-disclose to belong to the LGBTQ community. We develop and evaluate two sets of machine learning classifiers using a pre-pandemic and a during pandemic dataset to identify Twitter posts exhibiting minority stress, which is a unique pressure faced by the members of the LGBTQ population due to their sexual and gender identities. For this task, we collect a set of 20,593,823 posts by 7,241 self-disclosed LGBTQ users and annotate a randomly selected subset of 2800 posts. We demonstrate that our best pre-pandemic and during pandemic models show strong and stable performance for detecting posts that contain minority stress. We investigate the linguistic differences in minority stress posts across pre- and during-pandemic periods. We find that anger words are strongly associated with minority stress during the COVID-19 pandemic. We explore the impact of the pandemic on the emotional states of the LGBTQ population by conducting controlled comparisons with the general population. We adopt propensity score-based matching to perform a causal analysis. The results show that the LBGTQ population have a greater increase in the usage of cognitive words and worsened observable attribute in the usage of positive emotion words than the group of the general population with similar pre-pandemic behavioral attributes.
A Non-negative Matrix Factorization Based Method for Quantifying Rhythms of Activity and Sleep and Chronotypes Using Mobile Phone Data
Sep 21, 2020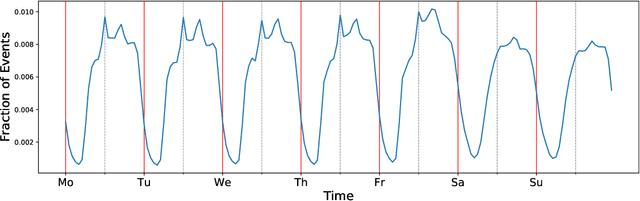
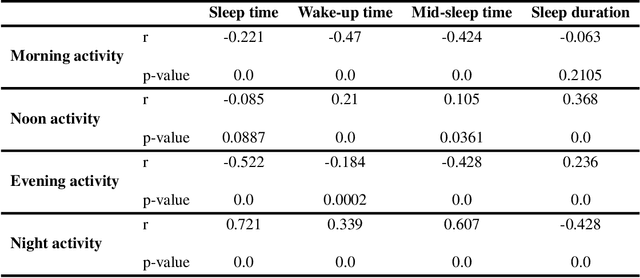
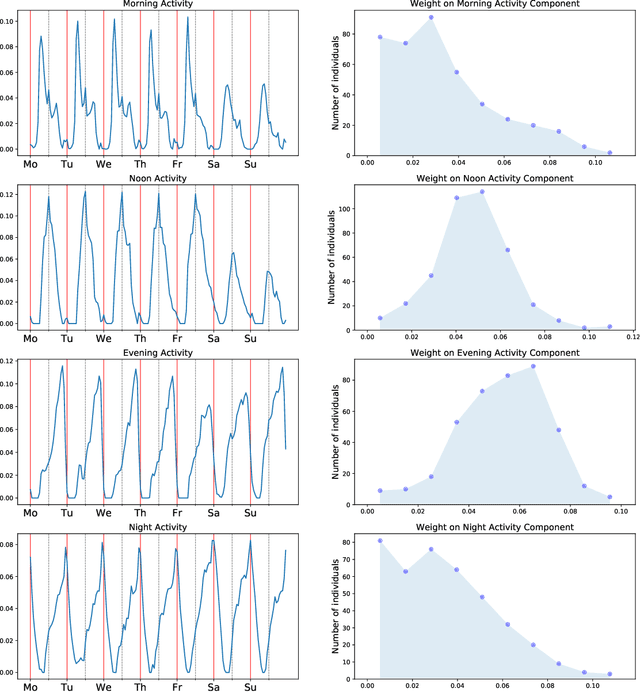
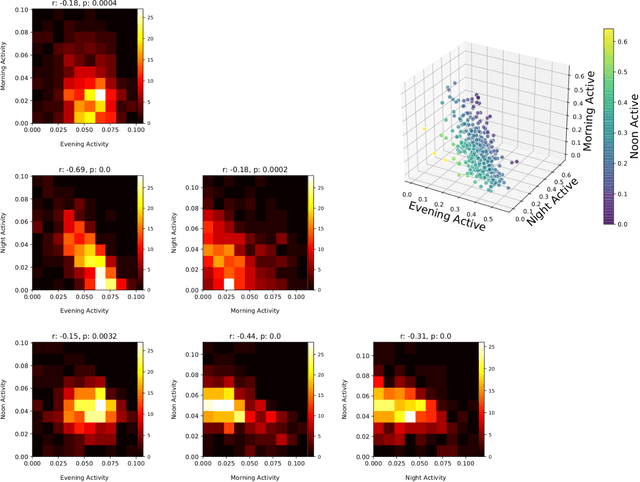
Human activities follow daily, weekly, and seasonal rhythms. The emergence of these rhythms is related to physiology and natural cycles as well as social constructs. The human body and biological functions undergo near 24-hour rhythms (circadian rhythms). The frequency of these rhythms is more or less similar across people, but its phase is different. In the chronobiology literature, based on the propensity to sleep at different hours of the day, people are categorized into morning-type, evening-type, and intermediate-type groups called \textit{chronotypes}. This typology is typically based on carefully designed questionnaires or manually crafted features drawing on data on timings of people's activity. Here we develop a fully data-driven (unsupervised) method to decompose individual temporal activity patterns into components. This has the advantage of not including any predetermined assumptions about sleep and activity hours, but the results are fully context-dependent and determined by the most prominent features of the activity data. Using a year-long dataset from mobile phone screen usage logs of 400 people, we find four emergent temporal components: morning activity, night activity, evening activity and activity at noon. Individual behavior can be reduced to weights on these four components. We do not observe any clear emergent categories of people based on the weights, but individuals are rather placed on a continuous spectrum according to the timings of their activities. High loads on morning and night components highly correlate with going to bed and waking up times. Our work points towards a data-driven way of categorizing people based on their full daily and weekly rhythms of activity and behavior, rather than focusing mainly on the timing of their sleeping periods.