 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime to Cite: Modeling Citation Networks using the Dynamic Impact Single-Event Embedding Model
Feb 28, 2024Understanding the structure and dynamics of scientific research, i.e., the science of science (SciSci), has become an important area of research in order to address imminent questions including how scholars interact to advance science, how disciplines are related and evolve, and how research impact can be quantified and predicted. Central to the study of SciSci has been the analysis of citation networks. Here, two prominent modeling methodologies have been employed: one is to assess the citation impact dynamics of papers using parametric distributions, and the other is to embed the citation networks in a latent space optimal for characterizing the static relations between papers in terms of their citations. Interestingly, citation networks are a prominent example of single-event dynamic networks, i.e., networks for which each dyad only has a single event (i.e., the point in time of citation). We presently propose a novel likelihood function for the characterization of such single-event networks. Using this likelihood, we propose the Dynamic Impact Single-Event Embedding model (DISEE). The \textsc{\modelabbrev} model characterizes the scientific interactions in terms of a latent distance model in which random effects account for citation heterogeneity while the time-varying impact is characterized using existing parametric representations for assessment of dynamic impact. We highlight the proposed approach on several real citation networks finding that the DISEE well reconciles static latent distance network embedding approaches with classical dynamic impact assessments.
Using Sequences of Life-events to Predict Human Lives
Jun 05, 2023Over the past decade, machine learning has revolutionized computers' ability to analyze text through flexible computational models. Due to their structural similarity to written language, transformer-based architectures have also shown promise as tools to make sense of a range of multi-variate sequences from protein-structures, music, electronic health records to weather-forecasts. We can also represent human lives in a way that shares this structural similarity to language. From one perspective, lives are simply sequences of events: People are born, visit the pediatrician, start school, move to a new location, get married, and so on. Here, we exploit this similarity to adapt innovations from natural language processing to examine the evolution and predictability of human lives based on detailed event sequences. We do this by drawing on arguably the most comprehensive registry data in existence, available for an entire nation of more than six million individuals across decades. Our data include information about life-events related to health, education, occupation, income, address, and working hours, recorded with day-to-day resolution. We create embeddings of life-events in a single vector space showing that this embedding space is robust and highly structured. Our models allow us to predict diverse outcomes ranging from early mortality to personality nuances, outperforming state-of-the-art models by a wide margin. Using methods for interpreting deep learning models, we probe the algorithm to understand the factors that enable our predictions. Our framework allows researchers to identify new potential mechanisms that impact life outcomes and associated possibilities for personalized interventions.
Large Language Models Converge on Brain-Like Word Representations
Jun 02, 2023One of the greatest puzzles of all time is how understanding arises from neural mechanics. Our brains are networks of billions of biological neurons transmitting chemical and electrical signals along their connections. Large language models are networks of millions or billions of digital neurons, implementing functions that read the output of other functions in complex networks. The failure to see how meaning would arise from such mechanics has led many cognitive scientists and philosophers to various forms of dualism -- and many artificial intelligence researchers to dismiss large language models as stochastic parrots or jpeg-like compressions of text corpora. We show that human-like representations arise in large language models. Specifically, the larger neural language models get, the more their representations are structurally similar to neural response measurements from brain imaging.
Dialectograms: Machine Learning Differences between Discursive Communities
Feb 11, 2023
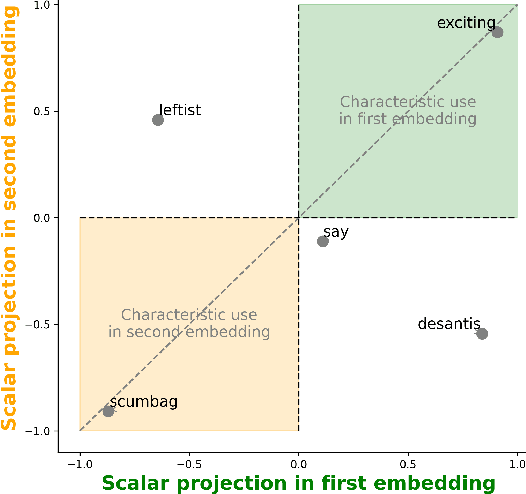


Word embeddings provide an unsupervised way to understand differences in word usage between discursive communities. A number of recent papers have focused on identifying words that are used differently by two or more communities. But word embeddings are complex, high-dimensional spaces and a focus on identifying differences only captures a fraction of their richness. Here, we take a step towards leveraging the richness of the full embedding space, by using word embeddings to map out how words are used differently. Specifically, we describe the construction of dialectograms, an unsupervised way to visually explore the characteristic ways in which each community use a focal word. Based on these dialectograms, we provide a new measure of the degree to which words are used differently that overcomes the tendency for existing measures to pick out low frequent or polysemous words. We apply our methods to explore the discourses of two US political subreddits and show how our methods identify stark affective polarisation of politicians and political entities, differences in the assessment of proper political action as well as disagreement about whether certain issues require political intervention at all.
Recovering lost and absent information in temporal networks
Jul 22, 2021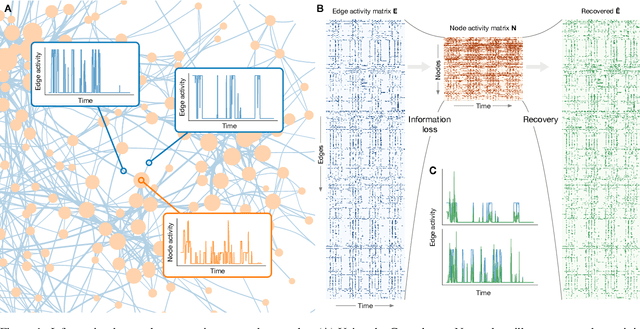
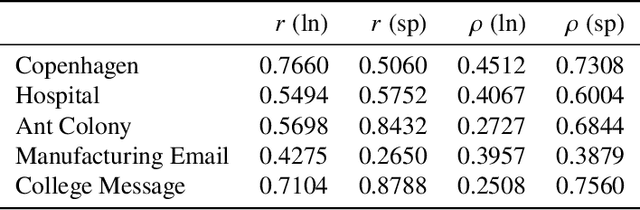
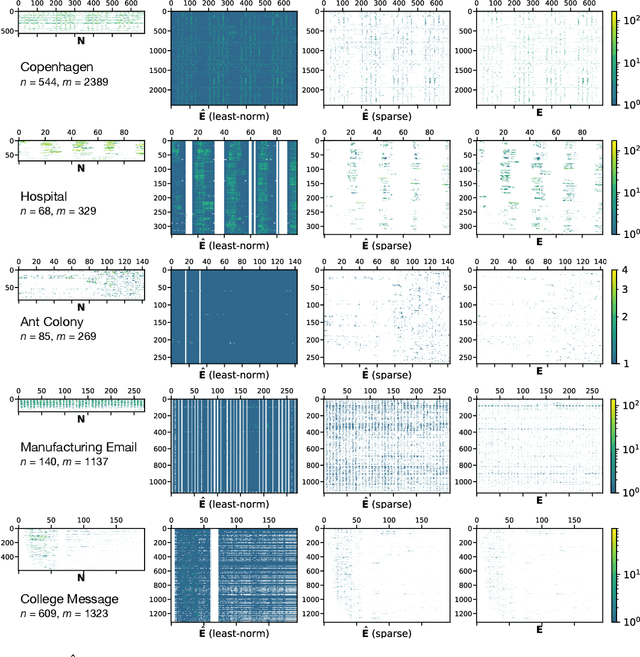
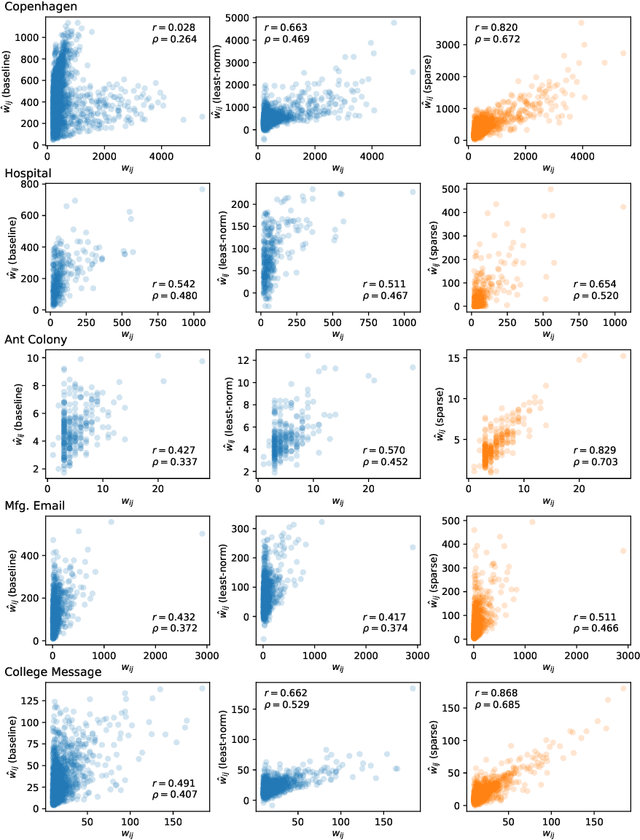
The full range of activity in a temporal network is captured in its edge activity data -- time series encoding the tie strengths or on-off dynamics of each edge in the network. However, in many practical applications, edge-level data are unavailable, and the network analyses must rely instead on node activity data which aggregates the edge-activity data and thus is less informative. This raises the question: Is it possible to use the static network to recover the richer edge activities from the node activities? Here we show that recovery is possible, often with a surprising degree of accuracy given how much information is lost, and that the recovered data are useful for subsequent network analysis tasks. Recovery is more difficult when network density increases, either topologically or dynamically, but exploiting dynamical and topological sparsity enables effective solutions to the recovery problem. We formally characterize the difficulty of the recovery problem both theoretically and empirically, proving the conditions under which recovery errors can be bounded and showing that, even when these conditions are not met, good quality solutions can still be derived. Effective recovery carries both promise and peril, as it enables deeper scientific study of complex systems but in the context of social systems also raises privacy concerns when social information can be aggregated across multiple data sources.
A Non-negative Matrix Factorization Based Method for Quantifying Rhythms of Activity and Sleep and Chronotypes Using Mobile Phone Data
Sep 21, 2020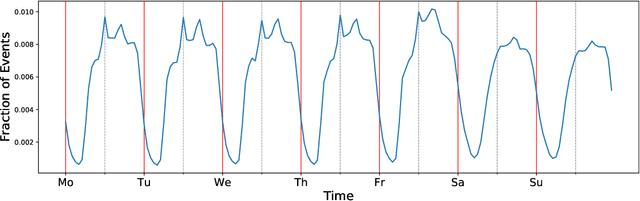
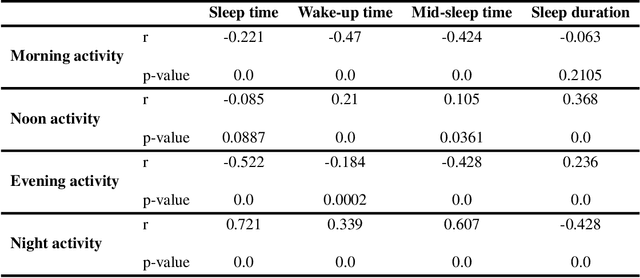
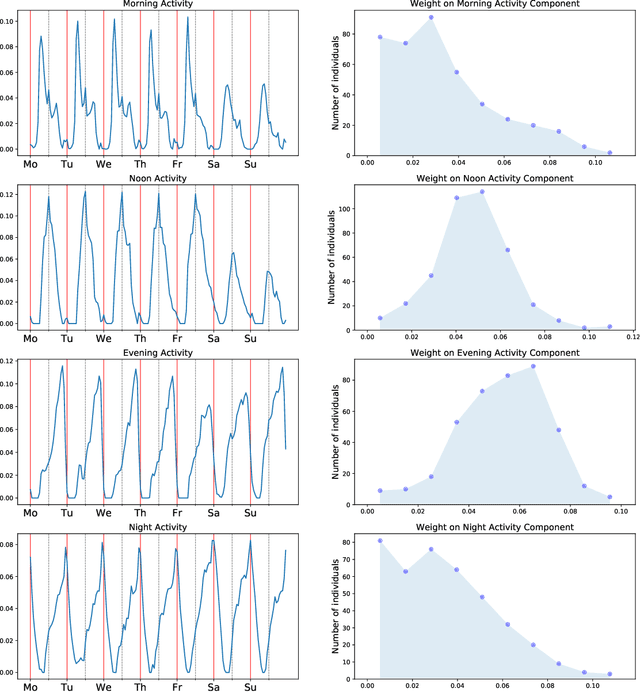
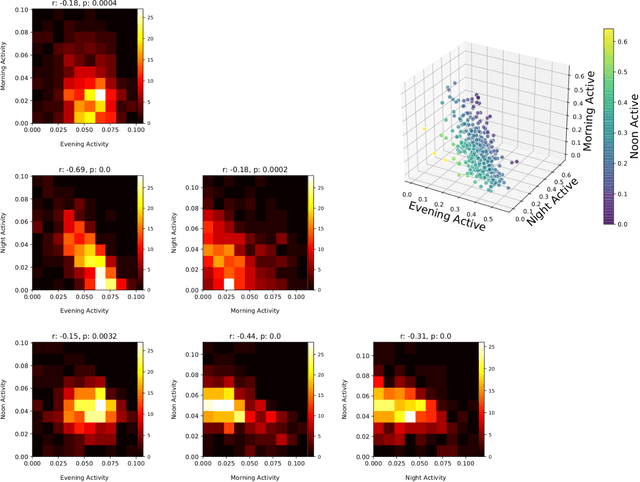
Human activities follow daily, weekly, and seasonal rhythms. The emergence of these rhythms is related to physiology and natural cycles as well as social constructs. The human body and biological functions undergo near 24-hour rhythms (circadian rhythms). The frequency of these rhythms is more or less similar across people, but its phase is different. In the chronobiology literature, based on the propensity to sleep at different hours of the day, people are categorized into morning-type, evening-type, and intermediate-type groups called \textit{chronotypes}. This typology is typically based on carefully designed questionnaires or manually crafted features drawing on data on timings of people's activity. Here we develop a fully data-driven (unsupervised) method to decompose individual temporal activity patterns into components. This has the advantage of not including any predetermined assumptions about sleep and activity hours, but the results are fully context-dependent and determined by the most prominent features of the activity data. Using a year-long dataset from mobile phone screen usage logs of 400 people, we find four emergent temporal components: morning activity, night activity, evening activity and activity at noon. Individual behavior can be reduced to weights on these four components. We do not observe any clear emergent categories of people based on the weights, but individuals are rather placed on a continuous spectrum according to the timings of their activities. High loads on morning and night components highly correlate with going to bed and waking up times. Our work points towards a data-driven way of categorizing people based on their full daily and weekly rhythms of activity and behavior, rather than focusing mainly on the timing of their sleeping periods.
Modeling the Temporal Nature of Human Behavior for Demographics Prediction
Nov 15, 2017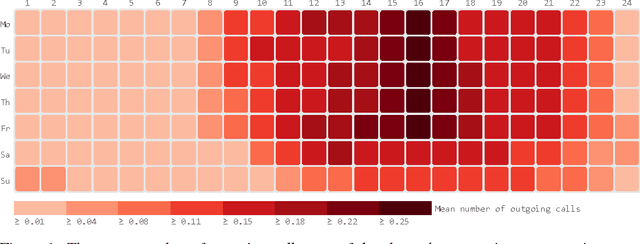
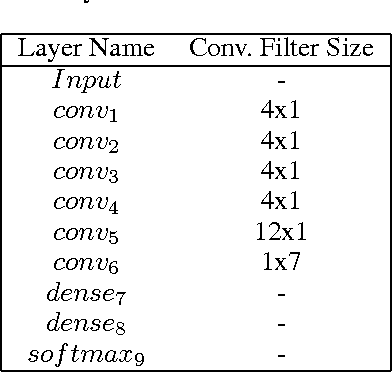
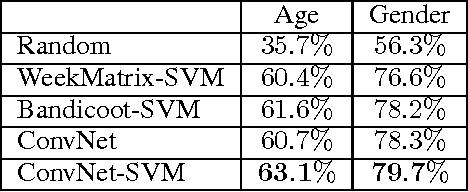

Mobile phone metadata is increasingly used for humanitarian purposes in developing countries as traditional data is scarce. Basic demographic information is however often absent from mobile phone datasets, limiting the operational impact of the datasets. For these reasons, there has been a growing interest in predicting demographic information from mobile phone metadata. Previous work focused on creating increasingly advanced features to be modeled with standard machine learning algorithms. We here instead model the raw mobile phone metadata directly using deep learning, exploiting the temporal nature of the patterns in the data. From high-level assumptions we design a data representation and convolutional network architecture for modeling patterns within a week. We then examine three strategies for aggregating patterns across weeks and show that our method reaches state-of-the-art accuracy on both age and gender prediction using only the temporal modality in mobile metadata. We finally validate our method on low activity users and evaluate the modeling assumptions.
Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm
Oct 07, 2017
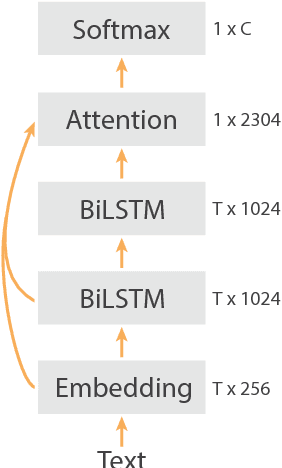
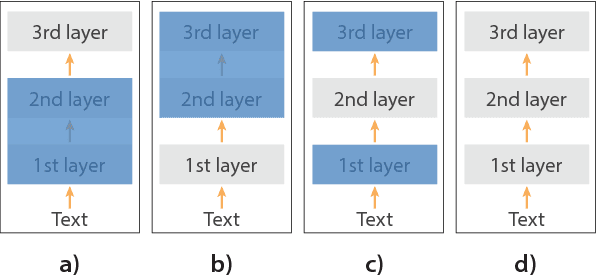
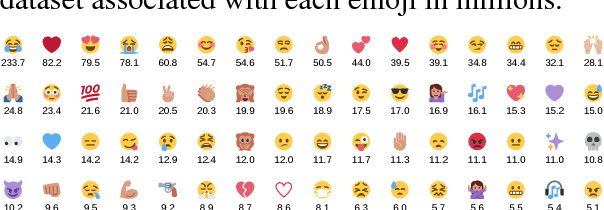
NLP tasks are often limited by scarcity of manually annotated data. In social media sentiment analysis and related tasks, researchers have therefore used binarized emoticons and specific hashtags as forms of distant supervision. Our paper shows that by extending the distant supervision to a more diverse set of noisy labels, the models can learn richer representations. Through emoji prediction on a dataset of 1246 million tweets containing one of 64 common emojis we obtain state-of-the-art performance on 8 benchmark datasets within sentiment, emotion and sarcasm detection using a single pretrained model. Our analyses confirm that the diversity of our emotional labels yield a performance improvement over previous distant supervision approaches.