 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecovering lost and absent information in temporal networks
Jul 22, 2021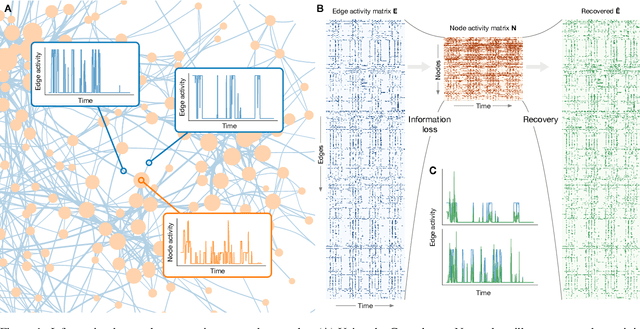
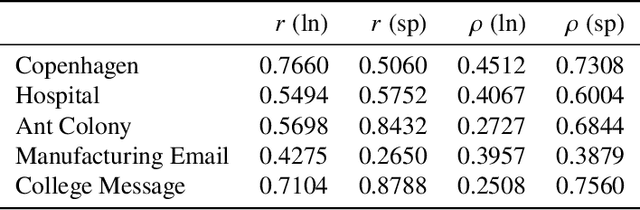
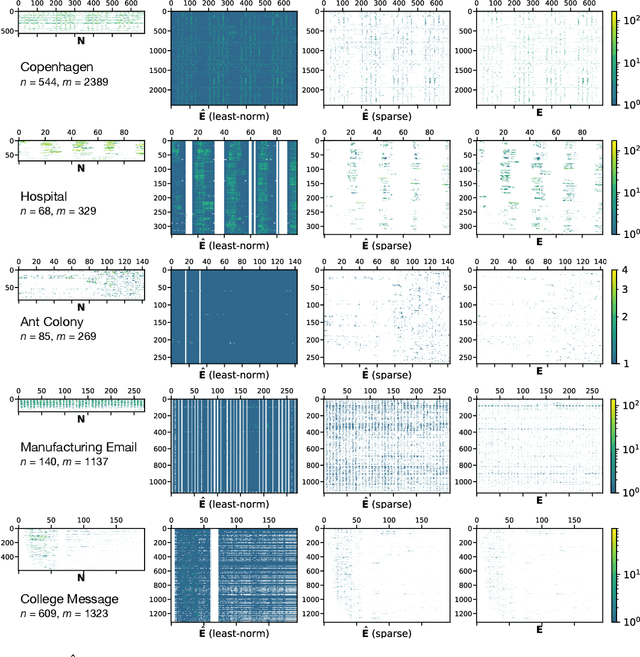
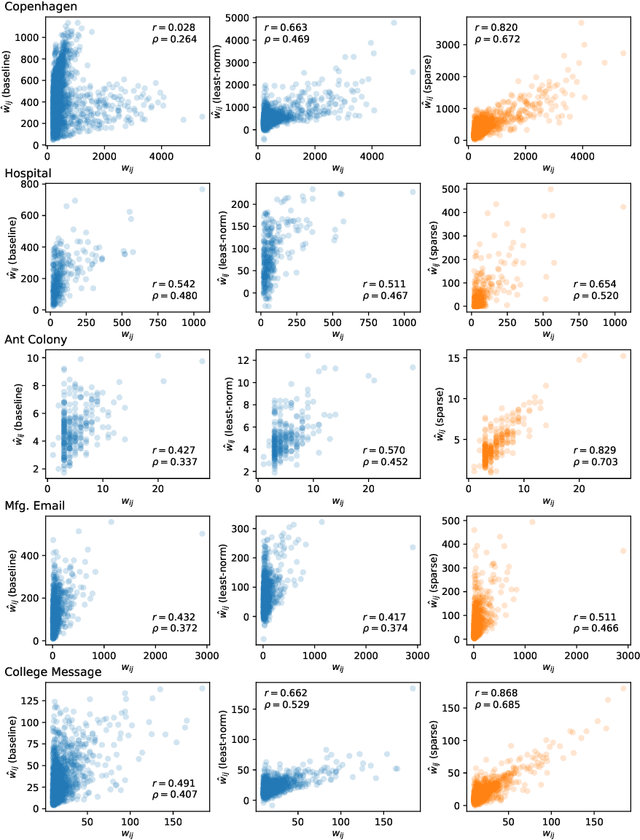
The full range of activity in a temporal network is captured in its edge activity data -- time series encoding the tie strengths or on-off dynamics of each edge in the network. However, in many practical applications, edge-level data are unavailable, and the network analyses must rely instead on node activity data which aggregates the edge-activity data and thus is less informative. This raises the question: Is it possible to use the static network to recover the richer edge activities from the node activities? Here we show that recovery is possible, often with a surprising degree of accuracy given how much information is lost, and that the recovered data are useful for subsequent network analysis tasks. Recovery is more difficult when network density increases, either topologically or dynamically, but exploiting dynamical and topological sparsity enables effective solutions to the recovery problem. We formally characterize the difficulty of the recovery problem both theoretically and empirically, proving the conditions under which recovery errors can be bounded and showing that, even when these conditions are not met, good quality solutions can still be derived. Effective recovery carries both promise and peril, as it enables deeper scientific study of complex systems but in the context of social systems also raises privacy concerns when social information can be aggregated across multiple data sources.
Efficient crowdsourcing of crowd-generated microtasks
Dec 10, 2019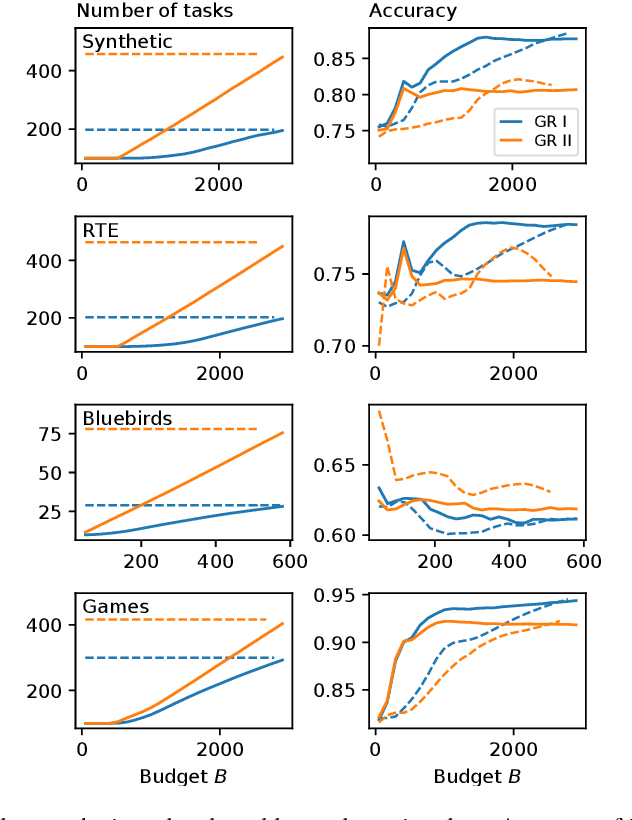
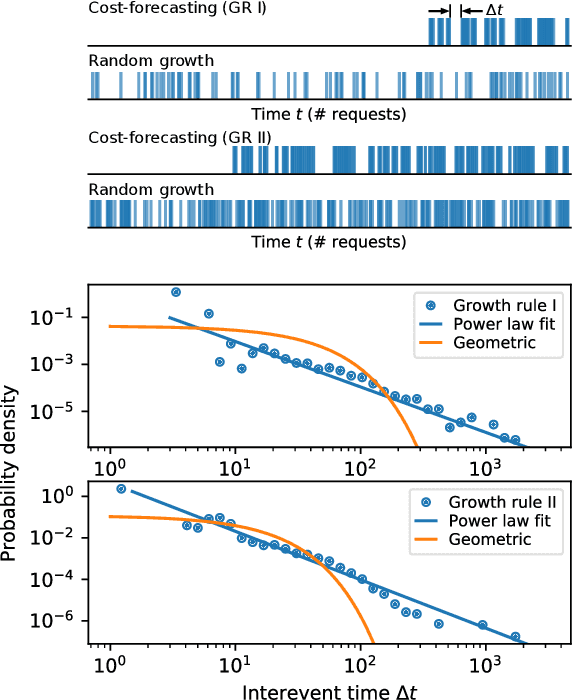
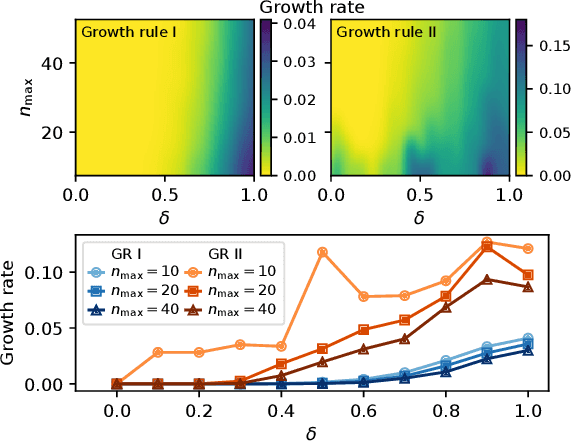
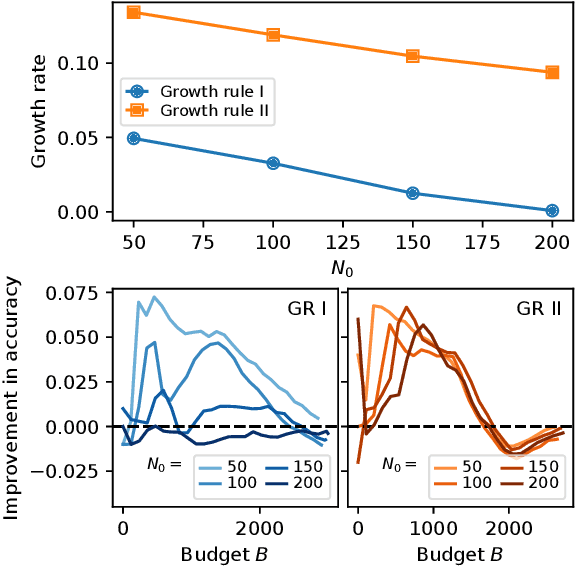
Allowing members of the crowd to propose novel microtasks for one another is an effective way to combine the efficiencies of traditional microtask work with the inventiveness and hypothesis generation potential of human workers. However, microtask proposal leads to a growing set of tasks that may overwhelm limited crowdsourcer resources. Crowdsourcers can employ methods to utilize their resources efficiently, but algorithmic approaches to efficient crowdsourcing generally require a fixed task set of known size. In this paper, we introduce *cost forecasting* as a means for a crowdsourcer to use efficient crowdsourcing algorithms with a growing set of microtasks. Cost forecasting allows the crowdsourcer to decide between eliciting new tasks from the crowd or receiving responses to existing tasks based on whether or not new tasks will cost less to complete than existing tasks, efficiently balancing resources as crowdsourcing occurs. Experiments with real and synthetic crowdsourcing data show that cost forecasting leads to improved accuracy. Accuracy and efficiency gains for crowd-generated microtasks hold the promise to further leverage the creativity and wisdom of the crowd, with applications such as generating more informative and diverse training data for machine learning applications and improving the performance of user-generated content and question-answering platforms.
UAFS: Uncertainty-Aware Feature Selection for Problems with Missing Data
Apr 02, 2019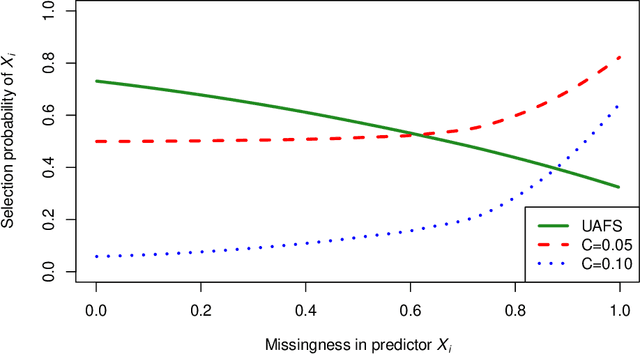
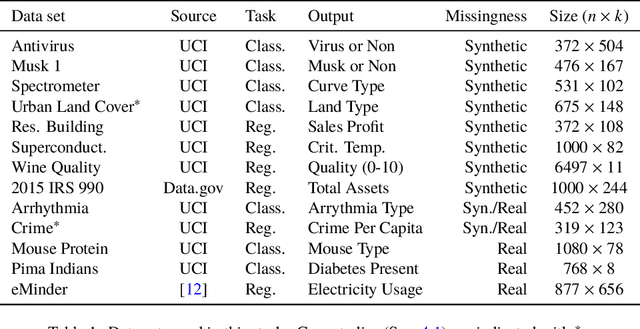
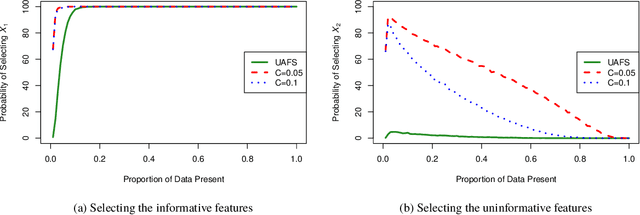
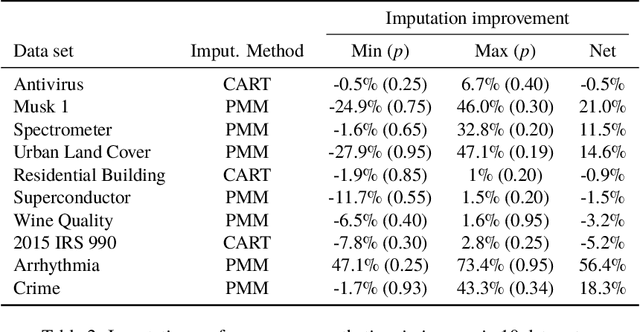
Missing data are a concern in many real world data sets and imputation methods are often needed to estimate the values of missing data, but data sets with excessive missingness and high dimensionality challenge most approaches to imputation. Here we show that appropriate feature selection can be an effective preprocessing step for imputation, allowing for more accurate imputation and subsequent model predictions. The key feature of this preprocessing is that it incorporates uncertainty: by accounting for uncertainty due to missingness when selecting features we can reduce the degree of missingness while also limiting the number of uninformative features being used to make predictive models. We introduce a method to perform uncertainty-aware feature selection (UAFS), provide a theoretical motivation, and test UAFS on both real and synthetic problems, demonstrating that across a variety of data sets and levels of missingness we can improve the accuracy of imputations. Improved imputation due to UAFS also results in improved prediction accuracy when performing supervised learning using these imputed data sets. Our UAFS method is general and can be fruitfully coupled with a variety of imputation methods.
Accurate inference of crowdsourcing properties when using efficient allocation strategies
Mar 07, 2019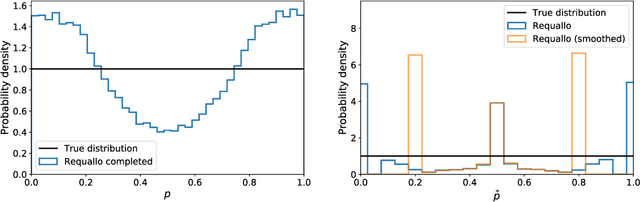
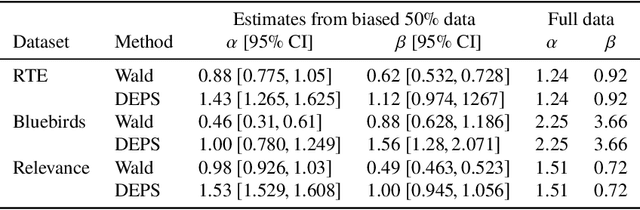
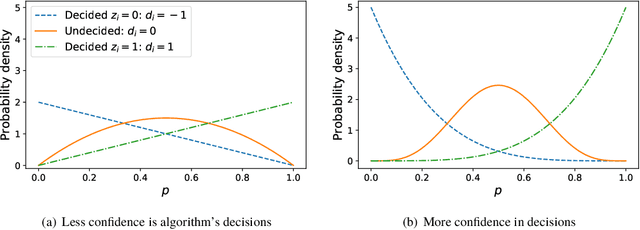
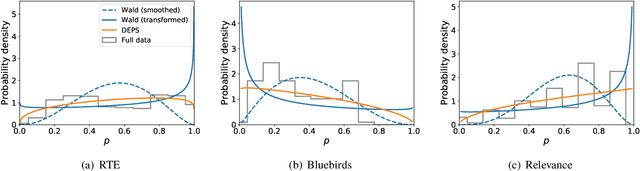
Allocation strategies improve the efficiency of crowdsourcing by decreasing the work needed to complete individual tasks accurately. However, these algorithms introduce bias by preferentially allocating workers onto easy tasks, leading to sets of completed tasks that are no longer representative of all tasks. This bias challenges inference of problem-wide properties such as typical task difficulty or crowd properties such as worker completion times, important information that goes beyond the crowd responses themselves. Here we study inference about problem properties when using an allocation algorithm to improve crowd efficiency. We introduce Decision-Explicit Probability Sampling (DEPS), a method to perform inference of problem properties while accounting for the potential bias introduced by an allocation strategy. Experiments on real and synthetic crowdsourcing data show that DEPS outperforms baseline inference methods while still leveraging the efficiency gains of the allocation method. The ability to perform accurate inference of general properties when using non-representative data allows crowdsourcers to extract more knowledge out of a given crowdsourced dataset.
Inferring the size of the causal universe: features and fusion of causal attribution networks
Dec 14, 2018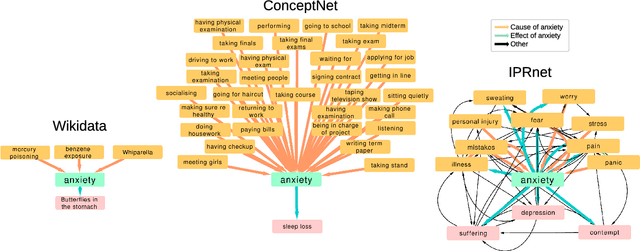
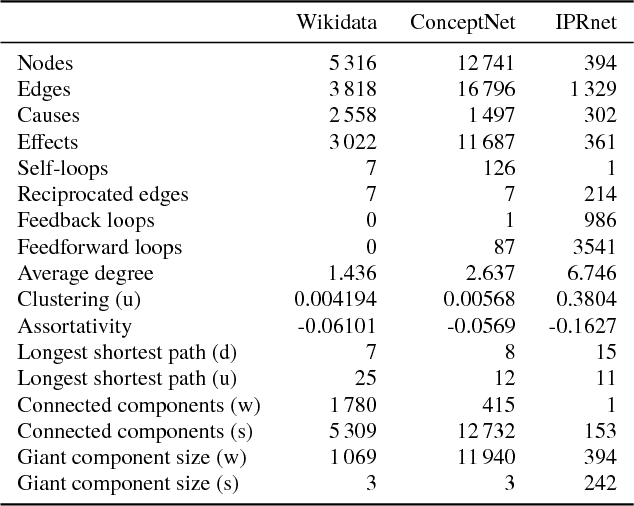
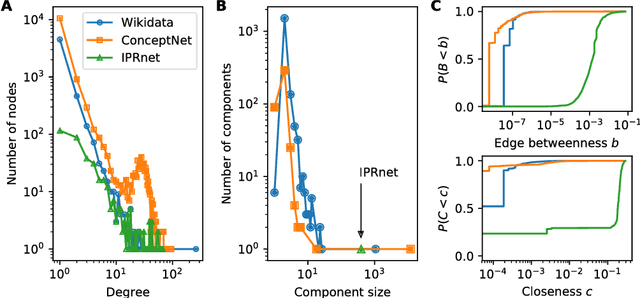
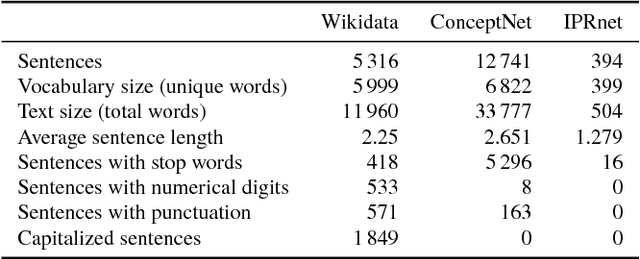
Cause-and-effect reasoning, the attribution of effects to causes, is one of the most powerful and unique skills humans possess. Multiple surveys are mapping out causal attributions as networks, but it is unclear how well these efforts can be combined. Further, the total size of the collective causal attribution network held by humans is currently unknown, making it challenging to assess the progress of these surveys. Here we study three causal attribution networks to determine how well they can be combined into a single network. Combining these networks requires dealing with ambiguous nodes, as nodes represent written descriptions of causes and effects and different descriptions may exist for the same concept. We introduce NetFUSES, a method for combining networks with ambiguous nodes. Crucially, treating the different causal attributions networks as independent samples allows us to use their overlap to estimate the total size of the collective causal attribution network. We find that existing surveys capture 5.77% $\pm$ 0.781% of the $\approx$293 000 causes and effects estimated to exist, and 0.198% $\pm$ 0.174% of the $\approx$10 200 000 attributed cause-effect relationships.
Neural language representations predict outcomes of scientific research
May 17, 2018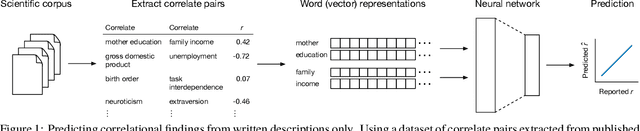
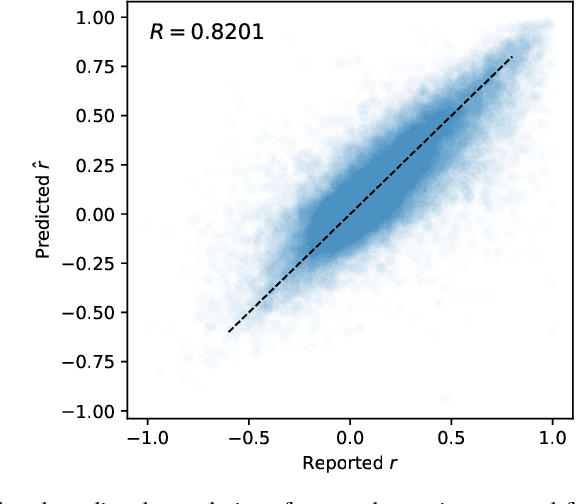
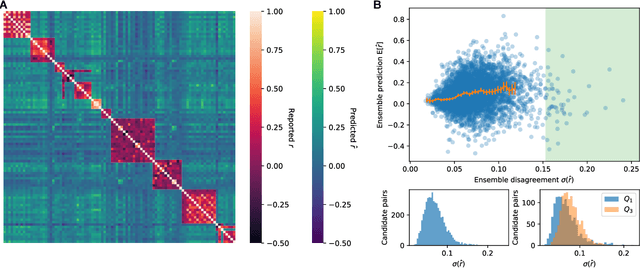
Many research fields codify their findings in standard formats, often by reporting correlations between quantities of interest. But the space of all testable correlates is far larger than scientific resources can currently address, so the ability to accurately predict correlations would be useful to plan research and allocate resources. Using a dataset of approximately 170,000 correlational findings extracted from leading social science journals, we show that a trained neural network can accurately predict the reported correlations using only the text descriptions of the correlates. Accurate predictive models such as these can guide scientists towards promising untested correlates, better quantify the information gained from new findings, and has implications for moving artificial intelligence systems from predicting structures to predicting relationships in the real world.
Crowd ideation of supervised learning problems
Feb 14, 2018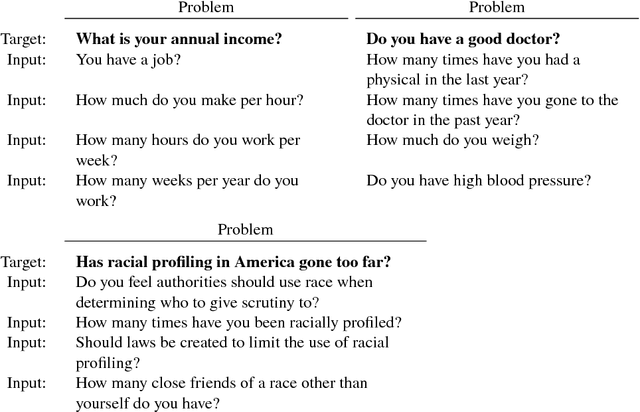


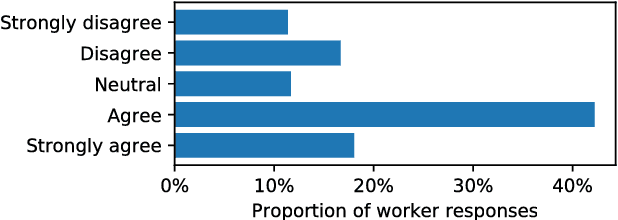
Crowdsourcing is an important avenue for collecting machine learning data, but crowdsourcing can go beyond simple data collection by employing the creativity and wisdom of crowd workers. Yet crowd participants are unlikely to be experts in statistics or predictive modeling, and it is not clear how well non-experts can contribute creatively to the process of machine learning. Here we study an end-to-end crowdsourcing algorithm where groups of non-expert workers propose supervised learning problems, rank and categorize those problems, and then provide data to train predictive models on those problems. Problem proposal includes and extends feature engineering because workers propose the entire problem, not only the input features but also the target variable. We show that workers without machine learning experience can collectively construct useful datasets and that predictive models can be learned on these datasets. In our experiments, the problems proposed by workers covered a broad range of topics, from politics and current events to problems capturing health behavior, demographics, and more. Workers also favored questions showing positively correlated relationships, which has interesting implications given many supervised learning methods perform as well with strong negative correlations. Proper instructions are crucial for non-experts, so we also conducted a randomized trial to understand how different instructions may influence the types of problems proposed by workers. In general, shifting the focus of machine learning tasks from designing and training individual predictive models to problem proposal allows crowdsourcers to design requirements for problems of interest and then guide workers towards contributing to the most suitable problems.
Crowdsourcing Predictors of Residential Electric Energy Usage
Sep 08, 2017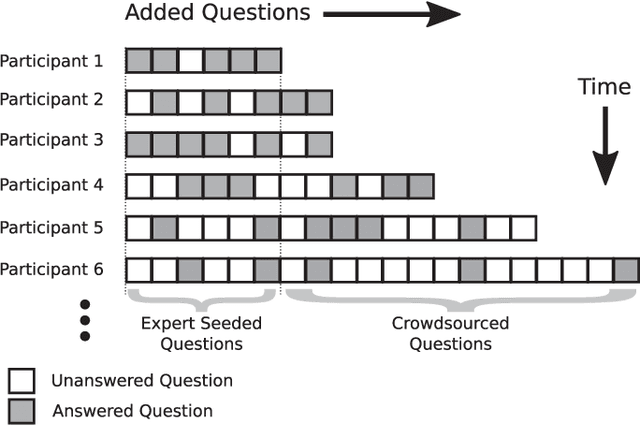

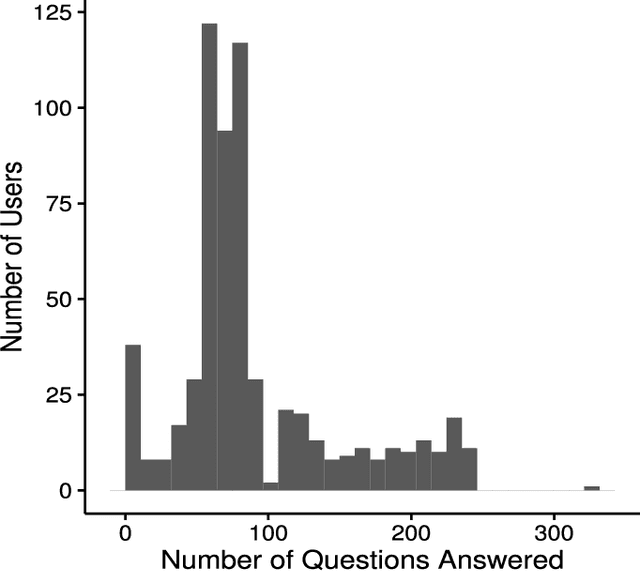
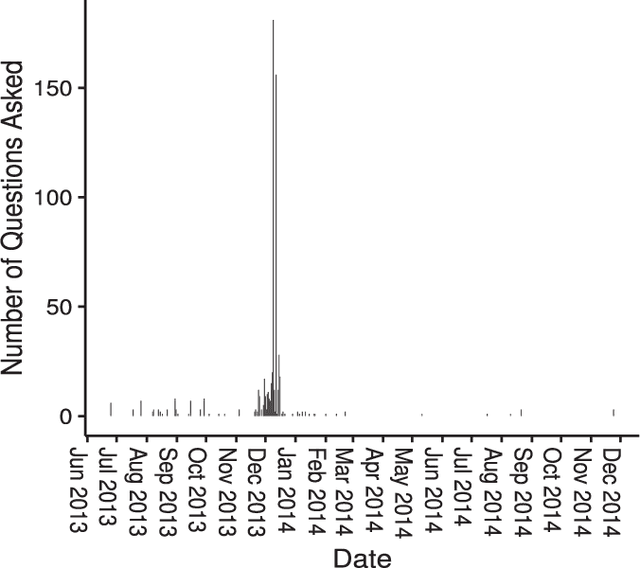
Crowdsourcing has been successfully applied in many domains including astronomy, cryptography and biology. In order to test its potential for useful application in a Smart Grid context, this paper investigates the extent to which a crowd can contribute predictive hypotheses to a model of residential electric energy consumption. In this experiment, the crowd generated hypotheses about factors that make one home different from another in terms of monthly energy usage. To implement this concept, we deployed a web-based system within which 627 residential electricity customers posed 632 questions that they thought predictive of energy usage. While this occurred, the same group provided 110,573 answers to these questions as they accumulated. Thus users both suggested the hypotheses that drive a predictive model and provided the data upon which the model is built. We used the resulting question and answer data to build a predictive model of monthly electric energy consumption, using random forest regression. Because of the sparse nature of the answer data, careful statistical work was needed to ensure that these models are valid. The results indicate that the crowd can generate useful hypotheses, despite the sparse nature of the dataset.
* 11 pages, 7 figures
Autocompletion interfaces make crowd workers slower, but their use promotes response diversity
Jul 21, 2017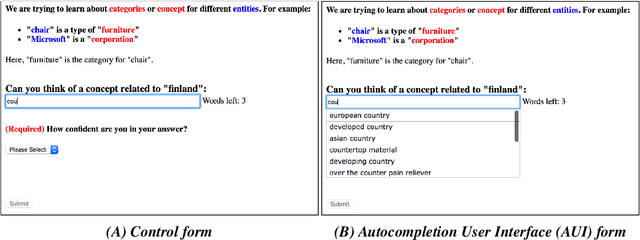
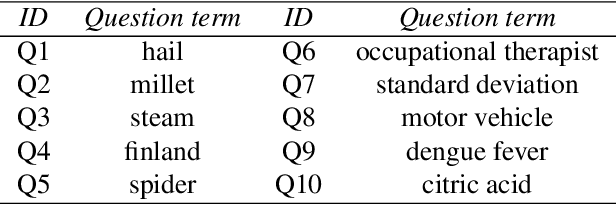
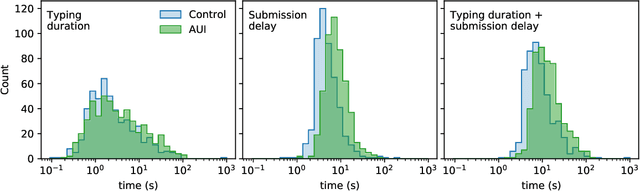
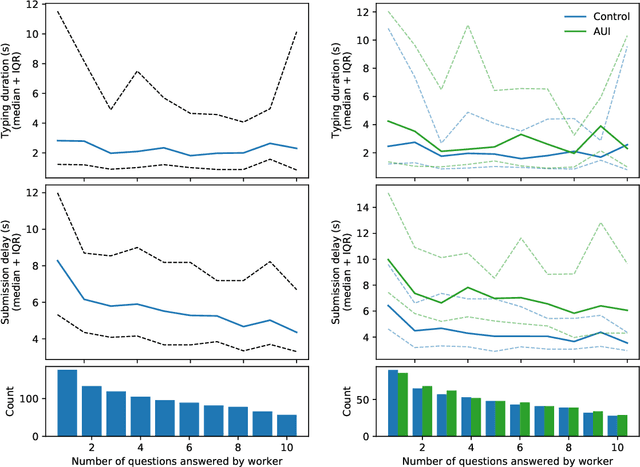
Creative tasks such as ideation or question proposal are powerful applications of crowdsourcing, yet the quantity of workers available for addressing practical problems is often insufficient. To enable scalable crowdsourcing thus requires gaining all possible efficiency and information from available workers. One option for text-focused tasks is to allow assistive technology, such as an autocompletion user interface (AUI), to help workers input text responses. But support for the efficacy of AUIs is mixed. Here we designed and conducted a randomized experiment where workers were asked to provide short text responses to given questions. Our experimental goal was to determine if an AUI helps workers respond more quickly and with improved consistency by mitigating typos and misspellings. Surprisingly, we found that neither occurred: workers assigned to the AUI treatment were slower than those assigned to the non-AUI control and their responses were more diverse, not less, than those of the control. Both the lexical and semantic diversities of responses were higher, with the latter measured using word2vec. A crowdsourcer interested in worker speed may want to avoid using an AUI, but using an AUI to boost response diversity may be valuable to crowdsourcers interested in receiving as much novel information from workers as possible.
Zipf's law is a consequence of coherent language production
Aug 05, 2016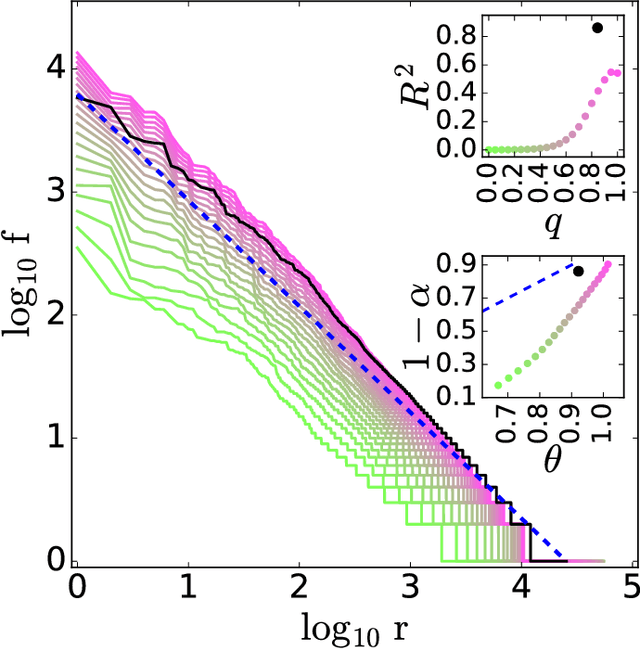
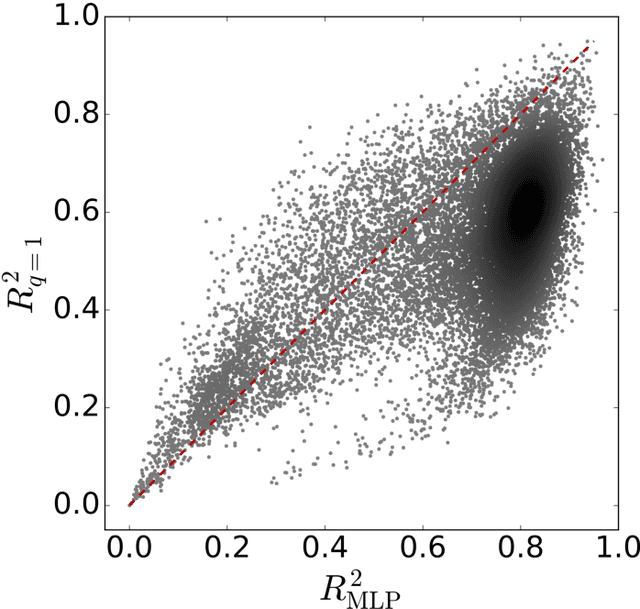
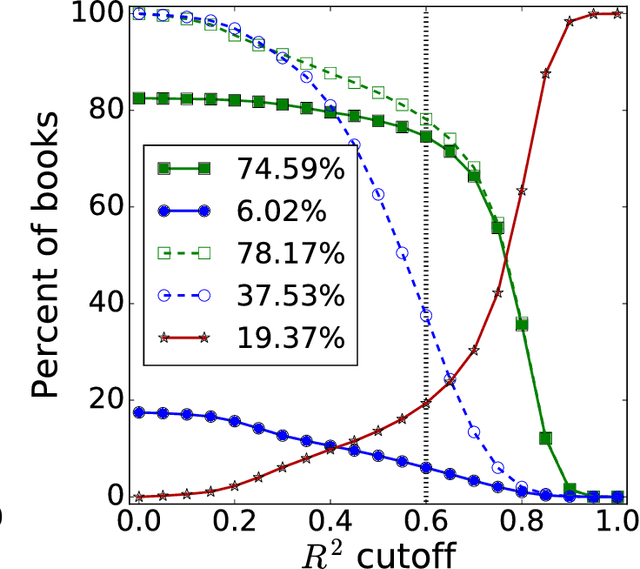
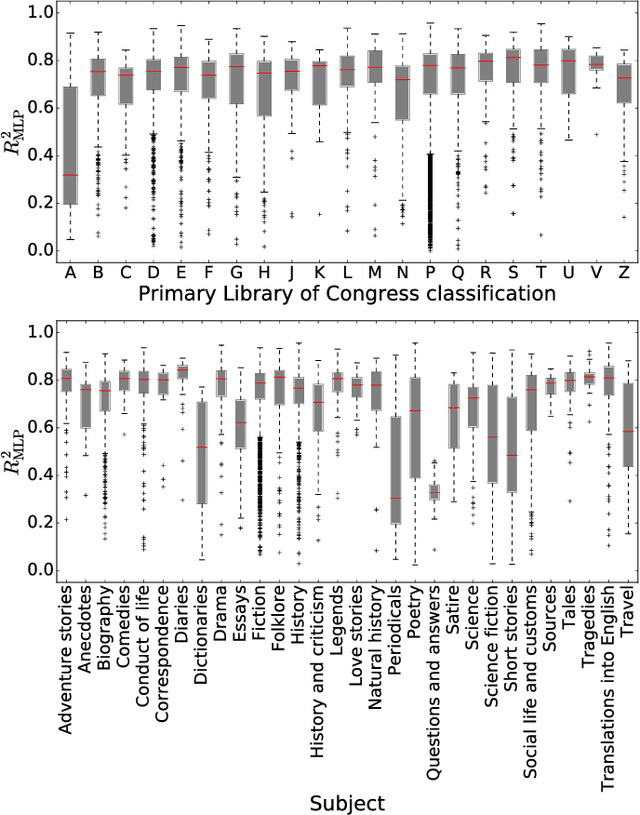
The task of text segmentation may be undertaken at many levels in text analysis---paragraphs, sentences, words, or even letters. Here, we focus on a relatively fine scale of segmentation, hypothesizing it to be in accord with a stochastic model of language generation, as the smallest scale where independent units of meaning are produced. Our goals in this letter include the development of methods for the segmentation of these minimal independent units, which produce feature-representations of texts that align with the independence assumption of the bag-of-terms model, commonly used for prediction and classification in computational text analysis. We also propose the measurement of texts' association (with respect to realized segmentations) to the model of language generation. We find (1) that our segmentations of phrases exhibit much better associations to the generation model than words and (2), that texts which are well fit are generally topically homogeneous. Because our generative model produces Zipf's law, our study further suggests that Zipf's law may be a consequence of homogeneity in language production.