 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteroceptive robustness through environment-mediated morphological development
Jun 20, 2018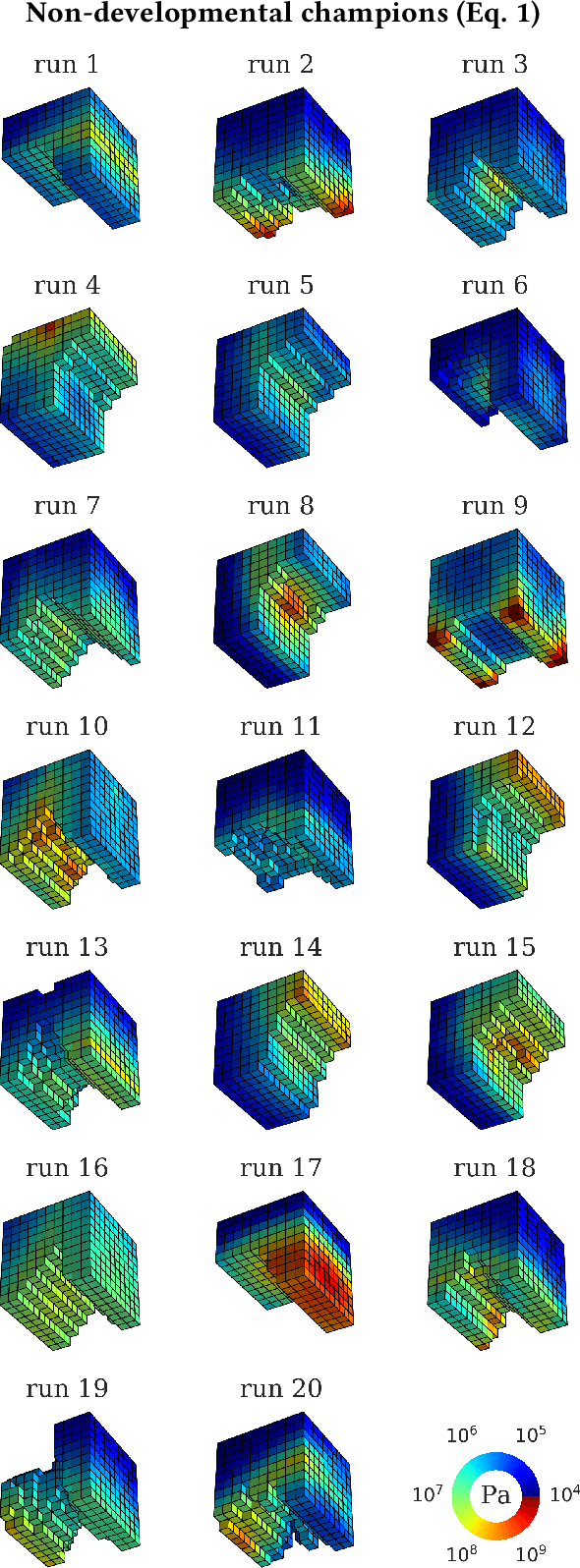
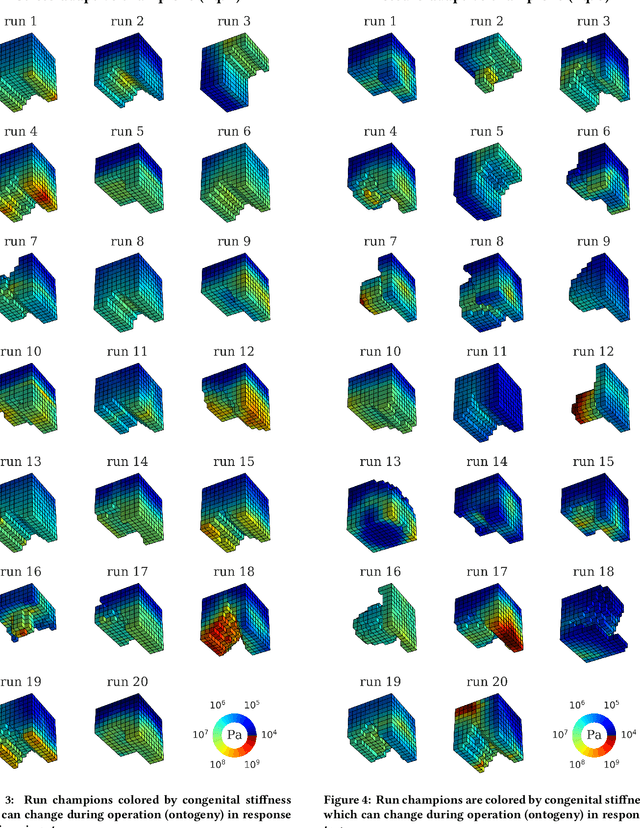
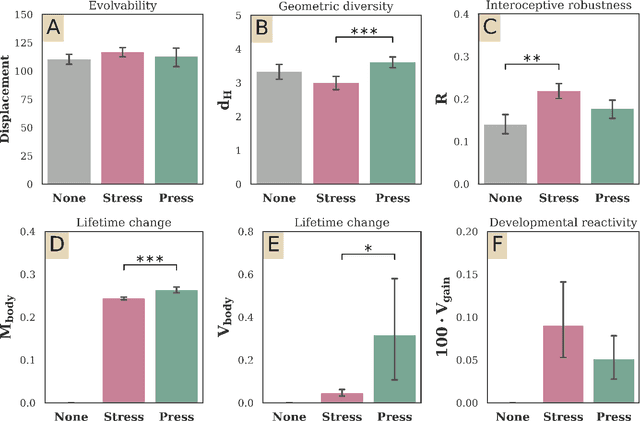
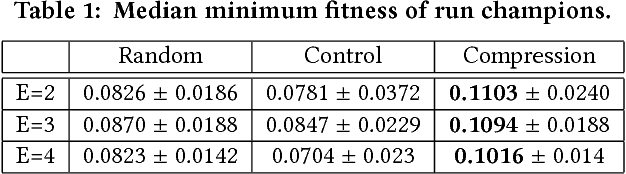
Typically, AI researchers and roboticists try to realize intelligent behavior in machines by tuning parameters of a predefined structure (body plan and/or neural network architecture) using evolutionary or learning algorithms. Another but not unrelated longstanding property of these systems is their brittleness to slight aberrations, as highlighted by the growing deep learning literature on adversarial examples. Here we show robustness can be achieved by evolving the geometry of soft robots, their control systems, and how their material properties develop in response to one particular interoceptive stimulus (engineering stress) during their lifetimes. By doing so we realized robots that were equally fit but more robust to extreme material defects (such as might occur during fabrication or by damage thereafter) than robots that did not develop during their lifetimes, or developed in response to a different interoceptive stimulus (pressure). This suggests that the interplay between changes in the containing systems of agents (body plan and/or neural architecture) at different temporal scales (evolutionary and developmental) along different modalities (geometry, material properties, synaptic weights) and in response to different signals (interoceptive and external perception) all dictate those agents' abilities to evolve or learn capable and robust strategies.
Combating catastrophic forgetting with developmental compression
Apr 12, 2018
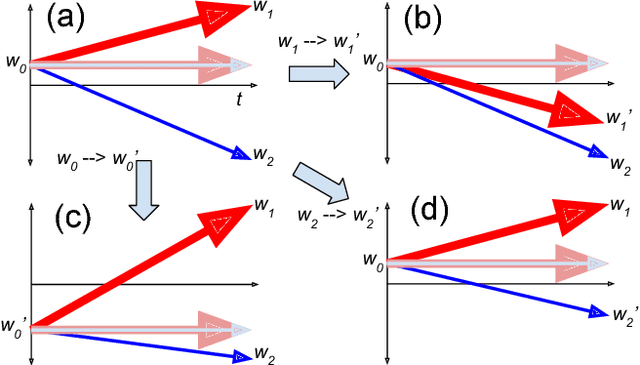
Generally intelligent agents exhibit successful behavior across problems in several settings. Endemic in approaches to realize such intelligence in machines is catastrophic forgetting: sequential learning corrupts knowledge obtained earlier in the sequence, or tasks antagonistically compete for system resources. Methods for obviating catastrophic forgetting have sought to identify and preserve features of the system necessary to solve one problem when learning to solve another, or to enforce modularity such that minimally overlapping sub-functions contain task specific knowledge. While successful, both approaches scale poorly because they require larger architectures as the number of training instances grows, causing different parts of the system to specialize for separate subsets of the data. Here we present a method for addressing catastrophic forgetting called developmental compression. It exploits the mild impacts of developmental mutations to lessen adverse changes to previously-evolved capabilities and `compresses' specialized neural networks into a generalized one. In the absence of domain knowledge, developmental compression produces systems that avoid overt specialization, alleviating the need to engineer a bespoke system for every task permutation and suggesting better scalability than existing approaches. We validate this method on a robot control problem and hope to extend this approach to other machine learning domains in the future.
Evolving Spatially Aggregated Features from Satellite Imagery for Regional Modeling
Dec 14, 2017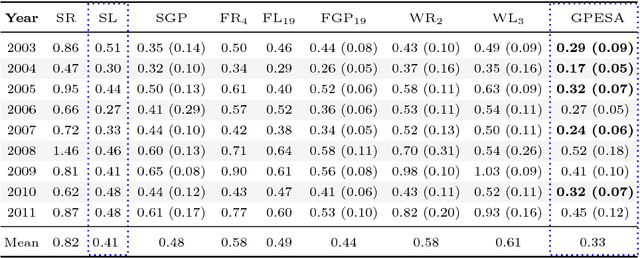
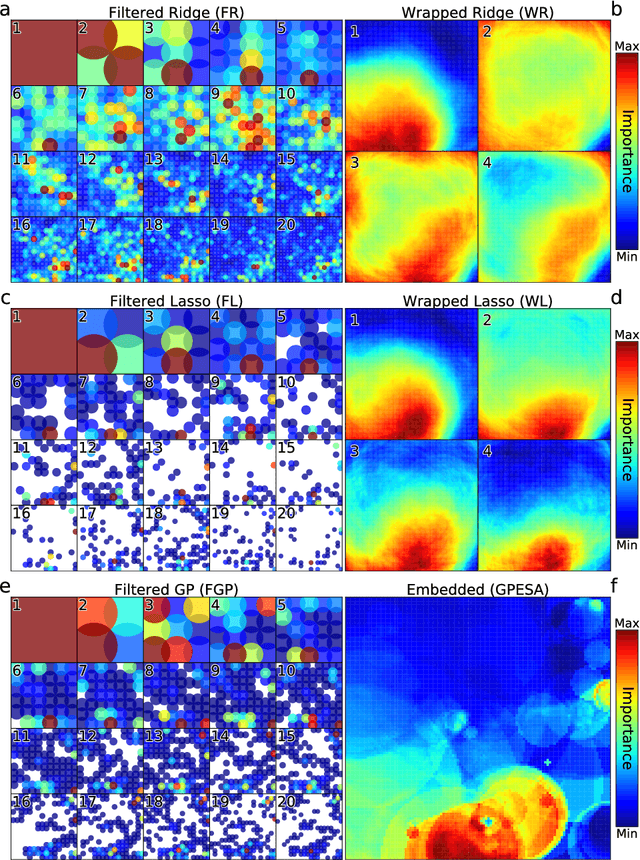
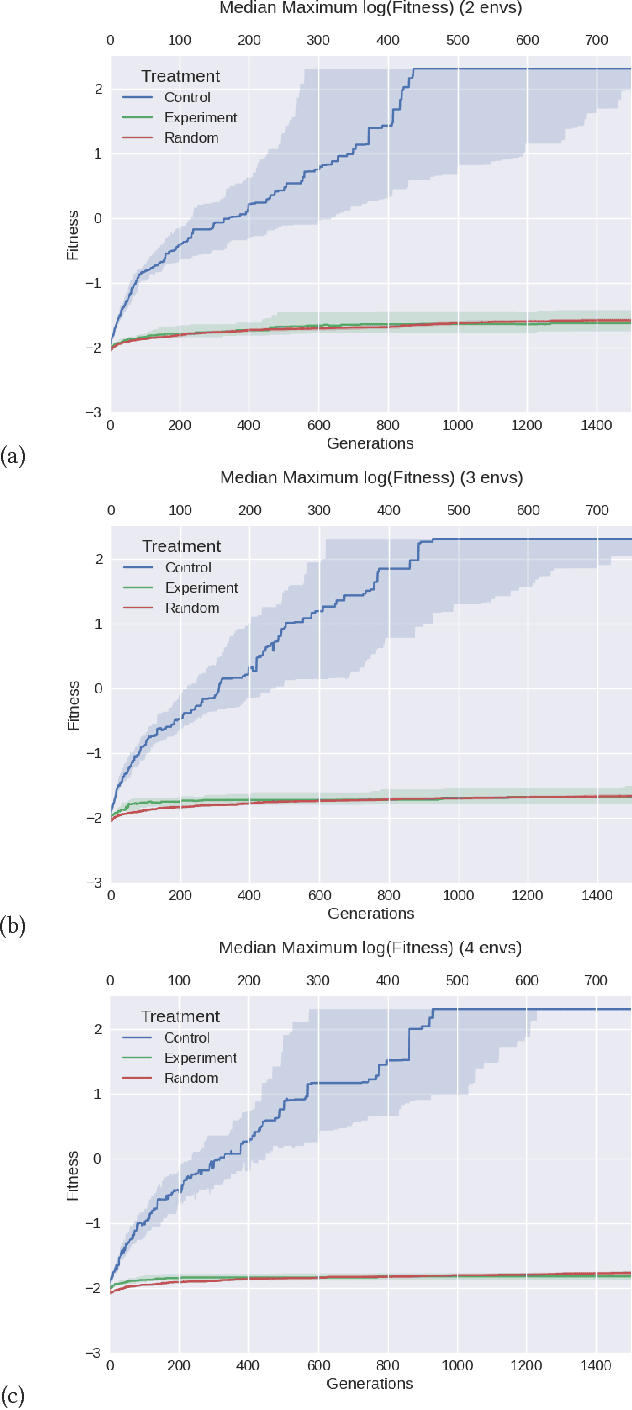
Satellite imagery and remote sensing provide explanatory variables at relatively high resolutions for modeling geospatial phenomena, yet regional summaries are often desirable for analysis and actionable insight. In this paper, we propose a novel method of inducing spatial aggregations as a component of the machine learning process, yielding regional model features whose construction is driven by model prediction performance rather than prior assumptions. Our results demonstrate that Genetic Programming is particularly well suited to this type of feature construction because it can automatically synthesize appropriate aggregations, as well as better incorporate them into predictive models compared to other regression methods we tested. In our experiments we consider a specific problem instance and real-world dataset relevant to predicting snow properties in high-mountain Asia.
Crowdsourcing Predictors of Residential Electric Energy Usage
Sep 08, 2017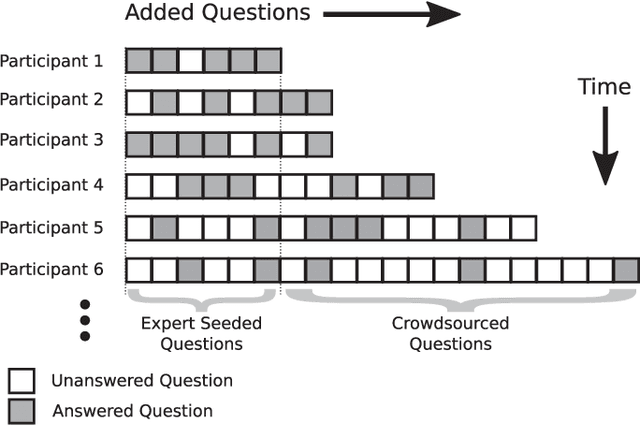

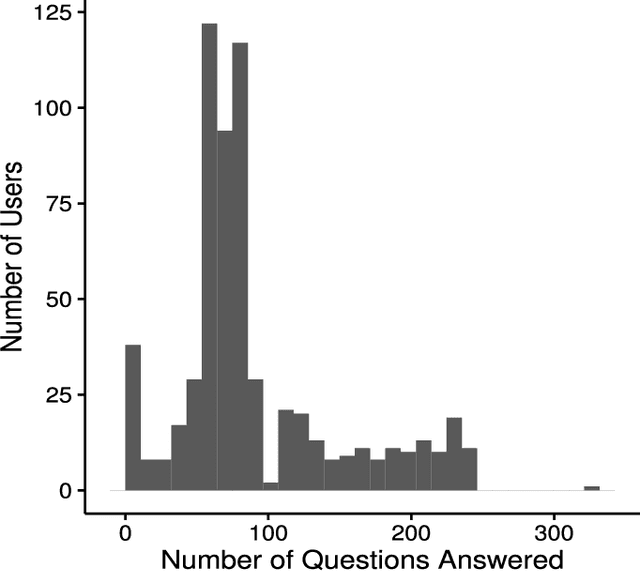
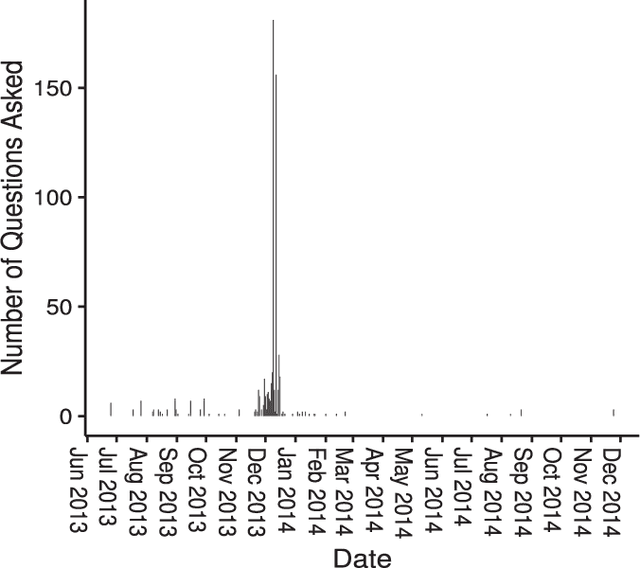
Crowdsourcing has been successfully applied in many domains including astronomy, cryptography and biology. In order to test its potential for useful application in a Smart Grid context, this paper investigates the extent to which a crowd can contribute predictive hypotheses to a model of residential electric energy consumption. In this experiment, the crowd generated hypotheses about factors that make one home different from another in terms of monthly energy usage. To implement this concept, we deployed a web-based system within which 627 residential electricity customers posed 632 questions that they thought predictive of energy usage. While this occurred, the same group provided 110,573 answers to these questions as they accumulated. Thus users both suggested the hypotheses that drive a predictive model and provided the data upon which the model is built. We used the resulting question and answer data to build a predictive model of monthly electric energy consumption, using random forest regression. Because of the sparse nature of the answer data, careful statistical work was needed to ensure that these models are valid. The results indicate that the crowd can generate useful hypotheses, despite the sparse nature of the dataset.
* 11 pages, 7 figures
A Minimal Developmental Model Can Increase Evolvability in Soft Robots
Jun 22, 2017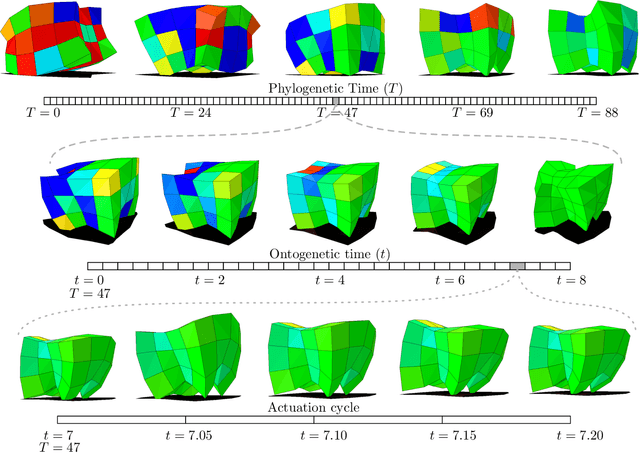
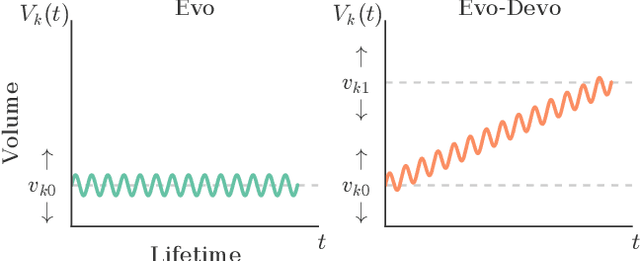
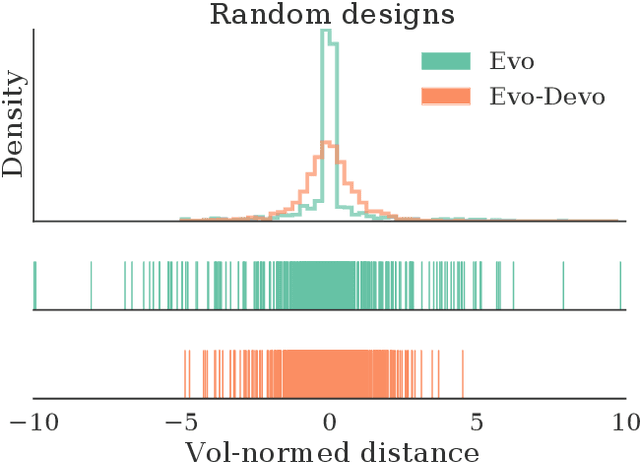
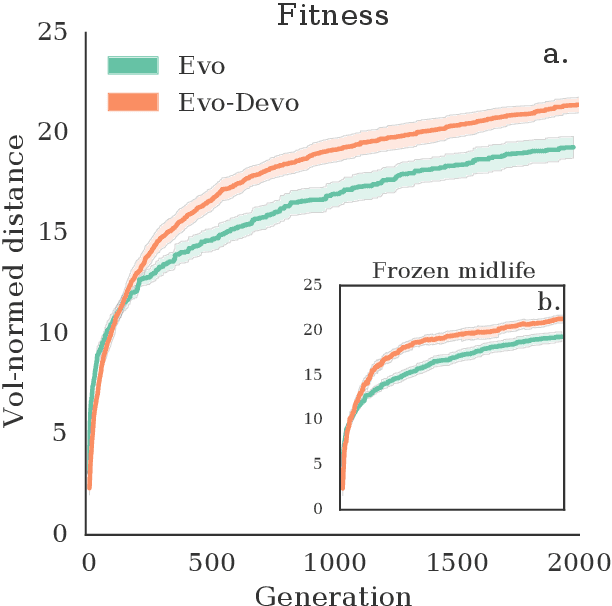
Different subsystems of organisms adapt over many time scales, such as rapid changes in the nervous system (learning), slower morphological and neurological change over the lifetime of the organism (postnatal development), and change over many generations (evolution). Much work has focused on instantiating learning or evolution in robots, but relatively little on development. Although many theories have been forwarded as to how development can aid evolution, it is difficult to isolate each such proposed mechanism. Thus, here we introduce a minimal yet embodied model of development: the body of the robot changes over its lifetime, yet growth is not influenced by the environment. We show that even this simple developmental model confers evolvability because it allows evolution to sweep over a larger range of body plans than an equivalent non-developmental system, and subsequent heterochronic mutations 'lock in' this body plan in more morphologically-static descendants. Future work will involve gradually complexifying the developmental model to determine when and how such added complexity increases evolvability.
Nonlinear functional mapping of the human brain
Sep 08, 2015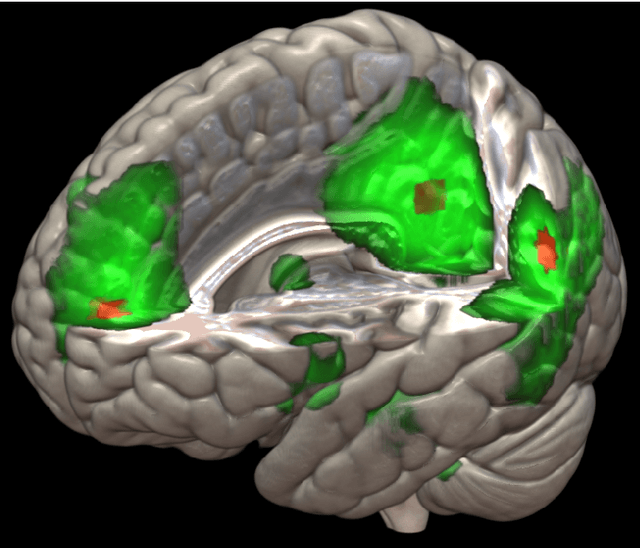
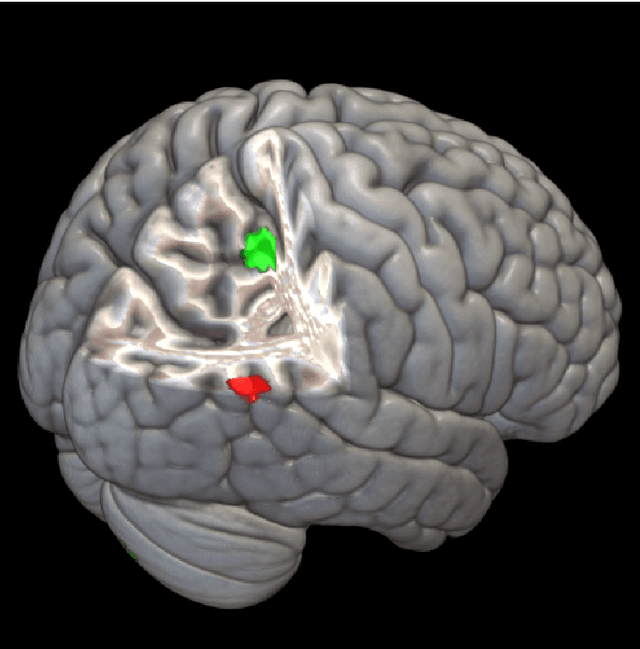
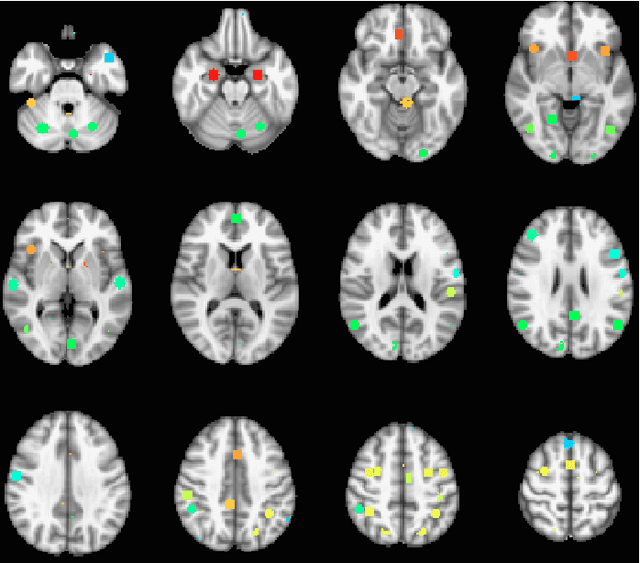
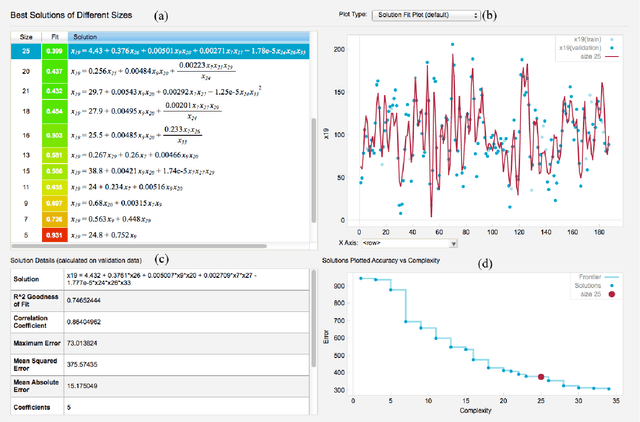
The field of neuroimaging has truly become data rich, and novel analytical methods capable of gleaning meaningful information from large stores of imaging data are in high demand. Those methods that might also be applicable on the level of individual subjects, and thus potentially useful clinically, are of special interest. In the present study, we introduce just such a method, called nonlinear functional mapping (NFM), and demonstrate its application in the analysis of resting state fMRI from a 242-subject subset of the IMAGEN project, a European study of adolescents that includes longitudinal phenotypic, behavioral, genetic, and neuroimaging data. NFM employs a computational technique inspired by biological evolution to discover and mathematically characterize interactions among ROI (regions of interest), without making linear or univariate assumptions. We show that statistics of the resulting interaction relationships comport with recent independent work, constituting a preliminary cross-validation. Furthermore, nonlinear terms are ubiquitous in the models generated by NFM, suggesting that some of the interactions characterized here are not discoverable by standard linear methods of analysis. We discuss one such nonlinear interaction in the context of a direct comparison with a procedure involving pairwise correlation, designed to be an analogous linear version of functional mapping. We find another such interaction that suggests a novel distinction in brain function between drinking and non-drinking adolescents: a tighter coupling of ROI associated with emotion, reward, and interoceptive processes such as thirst, among drinkers. Finally, we outline many improvements and extensions of the methodology to reduce computational expense, complement other analytical tools like graph-theoretic analysis, and allow for voxel level NFM to eliminate the necessity of ROI selection.