 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical laws and linguistics inform meaning in naturalistic and fictional conversation
Dec 19, 2025
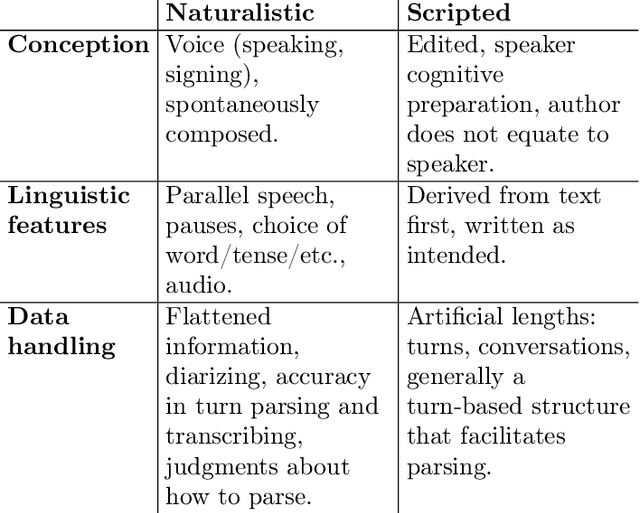
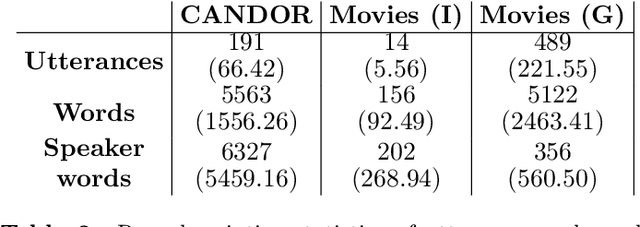
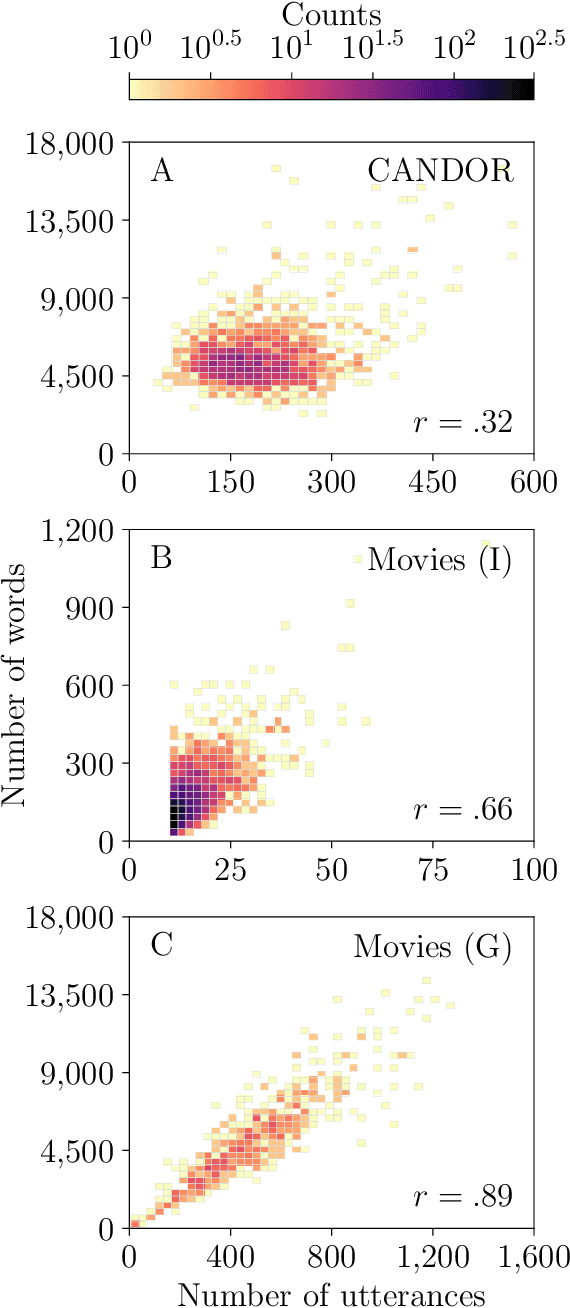
Conversation is a cornerstone of social connection and is linked to well-being outcomes. Conversations vary widely in type with some portion generating complex, dynamic stories. One approach to studying how conversations unfold in time is through statistical patterns such as Heaps' law, which holds that vocabulary size scales with document length. Little work on Heaps's law has looked at conversation and considered how language features impact scaling. We measure Heaps' law for conversations recorded in two distinct mediums: 1. Strangers brought together on video chat and 2. Fictional characters in movies. We find that scaling of vocabulary size differs by parts of speech. We discuss these findings through behavioral and linguistic frameworks.
Tokens, the oft-overlooked appetizer: Large language models, the distributional hypothesis, and meaning
Dec 14, 2024Tokenization is a necessary component within the current architecture of many language models, including the transformer-based large language models (LLMs) of Generative AI, yet its impact on the model's cognition is often overlooked. We argue that LLMs demonstrate that the Distributional Hypothesis (DM) is sufficient for reasonably human-like language performance, and that the emergence of human-meaningful linguistic units among tokens motivates linguistically-informed interventions in existing, linguistically-agnostic tokenization techniques, particularly with respect to their roles as (1) semantic primitives and as (2) vehicles for conveying salient distributional patterns from human language to the model. We explore tokenizations from a BPE tokenizer; extant model vocabularies obtained from Hugging Face and tiktoken; and the information in exemplar token vectors as they move through the layers of a RoBERTa (large) model. Besides creating sub-optimal semantic building blocks and obscuring the model's access to the necessary distributional patterns, we describe how tokenization pretraining can be a backdoor for bias and other unwanted content, which current alignment practices may not remediate. Additionally, we relay evidence that the tokenization algorithm's objective function impacts the LLM's cognition, despite being meaningfully insulated from the main system intelligence.
The Resume Paradox: Greater Language Differences, Smaller Pay Gaps
Jul 17, 2023



Over the past decade, the gender pay gap has remained steady with women earning 84 cents for every dollar earned by men on average. Many studies explain this gap through demand-side bias in the labor market represented through employers' job postings. However, few studies analyze potential bias from the worker supply-side. Here, we analyze the language in millions of US workers' resumes to investigate how differences in workers' self-representation by gender compare to differences in earnings. Across US occupations, language differences between male and female resumes correspond to 11% of the variation in gender pay gap. This suggests that females' resumes that are semantically similar to males' resumes may have greater wage parity. However, surprisingly, occupations with greater language differences between male and female resumes have lower gender pay gaps. A doubling of the language difference between female and male resumes results in an annual wage increase of $2,797 for the average female worker. This result holds with controls for gender-biases of resume text and we find that per-word bias poorly describes the variance in wage gap. The results demonstrate that textual data and self-representation are valuable factors for improving worker representations and understanding employment inequities.
A blind spot for large language models: Supradiegetic linguistic information
Jun 11, 2023



Large Language Models (LLMs) like ChatGPT reflect profound changes in the field of Artificial Intelligence, achieving a linguistic fluency that is impressively, even shockingly, human-like. The extent of their current and potential capabilities is an active area of investigation by no means limited to scientific researchers. It is common for people to frame the training data for LLMs as "text" or even "language". We examine the details of this framing using ideas from several areas, including linguistics, embodied cognition, cognitive science, mathematics, and history. We propose that considering what it is like to be an LLM like ChatGPT, as Nagel might have put it, can help us gain insight into its capabilities in general, and in particular, that its exposure to linguistic training data can be productively reframed as exposure to the diegetic information encoded in language, and its deficits can be reframed as ignorance of extradiegetic information, including supradiegetic linguistic information. Supradiegetic linguistic information consists of those arbitrary aspects of the physical form of language that are not derivable from the one-dimensional relations of context -- frequency, adjacency, proximity, co-occurrence -- that LLMs like ChatGPT have access to. Roughly speaking, the diegetic portion of a word can be thought of as its function, its meaning, as the information in a theoretical vector in a word embedding, while the supradiegetic portion of the word can be thought of as its form, like the shapes of its letters or the sounds of its syllables. We use these concepts to investigate why LLMs like ChatGPT have trouble handling palindromes, the visual characteristics of symbols, translating Sumerian cuneiform, and continuing integer sequences.
An assessment of measuring local levels of homelessness through proxy social media signals
May 15, 2023Recent studies suggest social media activity can function as a proxy for measures of state-level public health, detectable through natural language processing. We present results of our efforts to apply this approach to estimate homelessness at the state level throughout the US during the period 2010-2019 and 2022 using a dataset of roughly 1 million geotagged tweets containing the substring ``homeless.'' Correlations between homelessness-related tweet counts and ranked per capita homelessness volume, but not general-population densities, suggest a relationship between the likelihood of Twitter users to personally encounter or observe homelessness in their everyday lives and their likelihood to communicate about it online. An increase to the log-odds of ``homeless'' appearing in an English-language tweet, as well as an acceleration in the increase in average tweet sentiment, suggest that tweets about homelessness are also affected by trends at the nation-scale. Additionally, changes to the lexical content of tweets over time suggest that reversals to the polarity of national or state-level trends may be detectable through an increase in political or service-sector language over the semantics of charity or direct appeals. An analysis of user account type also revealed changes to Twitter-use patterns by accounts authored by individuals versus entities that may provide an additional signal to confirm changes to homelessness density in a given jurisdiction. While a computational approach to social media analysis may provide a low-cost, real-time dataset rich with information about nationwide and localized impacts of homelessness and homelessness policy, we find that practical issues abound, limiting the potential of social media as a proxy to complement other measures of homelessness.
Curating corpora with classifiers: A case study of clean energy sentiment online
May 10, 2023Well curated, large-scale corpora of social media posts containing broad public opinion offer an alternative data source to complement traditional surveys. While surveys are effective at collecting representative samples and are capable of achieving high accuracy, they can be both expensive to run and lag public opinion by days or weeks. Both of these drawbacks could be overcome with a real-time, high volume data stream and fast analysis pipeline. A central challenge in orchestrating such a data pipeline is devising an effective method for rapidly selecting the best corpus of relevant documents for analysis. Querying with keywords alone often includes irrelevant documents that are not easily disambiguated with bag-of-words natural language processing methods. Here, we explore methods of corpus curation to filter irrelevant tweets using pre-trained transformer-based models, fine-tuned for our binary classification task on hand-labeled tweets. We are able to achieve F1 scores of up to 0.95. The low cost and high performance of fine-tuning such a model suggests that our approach could be of broad benefit as a pre-processing step for social media datasets with uncertain corpus boundaries.
Characterizing narrative time in books through fluctuations in power and danger arcs
Aug 24, 2022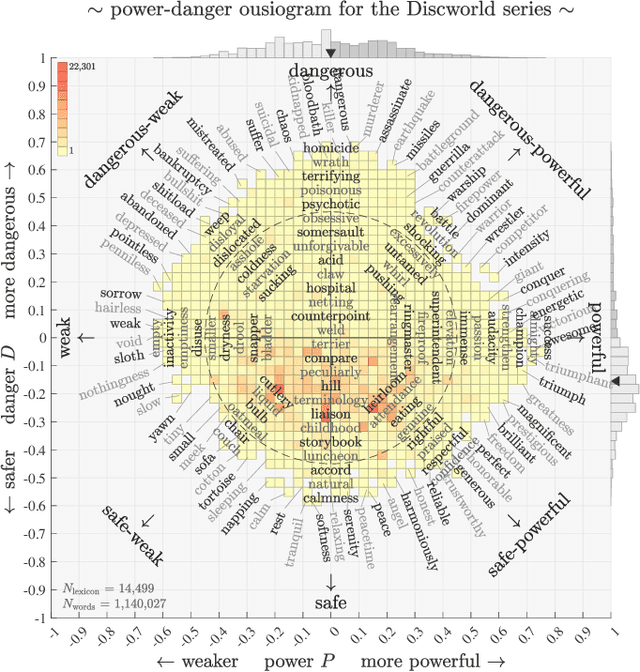
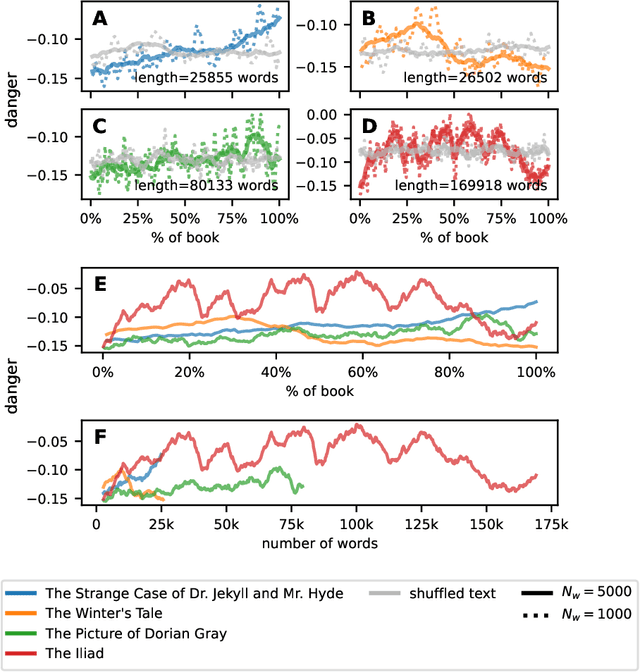
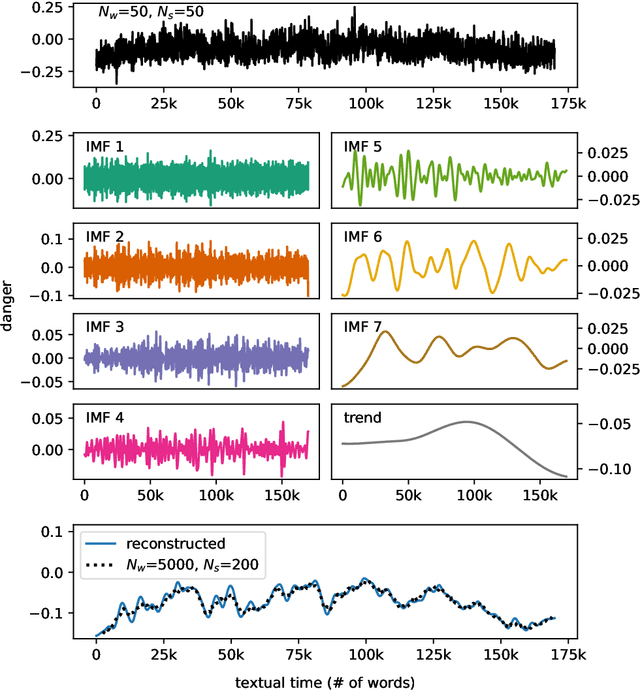
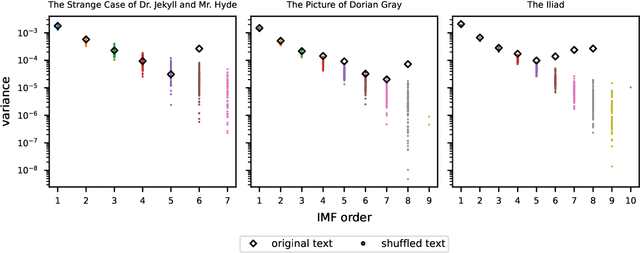
While recent studies have focused on quantifying word usage to find the overall shapes of narrative emotional arcs, certain features of narratives within narratives remain to be explored. Here, we characterize the narrative time scale of sub-narratives by finding the length of text at which fluctuations in word usage begin to be relevant. We represent more than 30,000 Project Gutenberg books as time series using ousiometrics, a power-danger framework for essential meaning, itself a reinterpretation of the valence-arousal-dominance framework derived from semantic differentials. We decompose each book's power and danger time series using empirical mode decomposition into a sum of constituent oscillatory modes and a non-oscillatory trend. By comparing the decomposition of the original power and danger time series with those derived from shuffled text, we find that shorter books exhibit only a general trend, while longer books have fluctuations in addition to the general trend, similar to how subplots have arcs within an overall narrative arc. These fluctuations typically have a period of a few thousand words regardless of the book length or library classification code, but vary depending on the content and structure of the book. Our method provides a data-driven denoising approach that works for text of various lengths, in contrast to the more traditional approach of using large window sizes that may inadvertently smooth out relevant information, especially for shorter texts.
Sentiment and structure in word co-occurrence networks on Twitter
Oct 01, 2021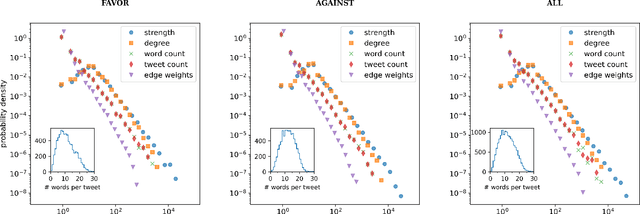
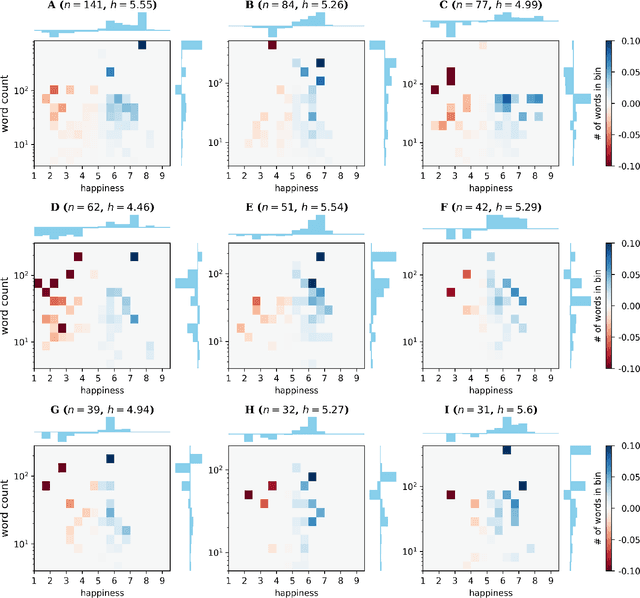
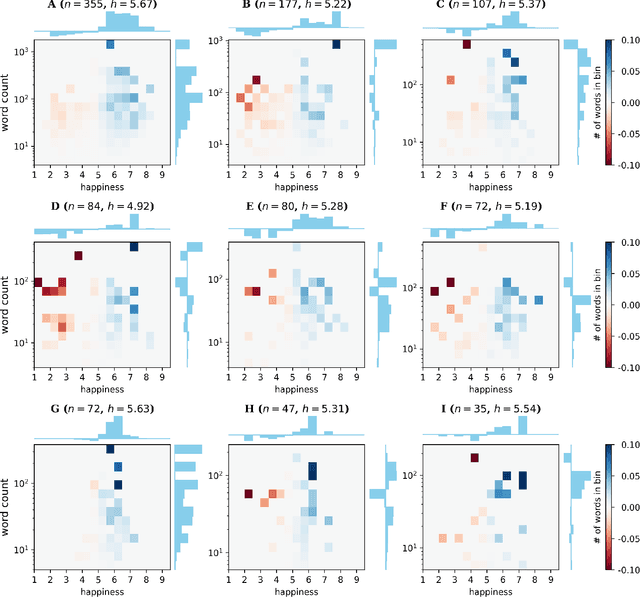
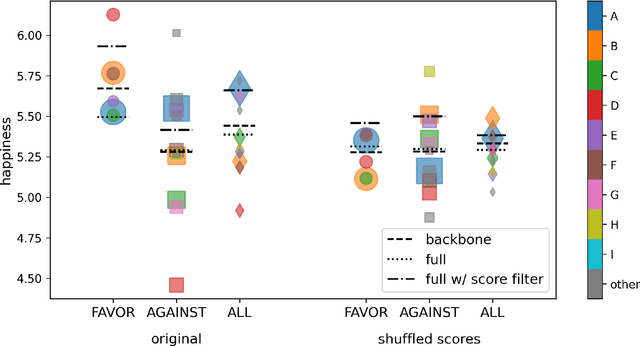
We explore the relationship between context and happiness scores in political tweets using word co-occurrence networks, where nodes in the network are the words, and the weight of an edge is the number of tweets in the corpus for which the two connected words co-occur. In particular, we consider tweets with hashtags #imwithher and #crookedhillary, both relating to Hillary Clinton's presidential bid in 2016. We then analyze the network properties in conjunction with the word scores by comparing with null models to separate the effects of the network structure and the score distribution. Neutral words are found to be dominant and most words, regardless of polarity, tend to co-occur with neutral words. We do not observe any score homophily among positive and negative words. However, when we perform network backboning, community detection results in word groupings with meaningful narratives, and the happiness scores of the words in each group correspond to its respective theme. Thus, although we observe no clear relationship between happiness scores and co-occurrence at the node or edge level, a community-centric approach can isolate themes of competing sentiments in a corpus.
Augmenting semantic lexicons using word embeddings and transfer learning
Sep 18, 2021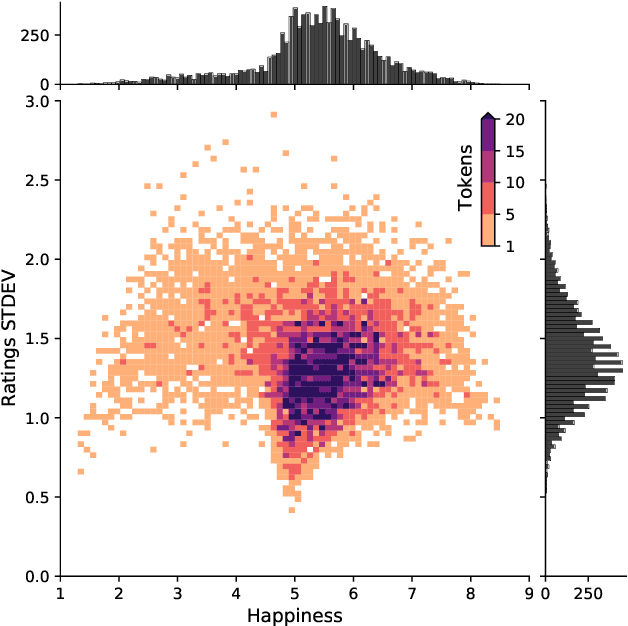
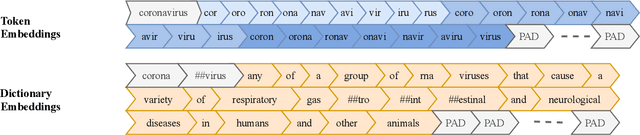
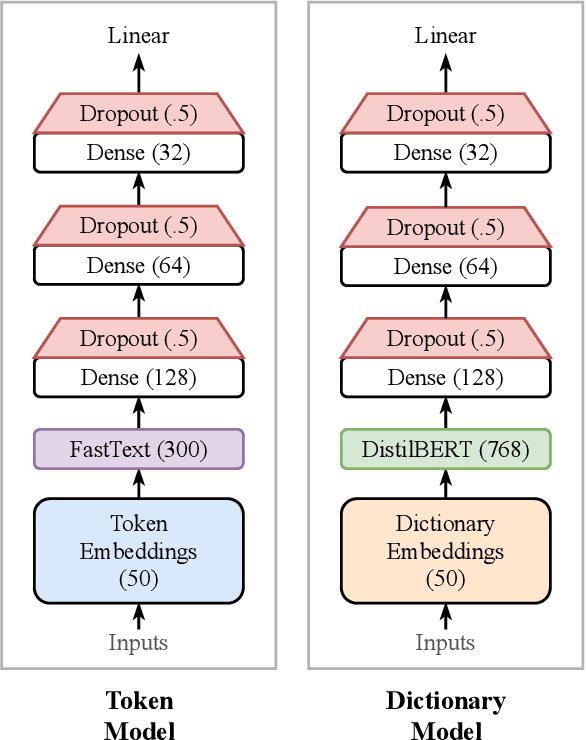
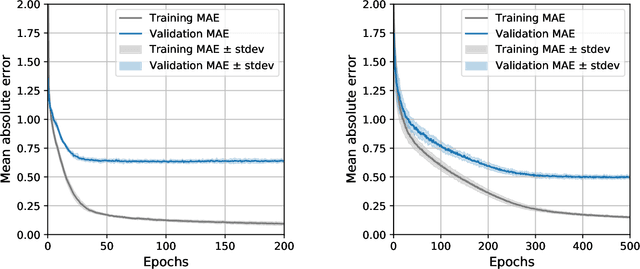
Sentiment-aware intelligent systems are essential to a wide array of applications including marketing, political campaigns, recommender systems, behavioral economics, social psychology, and national security. These sentiment-aware intelligent systems are driven by language models which broadly fall into two paradigms: 1. Lexicon-based and 2. Contextual. Although recent contextual models are increasingly dominant, we still see demand for lexicon-based models because of their interpretability and ease of use. For example, lexicon-based models allow researchers to readily determine which words and phrases contribute most to a change in measured sentiment. A challenge for any lexicon-based approach is that the lexicon needs to be routinely expanded with new words and expressions. Crowdsourcing annotations for semantic dictionaries may be an expensive and time-consuming task. Here, we propose two models for predicting sentiment scores to augment semantic lexicons at a relatively low cost using word embeddings and transfer learning. Our first model establishes a baseline employing a simple and shallow neural network initialized with pre-trained word embeddings using a non-contextual approach. Our second model improves upon our baseline, featuring a deep Transformer-based network that brings to bear word definitions to estimate their lexical polarity. Our evaluation shows that both models are able to score new words with a similar accuracy to reviewers from Amazon Mechanical Turk, but at a fraction of the cost.
Sirius: A Mutual Information Tool for Exploratory Visualization of Mixed Data
Jun 09, 2021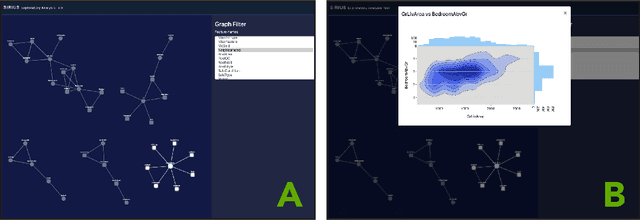
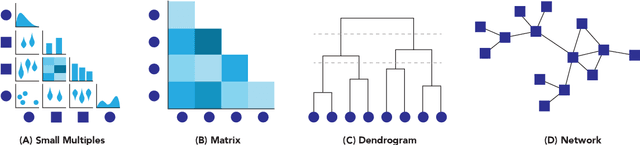
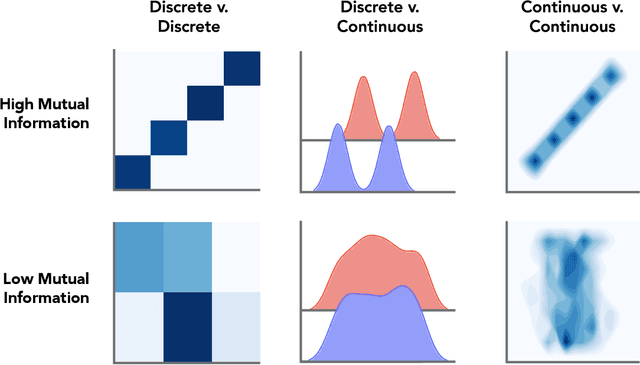

Data scientists across disciplines are increasingly in need of exploratory analysis tools for data sets with a high volume of features. We expand upon graph mining approaches for exploratory analysis of high-dimensional data to introduce Sirius, a visualization package for researchers to explore feature relationships among mixed data types using mutual information and network backbone sparsification. Visualizations of feature relationships aid data scientists in finding meaningful dependence among features, which can engender further analysis for feature selection, feature extraction, projection, identification of proxy variables, or insight into temporal variation at the macro scale. Graph mining approaches for feature analysis exist, such as association networks of binary features, or correlation networks of quantitative features, but mixed data types present a unique challenge for developing comprehensive feature networks for exploratory analysis. Using an information theoretic approach, Sirius supports heterogeneous data sets consisting of binary, continuous quantitative, and discrete categorical data types, and provides a user interface exploring feature pairs with high mutual information scores. We leverage a backbone sparsification approach from network theory as a dimensionality reduction technique, which probabilistically trims edges according to the local network context. Sirius is an open source Python package and Django web application for exploratory visualization, which can be deployed in data analysis pipelines. The Sirius codebase and exemplary data sets can be found at: https://github.com/compstorylab/sirius