 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Resume Paradox: Greater Language Differences, Smaller Pay Gaps
Jul 17, 2023



Over the past decade, the gender pay gap has remained steady with women earning 84 cents for every dollar earned by men on average. Many studies explain this gap through demand-side bias in the labor market represented through employers' job postings. However, few studies analyze potential bias from the worker supply-side. Here, we analyze the language in millions of US workers' resumes to investigate how differences in workers' self-representation by gender compare to differences in earnings. Across US occupations, language differences between male and female resumes correspond to 11% of the variation in gender pay gap. This suggests that females' resumes that are semantically similar to males' resumes may have greater wage parity. However, surprisingly, occupations with greater language differences between male and female resumes have lower gender pay gaps. A doubling of the language difference between female and male resumes results in an annual wage increase of $2,797 for the average female worker. This result holds with controls for gender-biases of resume text and we find that per-word bias poorly describes the variance in wage gap. The results demonstrate that textual data and self-representation are valuable factors for improving worker representations and understanding employment inequities.
Quantifying language changes surrounding mental health on Twitter
Jun 02, 2021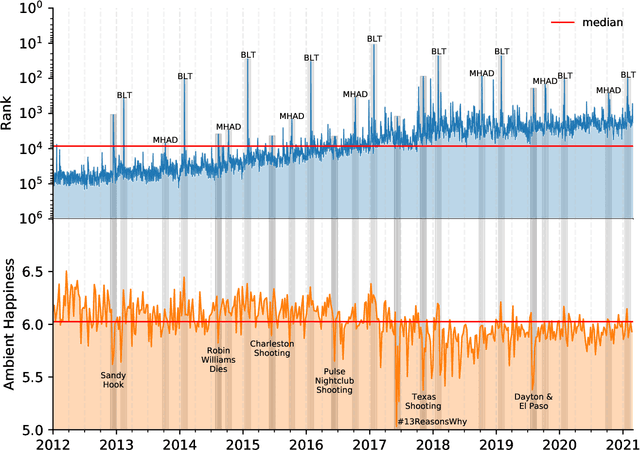
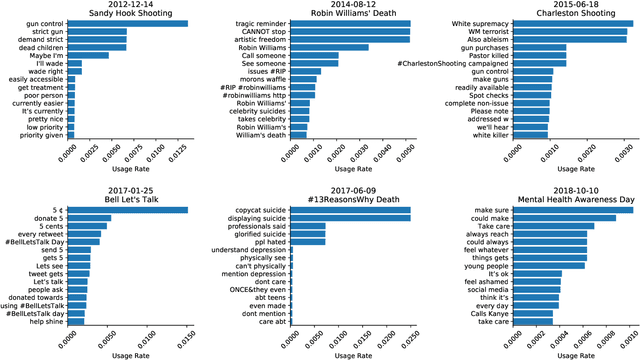
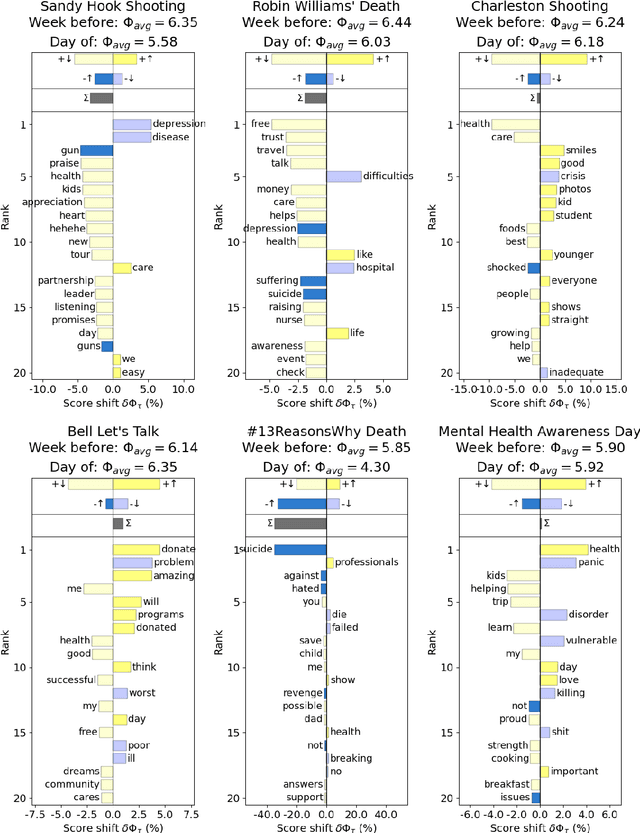
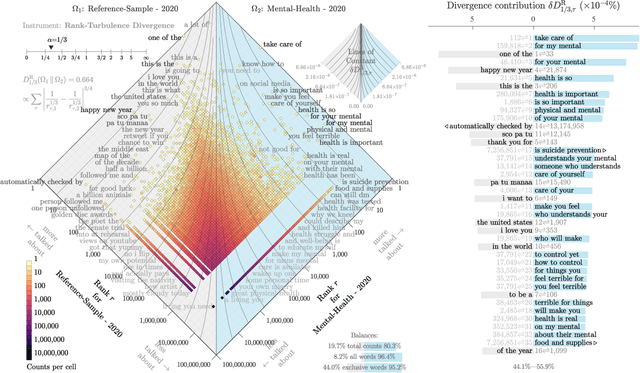
Mental health challenges are thought to afflict around 10% of the global population each year, with many going untreated due to stigma and limited access to services. Here, we explore trends in words and phrases related to mental health through a collection of 1- , 2-, and 3-grams parsed from a data stream of roughly 10% of all English tweets since 2012. We examine temporal dynamics of mental health language, finding that the popularity of the phrase 'mental health' increased by nearly two orders of magnitude between 2012 and 2018. We observe that mentions of 'mental health' spike annually and reliably due to mental health awareness campaigns, as well as unpredictably in response to mass shootings, celebrities dying by suicide, and popular fictional stories portraying suicide. We find that the level of positivity of messages containing 'mental health', while stable through the growth period, has declined recently. Finally, we use the ratio of original tweets to retweets to quantify the fraction of appearances of mental health language due to social amplification. Since 2015, mentions of mental health have become increasingly due to retweets, suggesting that stigma associated with discussion of mental health on Twitter has diminished with time.
The incel lexicon: Deciphering the emergent cryptolect of a global misogynistic community
May 25, 2021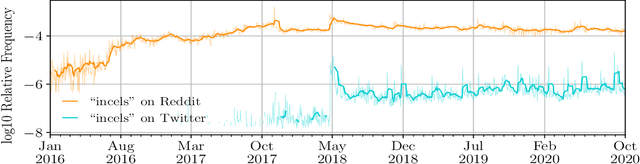
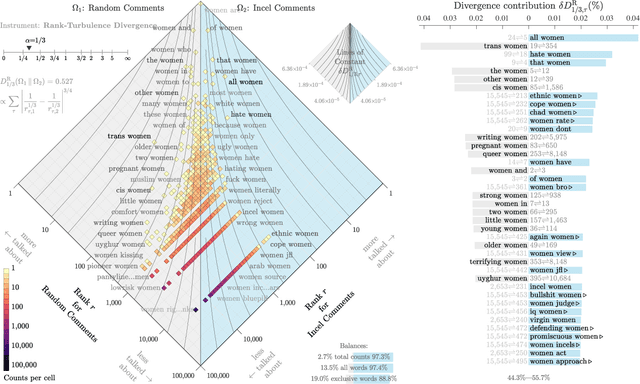
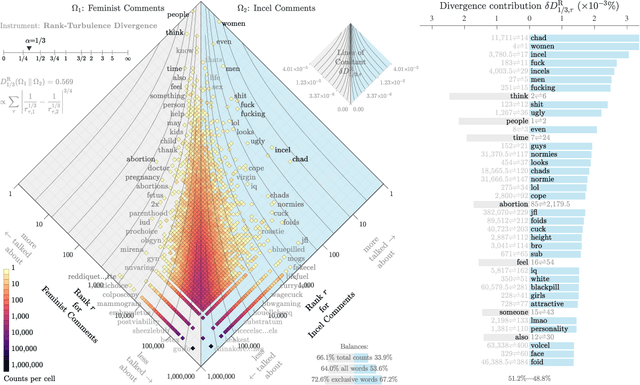
Evolving out of a gender-neutral framing of an involuntary celibate identity, the concept of `incels' has come to refer to an online community of men who bear antipathy towards themselves, women, and society-at-large for their perceived inability to find and maintain sexual relationships. By exploring incel language use on Reddit, a global online message board, we contextualize the incel community's online expressions of misogyny and real-world acts of violence perpetrated against women. After assembling around three million comments from incel-themed Reddit channels, we analyze the temporal dynamics of a data driven rank ordering of the glossary of phrases belonging to an emergent incel lexicon. Our study reveals the generation and normalization of an extensive coded misogynist vocabulary in service of the group's identity.
Interpretable bias mitigation for textual data: Reducing gender bias in patient notes while maintaining classification performance
Mar 10, 2021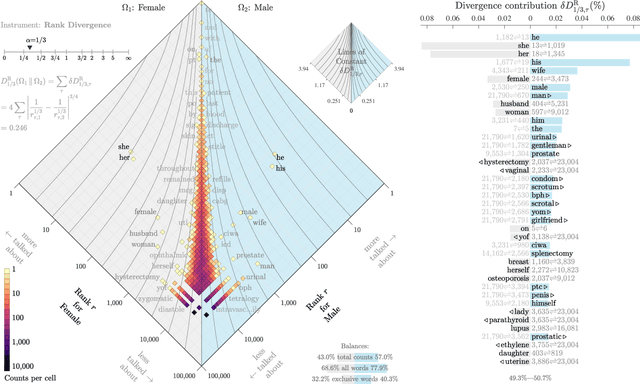
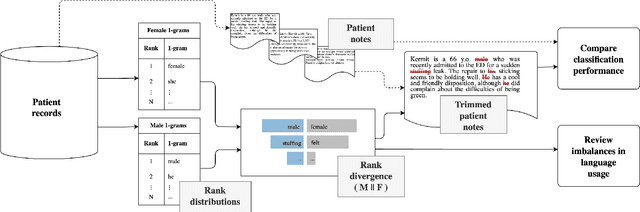
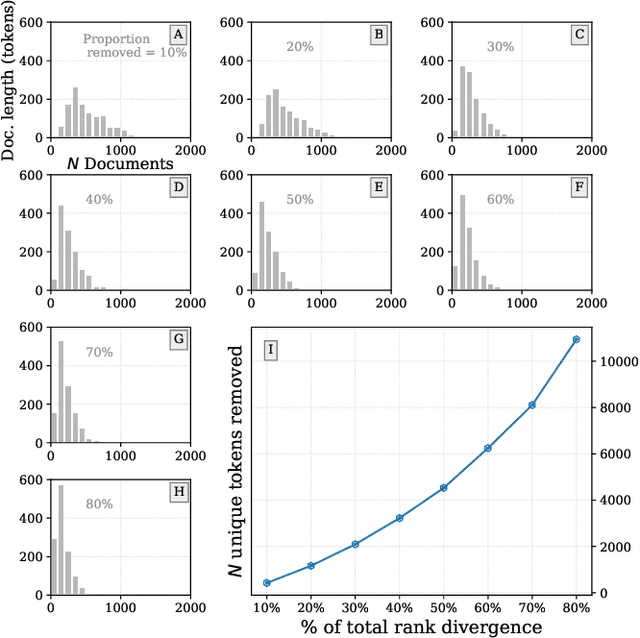
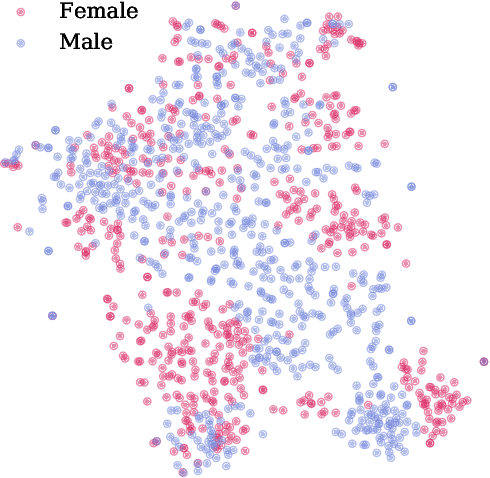
Medical systems in general, and patient treatment decisions and outcomes in particular, are affected by bias based on gender and other demographic elements. As language models are increasingly applied to medicine, there is a growing interest in building algorithmic fairness into processes impacting patient care. Much of the work addressing this question has focused on biases encoded in language models -- statistical estimates of the relationships between concepts derived from distant reading of corpora. Building on this work, we investigate how word choices made by healthcare practitioners and language models interact with regards to bias. We identify and remove gendered language from two clinical-note datasets and describe a new debiasing procedure using BERT-based gender classifiers. We show minimal degradation in health condition classification tasks for low- to medium-levels of bias removal via data augmentation. Finally, we compare the bias semantically encoded in the language models with the bias empirically observed in health records. This work outlines an interpretable approach for using data augmentation to identify and reduce the potential for bias in natural language processing pipelines.
Storywrangler: A massive exploratorium for sociolinguistic, cultural, socioeconomic, and political timelines using Twitter
Jul 25, 2020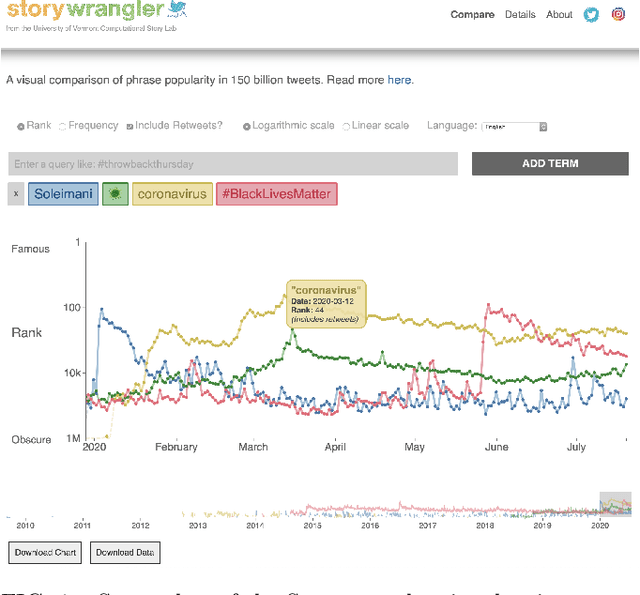
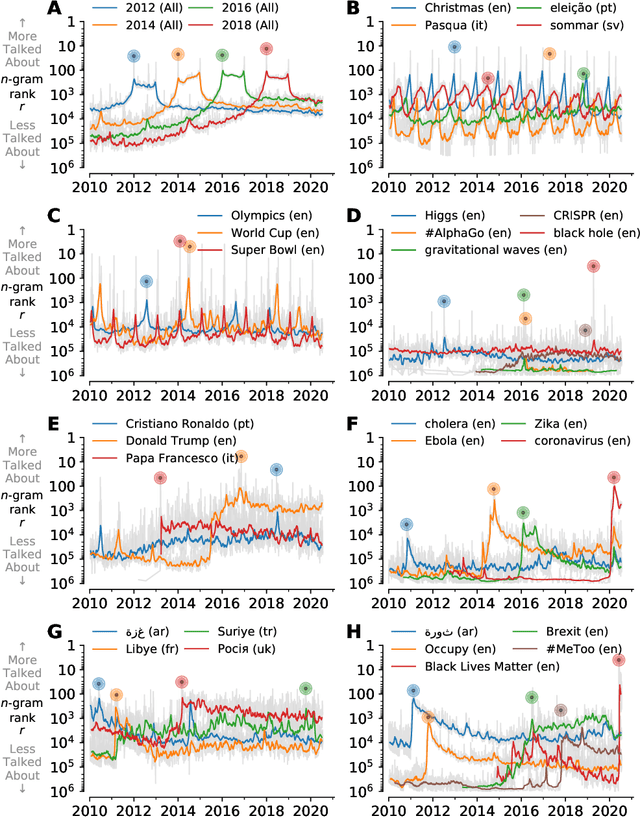
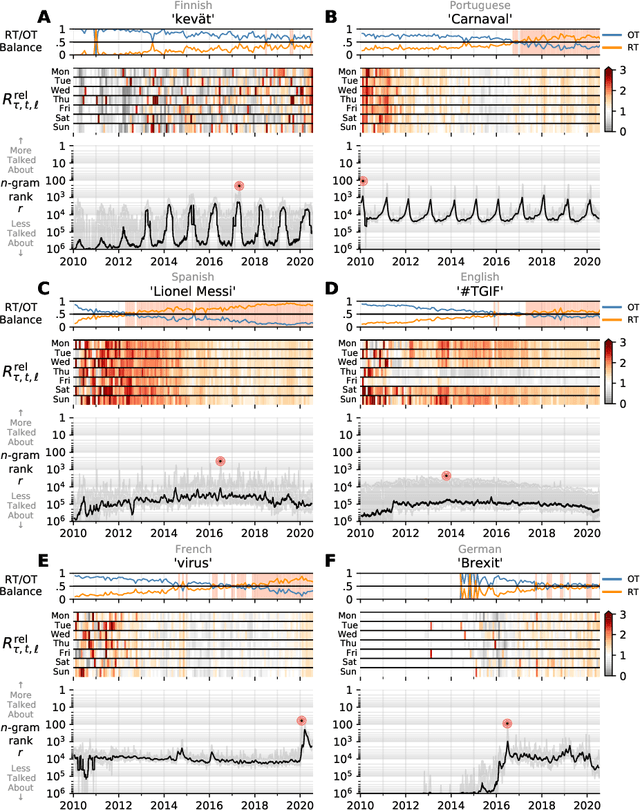
In real-time, Twitter strongly imprints world events, popular culture, and the day-to-day; Twitter records an ever growing compendium of language use and change; and Twitter has been shown to enable certain kinds of prediction. Vitally, and absent from many standard corpora such as books and news archives, Twitter also encodes popularity and spreading through retweets. Here, we describe Storywrangler, an ongoing, day-scale curation of over 100 billion tweets containing around 1 trillion 1-grams from 2008 to 2020. For each day, we break tweets into 1-, 2-, and 3-grams across 150+ languages, record usage frequencies, and generate Zipf distributions. We make the data set available through an interactive time series viewer, and as downloadable time series and daily distributions. We showcase a few examples of the many possible avenues of study we aim to enable including how social amplification can be visualized through 'contagiograms'.
The growing echo chamber of social media: Measuring temporal and social contagion dynamics for over 150 languages on Twitter for 2009--2020
Mar 15, 2020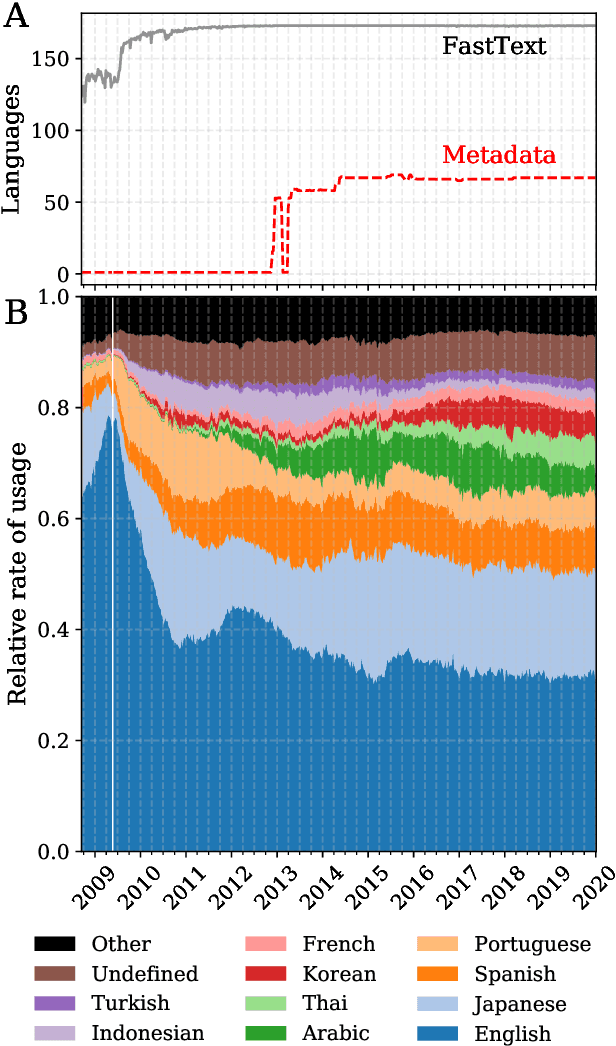
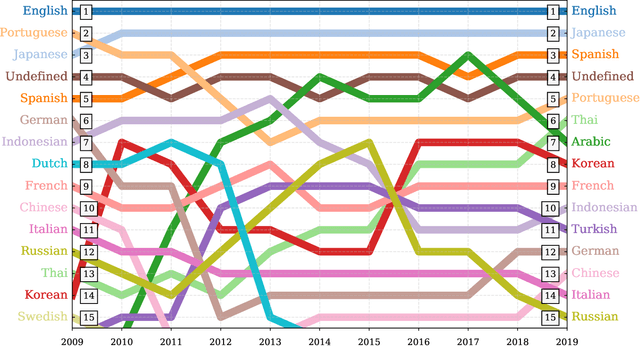
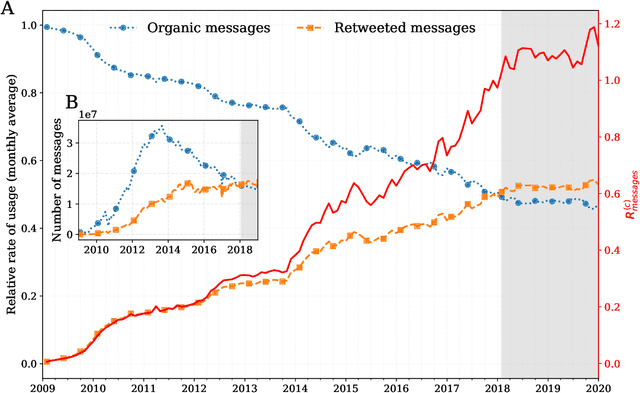
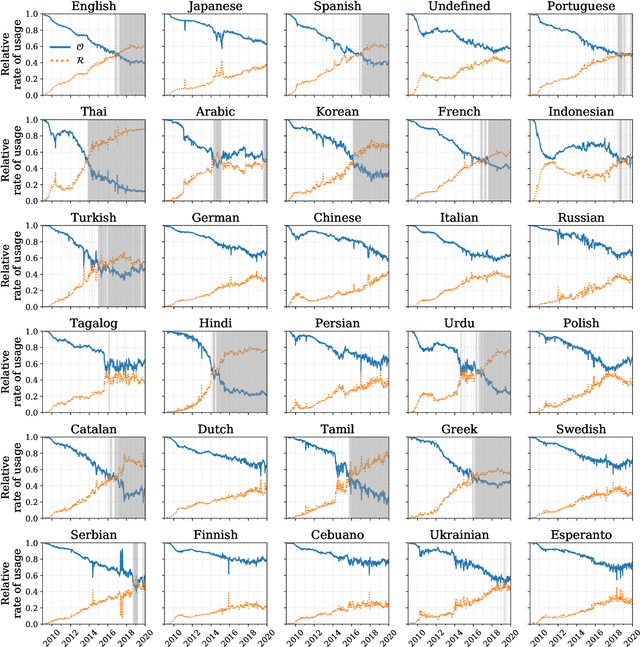
Working from a dataset of 118 billion messages running from the start of 2009 to the end of 2019, we identify and explore the relative daily use of over 150 languages on Twitter. We find that eight languages comprise 80% of all tweets, with English, Japanese, Spanish, and Portuguese being the most dominant. To quantify each language's level of being a Twitter `echo chamber' over time, we compute the `contagion ratio': the balance of retweets to organic messages. We find that for the most common languages on Twitter there is a growing tendency, though not universal, to retweet rather than share new content. By the end of 2019, the contagion ratios for half of the top 30 languages, including English and Spanish, had reached above 1---the naive contagion threshold. In 2019, the top 5 languages with the highest average daily ratios were, in order, Thai (7.3), Hindi, Tamil, Urdu, and Catalan, while the bottom 5 were Russian, Swedish, Esperanto, Cebuano, and Finnish (0.26). Further, we show that over time, the contagion ratios for most common languages are growing more strongly than those of rare languages.