 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn assessment of measuring local levels of homelessness through proxy social media signals
May 15, 2023Recent studies suggest social media activity can function as a proxy for measures of state-level public health, detectable through natural language processing. We present results of our efforts to apply this approach to estimate homelessness at the state level throughout the US during the period 2010-2019 and 2022 using a dataset of roughly 1 million geotagged tweets containing the substring ``homeless.'' Correlations between homelessness-related tweet counts and ranked per capita homelessness volume, but not general-population densities, suggest a relationship between the likelihood of Twitter users to personally encounter or observe homelessness in their everyday lives and their likelihood to communicate about it online. An increase to the log-odds of ``homeless'' appearing in an English-language tweet, as well as an acceleration in the increase in average tweet sentiment, suggest that tweets about homelessness are also affected by trends at the nation-scale. Additionally, changes to the lexical content of tweets over time suggest that reversals to the polarity of national or state-level trends may be detectable through an increase in political or service-sector language over the semantics of charity or direct appeals. An analysis of user account type also revealed changes to Twitter-use patterns by accounts authored by individuals versus entities that may provide an additional signal to confirm changes to homelessness density in a given jurisdiction. While a computational approach to social media analysis may provide a low-cost, real-time dataset rich with information about nationwide and localized impacts of homelessness and homelessness policy, we find that practical issues abound, limiting the potential of social media as a proxy to complement other measures of homelessness.
Curating corpora with classifiers: A case study of clean energy sentiment online
May 10, 2023Well curated, large-scale corpora of social media posts containing broad public opinion offer an alternative data source to complement traditional surveys. While surveys are effective at collecting representative samples and are capable of achieving high accuracy, they can be both expensive to run and lag public opinion by days or weeks. Both of these drawbacks could be overcome with a real-time, high volume data stream and fast analysis pipeline. A central challenge in orchestrating such a data pipeline is devising an effective method for rapidly selecting the best corpus of relevant documents for analysis. Querying with keywords alone often includes irrelevant documents that are not easily disambiguated with bag-of-words natural language processing methods. Here, we explore methods of corpus curation to filter irrelevant tweets using pre-trained transformer-based models, fine-tuned for our binary classification task on hand-labeled tweets. We are able to achieve F1 scores of up to 0.95. The low cost and high performance of fine-tuning such a model suggests that our approach could be of broad benefit as a pre-processing step for social media datasets with uncertain corpus boundaries.
Sentiment and structure in word co-occurrence networks on Twitter
Oct 01, 2021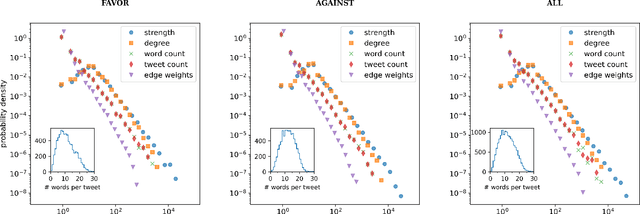
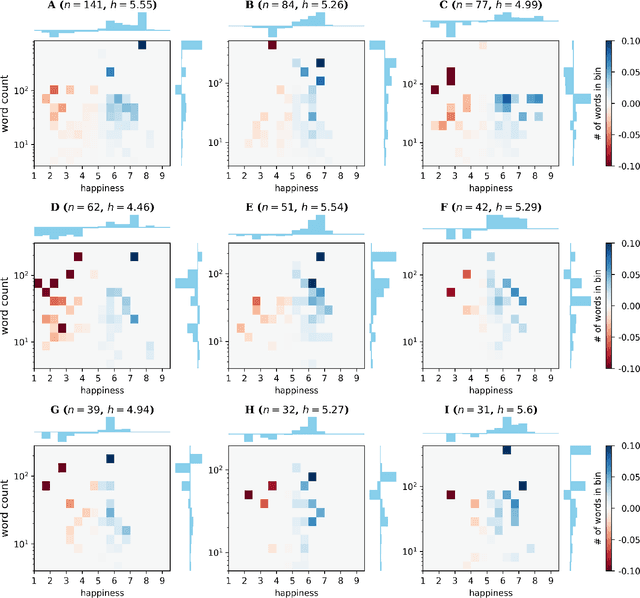
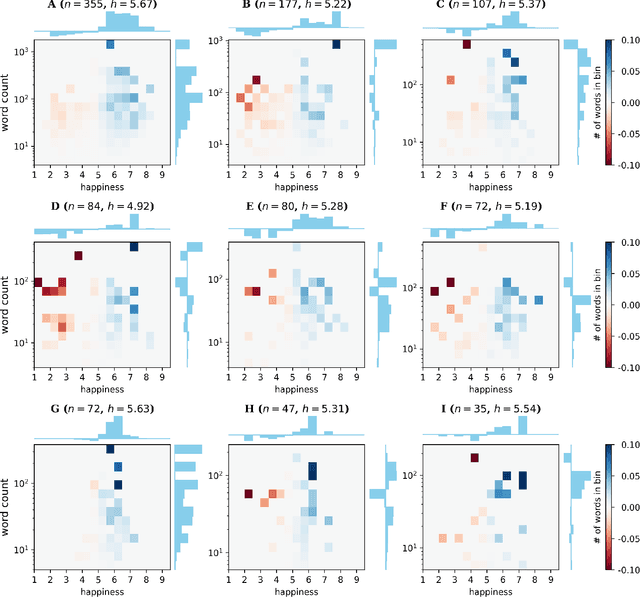
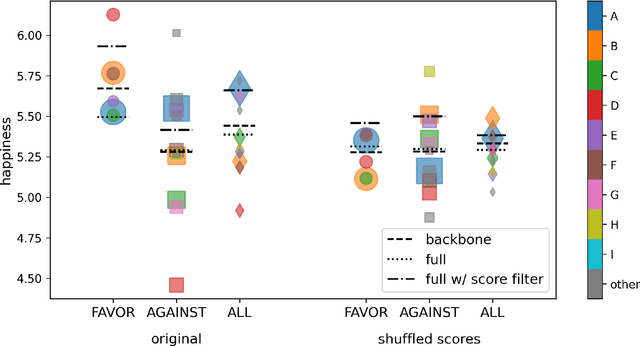
We explore the relationship between context and happiness scores in political tweets using word co-occurrence networks, where nodes in the network are the words, and the weight of an edge is the number of tweets in the corpus for which the two connected words co-occur. In particular, we consider tweets with hashtags #imwithher and #crookedhillary, both relating to Hillary Clinton's presidential bid in 2016. We then analyze the network properties in conjunction with the word scores by comparing with null models to separate the effects of the network structure and the score distribution. Neutral words are found to be dominant and most words, regardless of polarity, tend to co-occur with neutral words. We do not observe any score homophily among positive and negative words. However, when we perform network backboning, community detection results in word groupings with meaningful narratives, and the happiness scores of the words in each group correspond to its respective theme. Thus, although we observe no clear relationship between happiness scores and co-occurrence at the node or edge level, a community-centric approach can isolate themes of competing sentiments in a corpus.
Augmenting semantic lexicons using word embeddings and transfer learning
Sep 18, 2021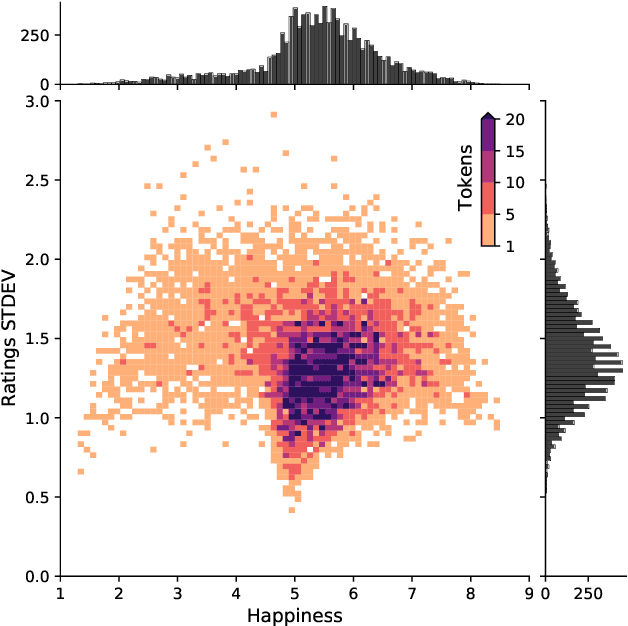
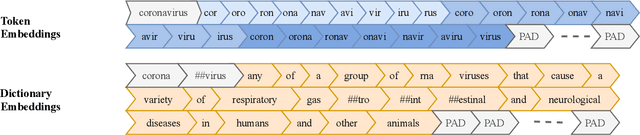
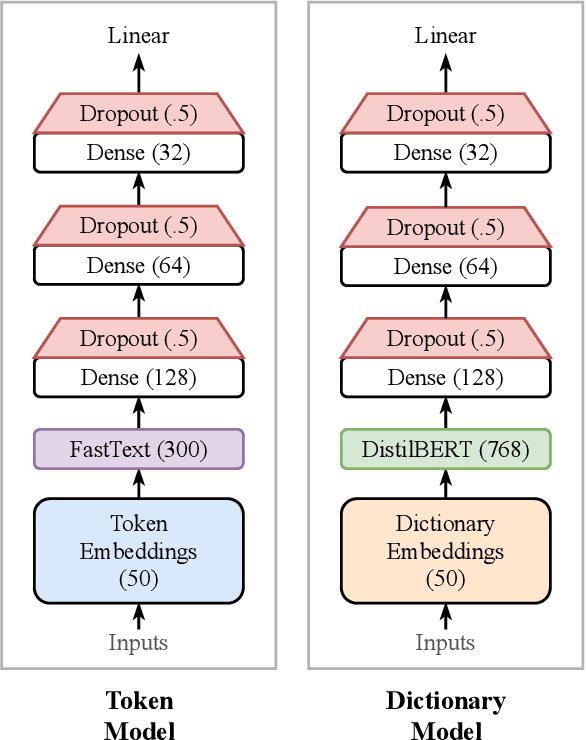
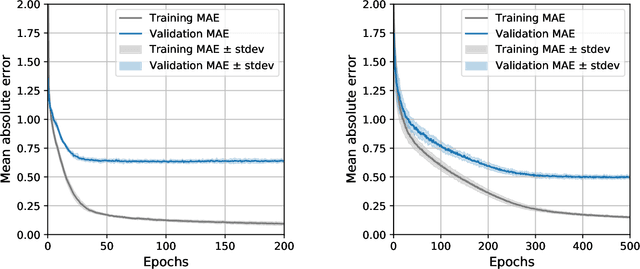
Sentiment-aware intelligent systems are essential to a wide array of applications including marketing, political campaigns, recommender systems, behavioral economics, social psychology, and national security. These sentiment-aware intelligent systems are driven by language models which broadly fall into two paradigms: 1. Lexicon-based and 2. Contextual. Although recent contextual models are increasingly dominant, we still see demand for lexicon-based models because of their interpretability and ease of use. For example, lexicon-based models allow researchers to readily determine which words and phrases contribute most to a change in measured sentiment. A challenge for any lexicon-based approach is that the lexicon needs to be routinely expanded with new words and expressions. Crowdsourcing annotations for semantic dictionaries may be an expensive and time-consuming task. Here, we propose two models for predicting sentiment scores to augment semantic lexicons at a relatively low cost using word embeddings and transfer learning. Our first model establishes a baseline employing a simple and shallow neural network initialized with pre-trained word embeddings using a non-contextual approach. Our second model improves upon our baseline, featuring a deep Transformer-based network that brings to bear word definitions to estimate their lexical polarity. Our evaluation shows that both models are able to score new words with a similar accuracy to reviewers from Amazon Mechanical Turk, but at a fraction of the cost.
Quantifying language changes surrounding mental health on Twitter
Jun 02, 2021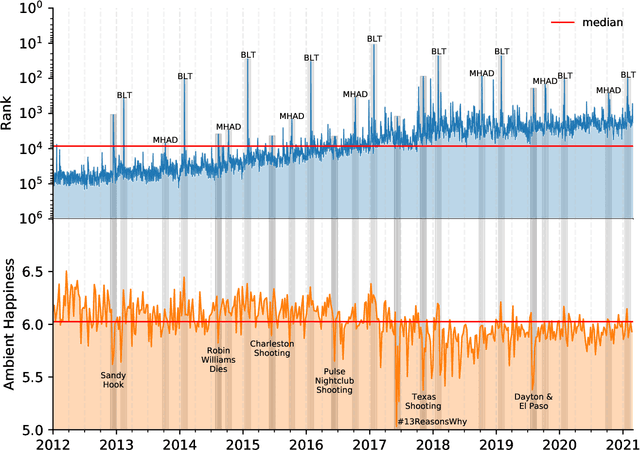
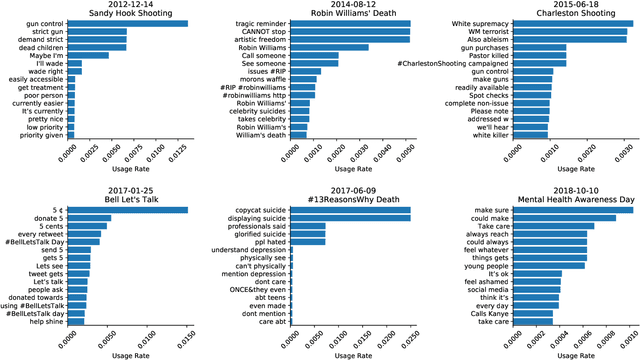
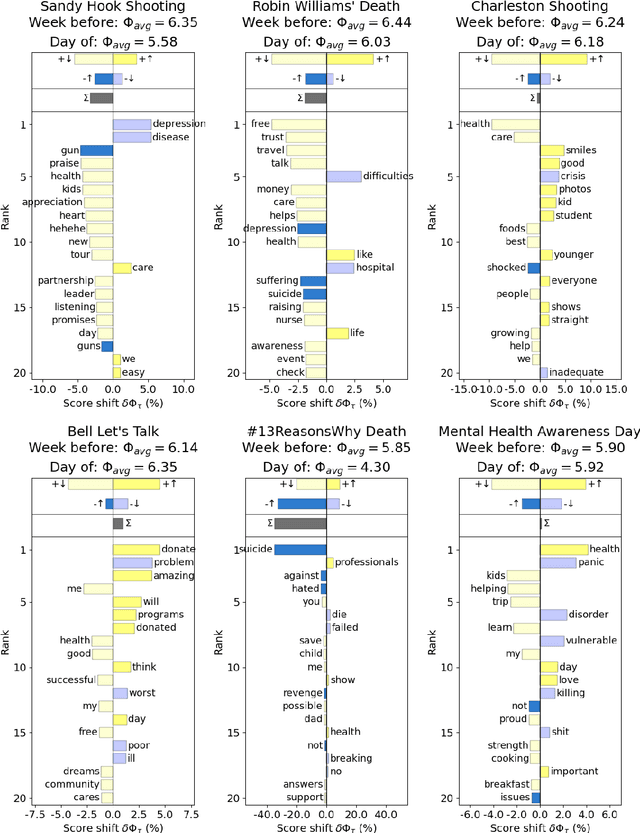
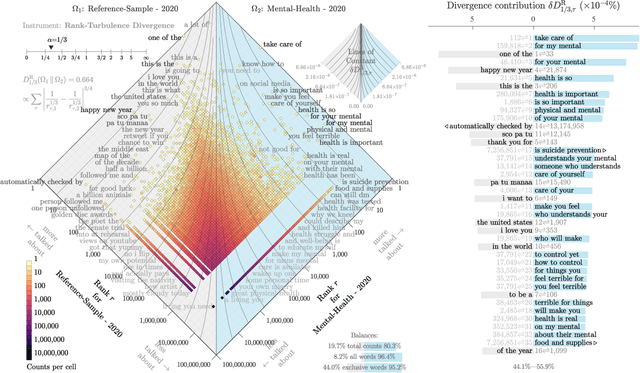
Mental health challenges are thought to afflict around 10% of the global population each year, with many going untreated due to stigma and limited access to services. Here, we explore trends in words and phrases related to mental health through a collection of 1- , 2-, and 3-grams parsed from a data stream of roughly 10% of all English tweets since 2012. We examine temporal dynamics of mental health language, finding that the popularity of the phrase 'mental health' increased by nearly two orders of magnitude between 2012 and 2018. We observe that mentions of 'mental health' spike annually and reliably due to mental health awareness campaigns, as well as unpredictably in response to mass shootings, celebrities dying by suicide, and popular fictional stories portraying suicide. We find that the level of positivity of messages containing 'mental health', while stable through the growth period, has declined recently. Finally, we use the ratio of original tweets to retweets to quantify the fraction of appearances of mental health language due to social amplification. Since 2015, mentions of mental health have become increasingly due to retweets, suggesting that stigma associated with discussion of mental health on Twitter has diminished with time.
Storywrangler: A massive exploratorium for sociolinguistic, cultural, socioeconomic, and political timelines using Twitter
Jul 25, 2020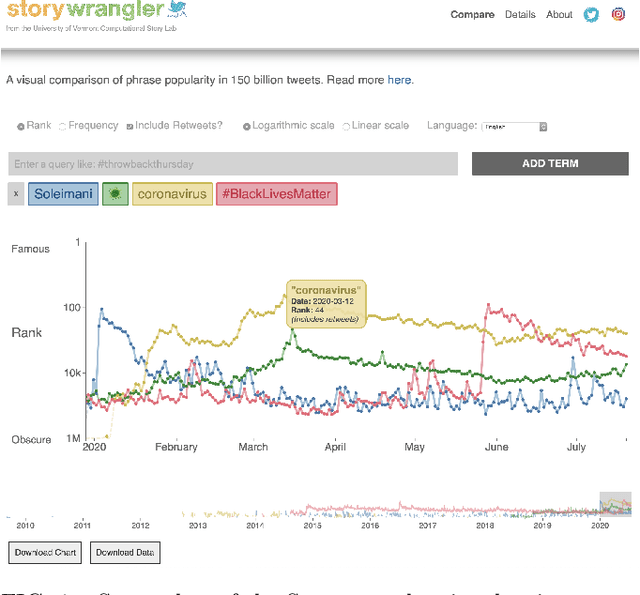
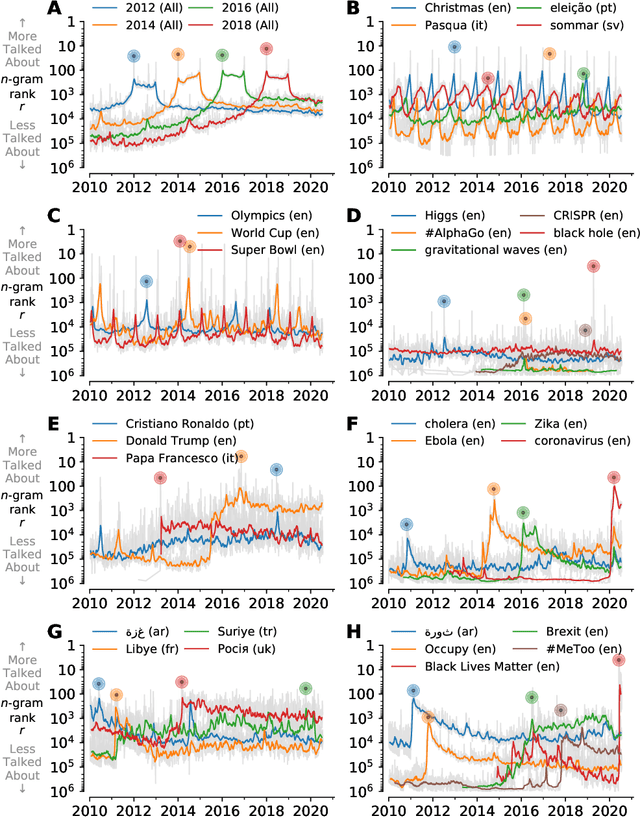
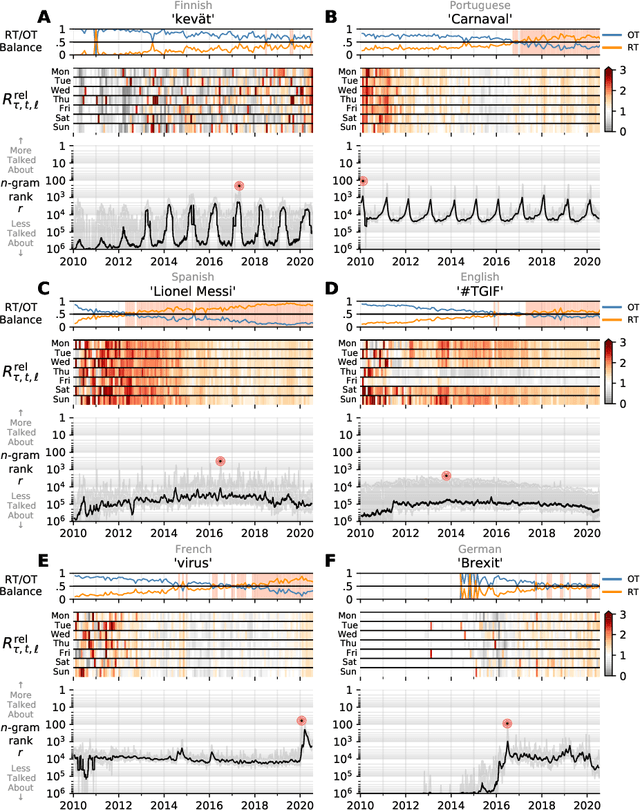
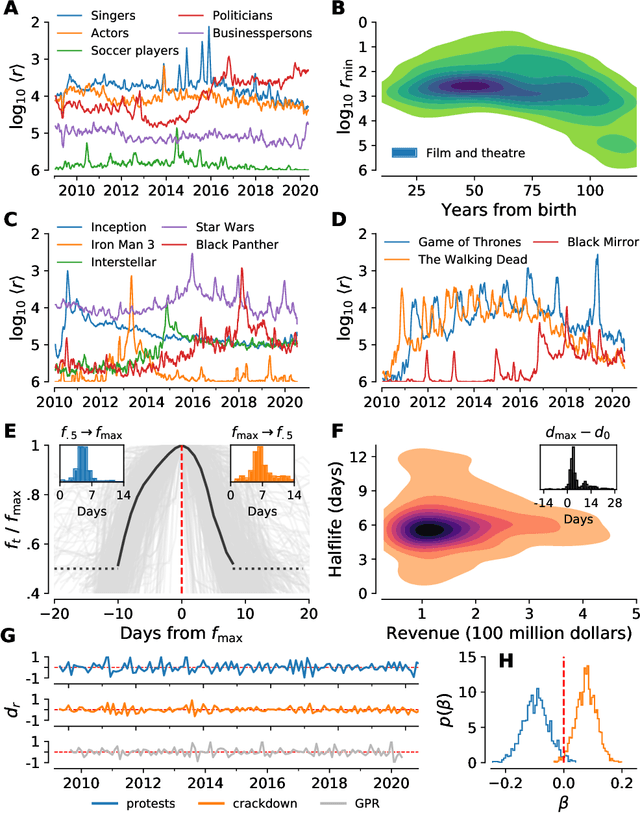
In real-time, Twitter strongly imprints world events, popular culture, and the day-to-day; Twitter records an ever growing compendium of language use and change; and Twitter has been shown to enable certain kinds of prediction. Vitally, and absent from many standard corpora such as books and news archives, Twitter also encodes popularity and spreading through retweets. Here, we describe Storywrangler, an ongoing, day-scale curation of over 100 billion tweets containing around 1 trillion 1-grams from 2008 to 2020. For each day, we break tweets into 1-, 2-, and 3-grams across 150+ languages, record usage frequencies, and generate Zipf distributions. We make the data set available through an interactive time series viewer, and as downloadable time series and daily distributions. We showcase a few examples of the many possible avenues of study we aim to enable including how social amplification can be visualized through 'contagiograms'.
The growing echo chamber of social media: Measuring temporal and social contagion dynamics for over 150 languages on Twitter for 2009--2020
Mar 15, 2020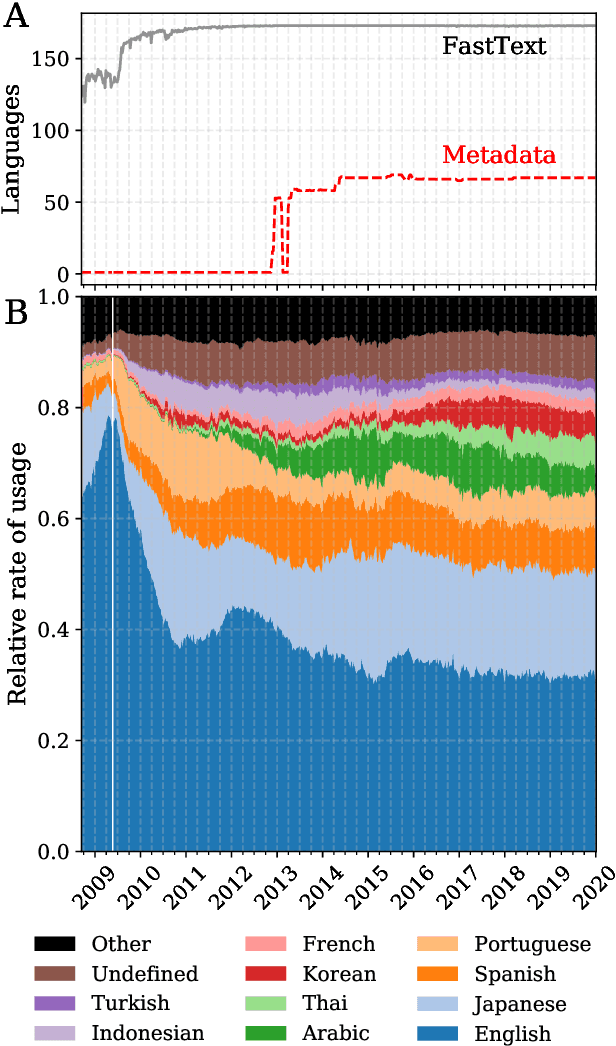
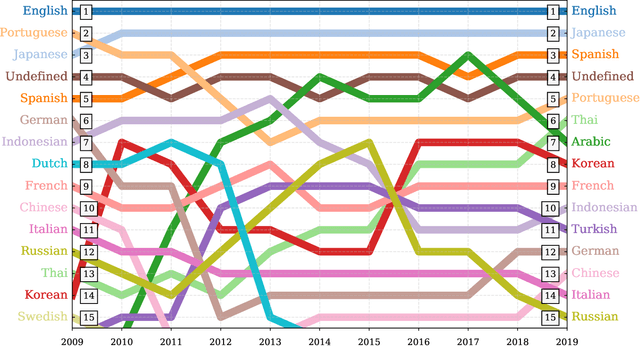
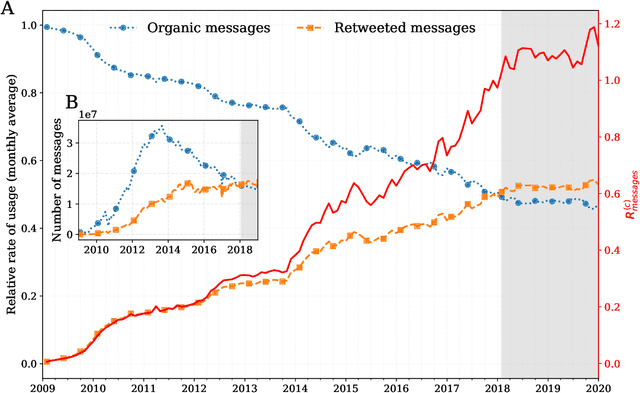
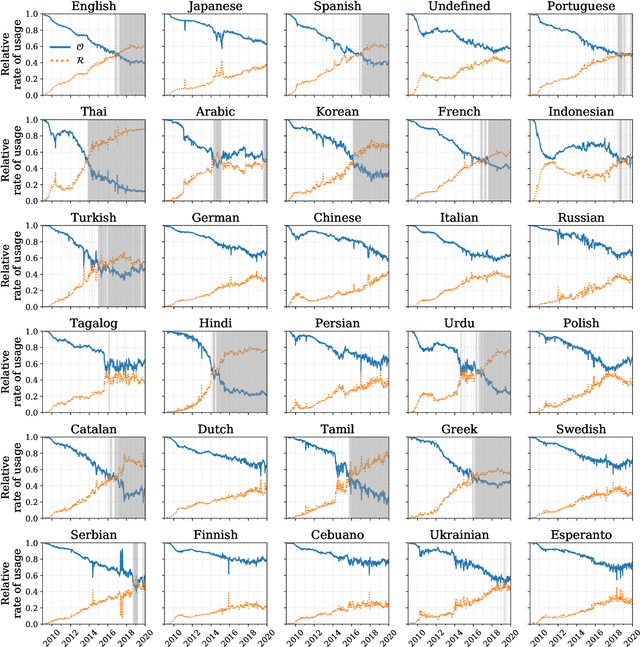
Working from a dataset of 118 billion messages running from the start of 2009 to the end of 2019, we identify and explore the relative daily use of over 150 languages on Twitter. We find that eight languages comprise 80% of all tweets, with English, Japanese, Spanish, and Portuguese being the most dominant. To quantify each language's level of being a Twitter `echo chamber' over time, we compute the `contagion ratio': the balance of retweets to organic messages. We find that for the most common languages on Twitter there is a growing tendency, though not universal, to retweet rather than share new content. By the end of 2019, the contagion ratios for half of the top 30 languages, including English and Spanish, had reached above 1---the naive contagion threshold. In 2019, the top 5 languages with the highest average daily ratios were, in order, Thai (7.3), Hindi, Tamil, Urdu, and Catalan, while the bottom 5 were Russian, Swedish, Esperanto, Cebuano, and Finnish (0.26). Further, we show that over time, the contagion ratios for most common languages are growing more strongly than those of rare languages.