 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting semantic lexicons using word embeddings and transfer learning
Sep 18, 2021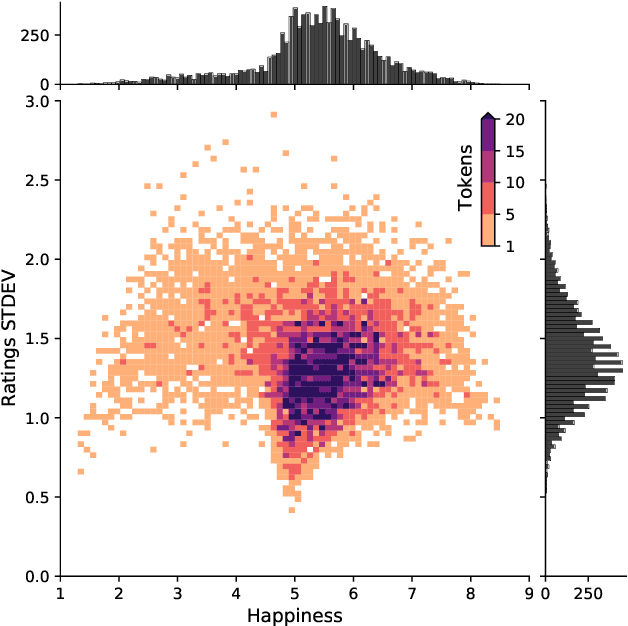
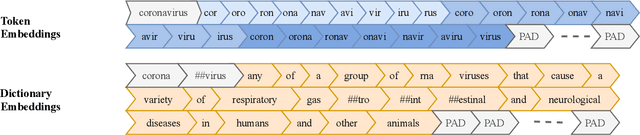
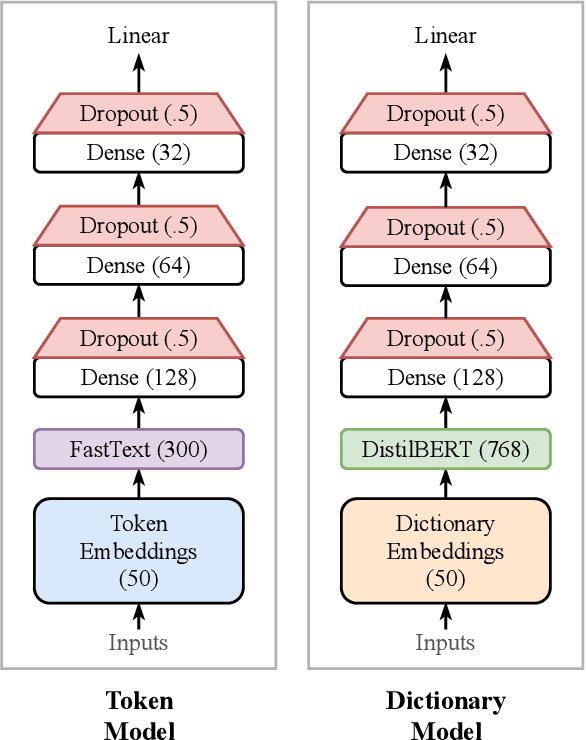
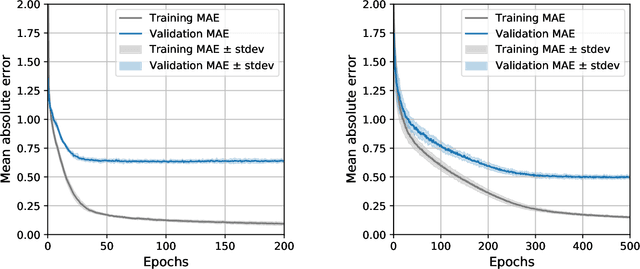
Sentiment-aware intelligent systems are essential to a wide array of applications including marketing, political campaigns, recommender systems, behavioral economics, social psychology, and national security. These sentiment-aware intelligent systems are driven by language models which broadly fall into two paradigms: 1. Lexicon-based and 2. Contextual. Although recent contextual models are increasingly dominant, we still see demand for lexicon-based models because of their interpretability and ease of use. For example, lexicon-based models allow researchers to readily determine which words and phrases contribute most to a change in measured sentiment. A challenge for any lexicon-based approach is that the lexicon needs to be routinely expanded with new words and expressions. Crowdsourcing annotations for semantic dictionaries may be an expensive and time-consuming task. Here, we propose two models for predicting sentiment scores to augment semantic lexicons at a relatively low cost using word embeddings and transfer learning. Our first model establishes a baseline employing a simple and shallow neural network initialized with pre-trained word embeddings using a non-contextual approach. Our second model improves upon our baseline, featuring a deep Transformer-based network that brings to bear word definitions to estimate their lexical polarity. Our evaluation shows that both models are able to score new words with a similar accuracy to reviewers from Amazon Mechanical Turk, but at a fraction of the cost.
Object Tracking and Geo-localization from Street Images
Jul 13, 2021
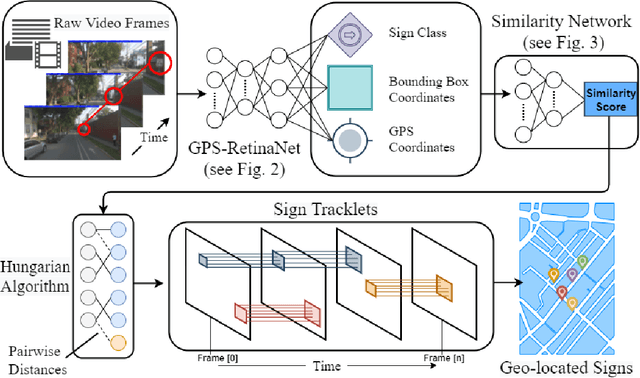
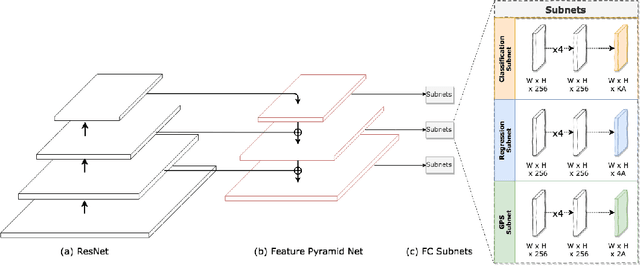

Geo-localizing static objects from street images is challenging but also very important for road asset mapping and autonomous driving. In this paper we present a two-stage framework that detects and geolocalizes traffic signs from low frame rate street videos. Our proposed system uses a modified version of RetinaNet (GPS-RetinaNet), which predicts a positional offset for each sign relative to the camera, in addition to performing the standard classification and bounding box regression. Candidate sign detections from GPS-RetinaNet are condensed into geolocalized signs by our custom tracker, which consists of a learned metric network and a variant of the Hungarian Algorithm. Our metric network estimates the similarity between pairs of detections, then the Hungarian Algorithm matches detections across images using the similarity scores provided by the metric network. Our models were trained using an updated version of the ARTS dataset, which contains 25,544 images and 47.589 sign annotations ~\cite{arts}. The proposed dataset covers a diverse set of environments gathered from a broad selection of roads. Each annotaiton contains a sign class label, its geospatial location, an assembly label, a side of road indicator, and unique identifiers that aid in the evaluation. This dataset will support future progress in the field, and the proposed system demonstrates how to take advantage of some of the unique characteristics of a realistic geolocalization dataset.