 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Riemannian Networks for EEG Decoding
Dec 21, 2022State-of-the-art performance in electroencephalography (EEG) decoding tasks is currently often achieved with either Deep-Learning or Riemannian-Geometry-based decoders. Recently, there is growing interest in Deep Riemannian Networks (DRNs) possibly combining the advantages of both previous classes of methods. However, there are still a range of topics where additional insight is needed to pave the way for a more widespread application of DRNs in EEG. These include architecture design questions such as network size and end-to-end ability as well as model training questions. How these factors affect model performance has not been explored. Additionally, it is not clear how the data within these networks is transformed, and whether this would correlate with traditional EEG decoding. Our study aims to lay the groundwork in the area of these topics through the analysis of DRNs for EEG with a wide range of hyperparameters. Networks were tested on two public EEG datasets and compared with state-of-the-art ConvNets. Here we propose end-to-end EEG SPDNet (EE(G)-SPDNet), and we show that this wide, end-to-end DRN can outperform the ConvNets, and in doing so use physiologically plausible frequency regions. We also show that the end-to-end approach learns more complex filters than traditional band-pass filters targeting the classical alpha, beta, and gamma frequency bands of the EEG, and that performance can benefit from channel specific filtering approaches. Additionally, architectural analysis revealed areas for further improvement due to the possible loss of Riemannian specific information throughout the network. Our study thus shows how to design and train DRNs to infer task-related information from the raw EEG without the need of handcrafted filterbanks and highlights the potential of end-to-end DRNs such as EE(G)-SPDNet for high-performance EEG decoding.
Visual and Object Geo-localization: A Comprehensive Survey
Dec 30, 2021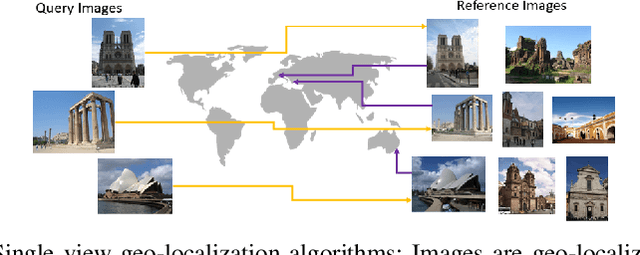
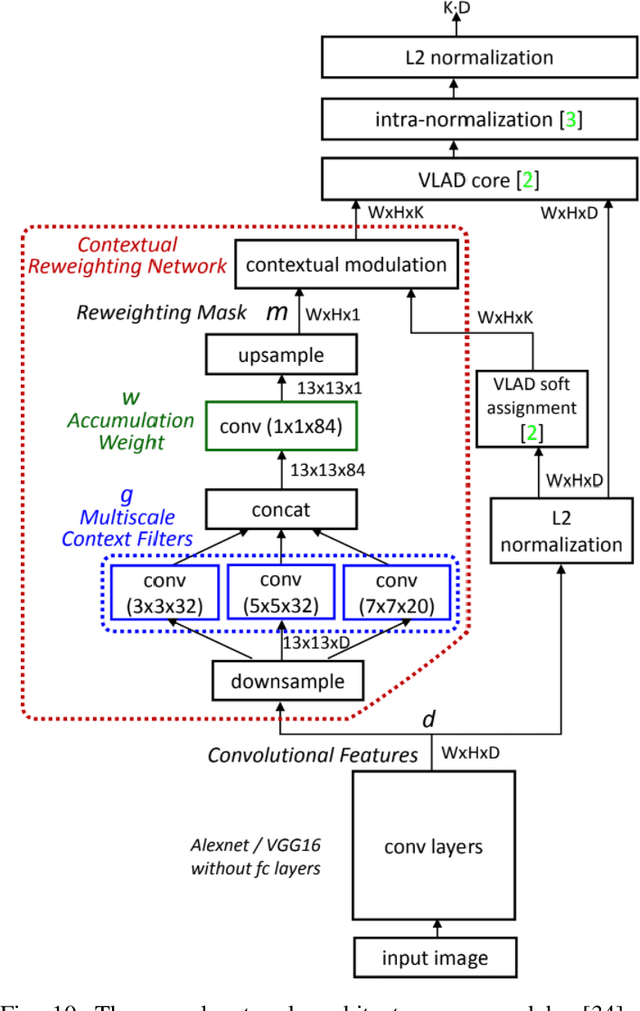
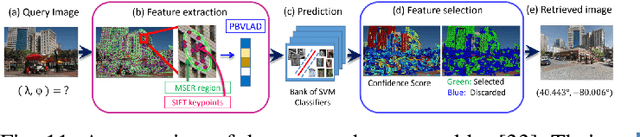
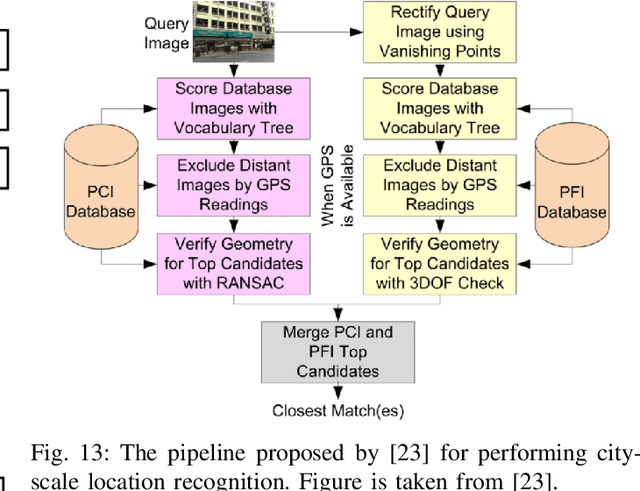
The concept of geo-localization refers to the process of determining where on earth some `entity' is located, typically using Global Positioning System (GPS) coordinates. The entity of interest may be an image, sequence of images, a video, satellite image, or even objects visible within the image. As massive datasets of GPS tagged media have rapidly become available due to smartphones and the internet, and deep learning has risen to enhance the performance capabilities of machine learning models, the fields of visual and object geo-localization have emerged due to its significant impact on a wide range of applications such as augmented reality, robotics, self-driving vehicles, road maintenance, and 3D reconstruction. This paper provides a comprehensive survey of geo-localization involving images, which involves either determining from where an image has been captured (Image geo-localization) or geo-locating objects within an image (Object geo-localization). We will provide an in-depth study, including a summary of popular algorithms, a description of proposed datasets, and an analysis of performance results to illustrate the current state of each field.
Object Tracking and Geo-localization from Street Images
Jul 13, 2021
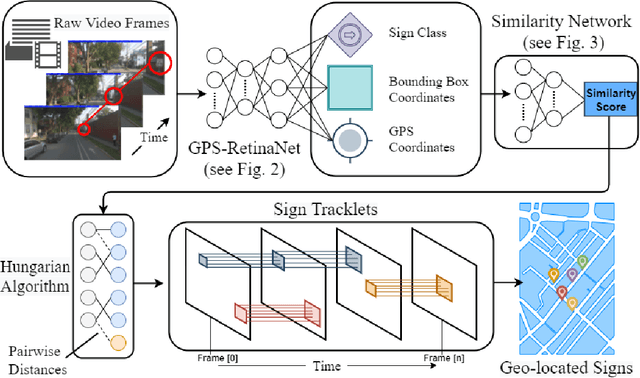
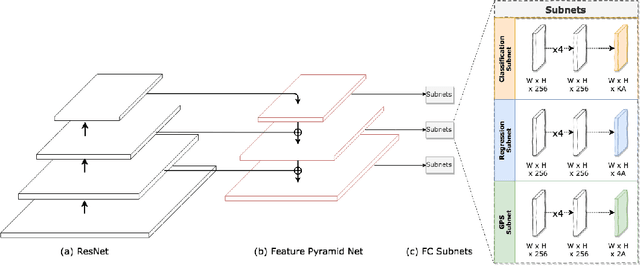

Geo-localizing static objects from street images is challenging but also very important for road asset mapping and autonomous driving. In this paper we present a two-stage framework that detects and geolocalizes traffic signs from low frame rate street videos. Our proposed system uses a modified version of RetinaNet (GPS-RetinaNet), which predicts a positional offset for each sign relative to the camera, in addition to performing the standard classification and bounding box regression. Candidate sign detections from GPS-RetinaNet are condensed into geolocalized signs by our custom tracker, which consists of a learned metric network and a variant of the Hungarian Algorithm. Our metric network estimates the similarity between pairs of detections, then the Hungarian Algorithm matches detections across images using the similarity scores provided by the metric network. Our models were trained using an updated version of the ARTS dataset, which contains 25,544 images and 47.589 sign annotations ~\cite{arts}. The proposed dataset covers a diverse set of environments gathered from a broad selection of roads. Each annotaiton contains a sign class label, its geospatial location, an assembly label, a side of road indicator, and unique identifiers that aid in the evaluation. This dataset will support future progress in the field, and the proposed system demonstrates how to take advantage of some of the unique characteristics of a realistic geolocalization dataset.
Points2Polygons: Context-Based Segmentation from Weak Labels Using Adversarial Networks
Jun 05, 2021
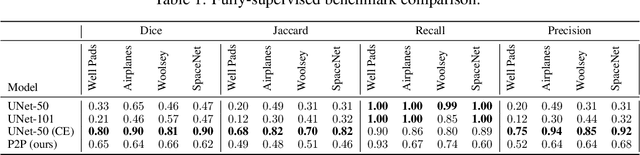
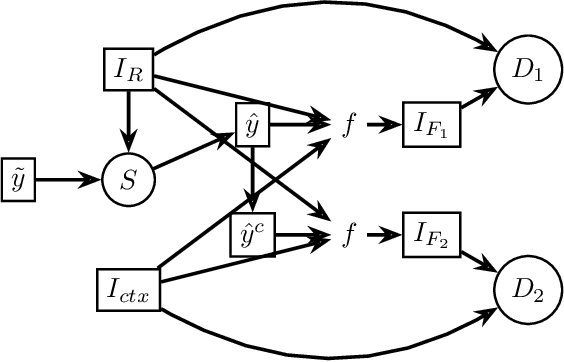
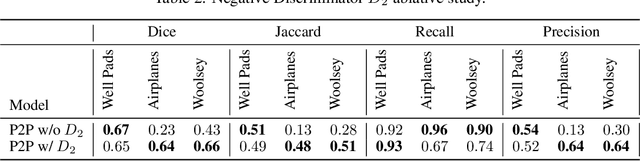
In applied image segmentation tasks, the ability to provide numerous and precise labels for training is paramount to the accuracy of the model at inference time. However, this overhead is often neglected, and recently proposed segmentation architectures rely heavily on the availability and fidelity of ground truth labels to achieve state-of-the-art accuracies. Failure to acknowledge the difficulty in creating adequate ground truths can lead to an over-reliance on pre-trained models or a lack of adoption in real-world applications. We introduce Points2Polygons (P2P), a model which makes use of contextual metric learning techniques that directly addresses this problem. Points2Polygons performs well against existing fully-supervised segmentation baselines with limited training data, despite using lightweight segmentation models (U-Net with a ResNet18 backbone) and having access to only weak labels in the form of object centroids and no pre-training. We demonstrate this on several different small but non-trivial datasets. We show that metric learning using contextual data provides key insights for self-supervised tasks in general, and allow segmentation models to easily generalize across traditionally label-intensive domains in computer vision.
Machine-Learning-Based Diagnostics of EEG Pathology
Feb 11, 2020

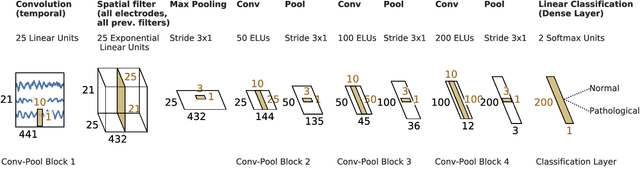
Machine learning (ML) methods have the potential to automate clinical EEG analysis. They can be categorized into feature-based (with handcrafted features), and end-to-end approaches (with learned features). Previous studies on EEG pathology decoding have typically analyzed a limited number of features, decoders, or both. For a I) more elaborate feature-based EEG analysis, and II) in-depth comparisons of both approaches, here we first develop a comprehensive feature-based framework, and then compare this framework to state-of-the-art end-to-end methods. To this aim, we apply the proposed feature-based framework and deep neural networks including an EEG-optimized temporal convolutional network (TCN) to the task of pathological versus non-pathological EEG classification. For a robust comparison, we chose the Temple University Hospital (TUH) Abnormal EEG Corpus (v2.0.0), which contains approximately 3000 EEG recordings. The results demonstrate that the proposed feature-based decoding framework can achieve accuracies on the same level as state-of-the-art deep neural networks. We find accuracies across both approaches in an astonishingly narrow range from 81--86\%. Moreover, visualizations and analyses indicated that both approaches used similar aspects of the data, e.g., delta and theta band power at temporal electrode locations. We argue that the accuracies of current binary EEG pathology decoders could saturate near 90\% due to the imperfect inter-rater agreement of the clinical labels, and that such decoders are already clinically useful, such as in areas where clinical EEG experts are rare. We make the proposed feature-based framework available open source and thus offer a new tool for EEG machine learning research.
Artificial Intelligence Approaches
Aug 27, 2019
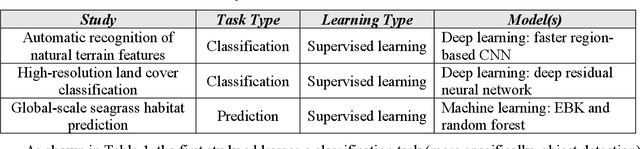

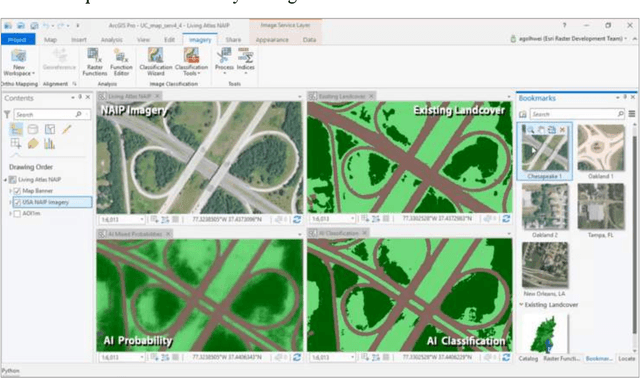
Artificial Intelligence (AI) has received tremendous attention from academia, industry, and the general public in recent years. The integration of geography and AI, or GeoAI, provides novel approaches for addressing a variety of problems in the natural environment and our human society. This entry briefly reviews the recent development of AI with a focus on machine learning and deep learning approaches. We discuss the integration of AI with geography and particularly geographic information science, and present a number of GeoAI applications and possible future directions.
* 12 pages, 5 figures