 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Inspired Inverse Learning for Planning and Control
May 26, 2026We present a neuro-inspired framework for embodied planning and control. Building on three principles that enable fast and highly effective goal-directed behavior in the mammalian brain - paired forward/inverse internal models, open-loop multi-step motor commands, and sequential, hierarchical organization of action - our Inverter framework uses learned components, trained end-to-end through Inverse Learning (IL) and supplemented where natural by analytic or algorithmic modules; we formalize IL and delineate it from supervised, reinforcement, and imitation learning. IL bridges Reinforcement Learning (RL)-style amortization, which runs in a single forward pass but emits only one action at a time, and Optimal Control (OC)-style sequence planning over whole trajectories, but with iterative test-time computation. Single Inverters or hierarchical n=2 Inverter stacks match or improve on offline-RL and diffusion-planner baselines on all 3 maze2d and 6 antmaze D4RL variants by an average of +24.2% (range -1.9% to +78.2%), at one-to-two orders of magnitude less inference compute time. Distinctively, optimizing through the Forward Model (FoM) over the entire T-step action sequence - rather than per step - lets Inverters produce smooth, goal-coherent, trajectory-wide structure and reach control policies closer to the analytic optimum than the policy underlying the training data itself. We also identify a failure mode of IL: FoM hacking under narrow training-data coverage, which we mitigate by using random training data with broader coverage. As an application example, a Pulse Inverter synthesizes arbitrary single-qubit quantum gates with fidelity matching the standard iterative numerical baseline (GRAPE), at more than 1000x lower per-gate compute time. In summary, we conclude that IL enables a versatile class of world-interfaces, especially for latency- and resource-critical embodied AI.
Human-AI Teaming Using Large Language Models: Boosting Brain-Computer Interfacing (BCI) and Brain Research
Dec 30, 2024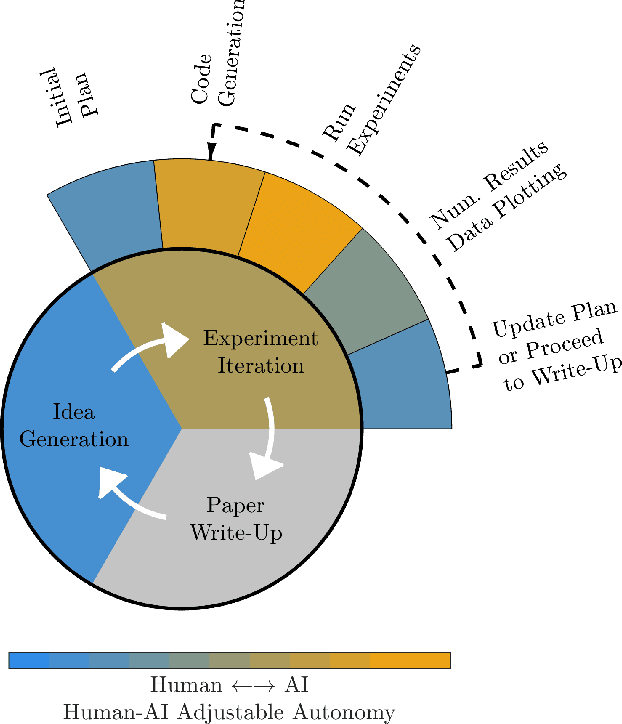
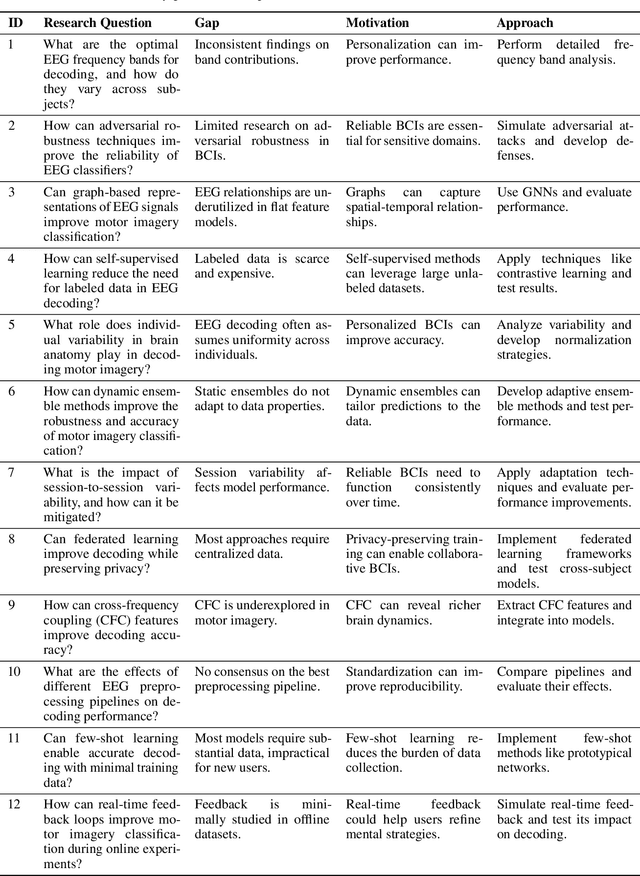

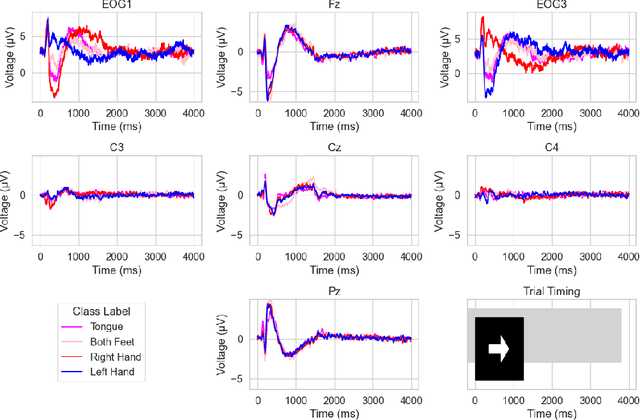
Recently, there is an increasing interest in using artificial intelligence (AI) to automate aspects of the research process, or even autonomously conduct the full research cycle from idea generation, over data analysis, to composing and evaluation of scientific manuscripts. Examples of working AI scientist systems have been demonstrated for computer science tasks and running molecular biology labs. While some approaches aim for full autonomy of the scientific AI, others rather aim for leveraging human-AI teaming. Here, we address how to adapt such approaches for boosting Brain-Computer Interface (BCI) development, as well as brain research resp. neuroscience at large. We argue that at this time, a strong emphasis on human-AI teaming, in contrast to fully autonomous AI BCI researcher will be the most promising way forward. We introduce the collaborative workspaces concept for human-AI teaming based on a set of Janusian design principles, looking both ways, to the human as well as to the AI side. Based on these principles, we present ChatBCI, a Python-based toolbox for enabling human-AI collaboration based on interaction with Large Language Models (LLMs), designed for BCI research and development projects. We show how ChatBCI was successfully used in a concrete BCI project on advancing motor imagery decoding from EEG signals. Our approach can be straightforwardly extended to broad neurotechnological and neuroscientific topics, and may by design facilitate human expert knowledge transfer to scientific AI systems in general.
Deep Riemannian Networks for EEG Decoding
Dec 21, 2022State-of-the-art performance in electroencephalography (EEG) decoding tasks is currently often achieved with either Deep-Learning or Riemannian-Geometry-based decoders. Recently, there is growing interest in Deep Riemannian Networks (DRNs) possibly combining the advantages of both previous classes of methods. However, there are still a range of topics where additional insight is needed to pave the way for a more widespread application of DRNs in EEG. These include architecture design questions such as network size and end-to-end ability as well as model training questions. How these factors affect model performance has not been explored. Additionally, it is not clear how the data within these networks is transformed, and whether this would correlate with traditional EEG decoding. Our study aims to lay the groundwork in the area of these topics through the analysis of DRNs for EEG with a wide range of hyperparameters. Networks were tested on two public EEG datasets and compared with state-of-the-art ConvNets. Here we propose end-to-end EEG SPDNet (EE(G)-SPDNet), and we show that this wide, end-to-end DRN can outperform the ConvNets, and in doing so use physiologically plausible frequency regions. We also show that the end-to-end approach learns more complex filters than traditional band-pass filters targeting the classical alpha, beta, and gamma frequency bands of the EEG, and that performance can benefit from channel specific filtering approaches. Additionally, architectural analysis revealed areas for further improvement due to the possible loss of Riemannian specific information throughout the network. Our study thus shows how to design and train DRNs to infer task-related information from the raw EEG without the need of handcrafted filterbanks and highlights the potential of end-to-end DRNs such as EE(G)-SPDNet for high-performance EEG decoding.
When less is more: Simplifying inputs aids neural network understanding
Feb 01, 2022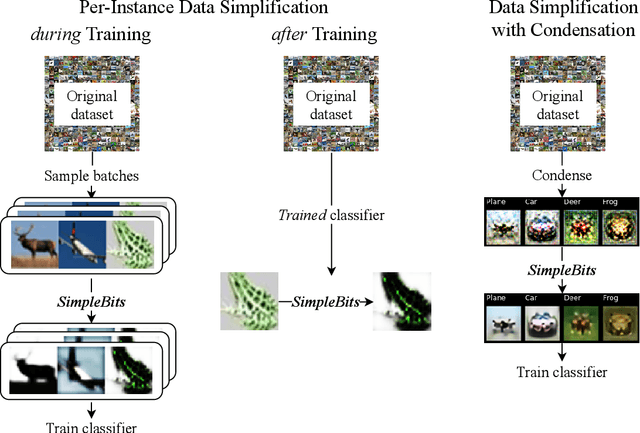

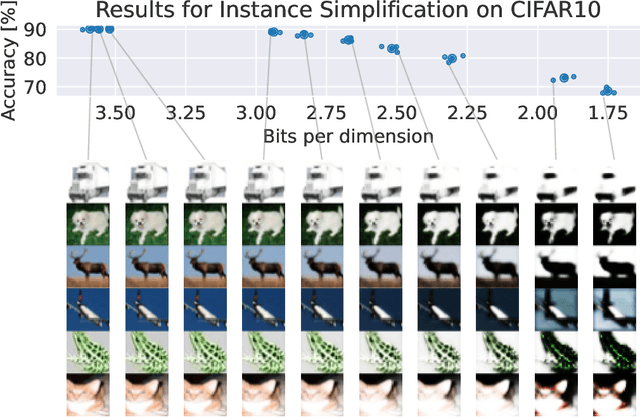
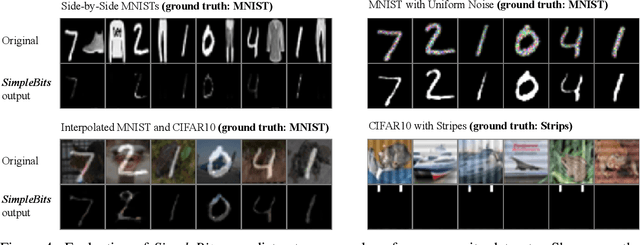
How do neural network image classifiers respond to simpler and simpler inputs? And what do such responses reveal about the learning process? To answer these questions, we need a clear measure of input simplicity (or inversely, complexity), an optimization objective that correlates with simplification, and a framework to incorporate such objective into training and inference. Lastly we need a variety of testbeds to experiment and evaluate the impact of such simplification on learning. In this work, we measure simplicity with the encoding bit size given by a pretrained generative model, and minimize the bit size to simplify inputs in training and inference. We investigate the effect of such simplification in several scenarios: conventional training, dataset condensation and post-hoc explanations. In all settings, inputs are simplified along with the original classification task, and we investigate the trade-off between input simplicity and task performance. For images with injected distractors, such simplification naturally removes superfluous information. For dataset condensation, we find that inputs can be simplified with almost no accuracy degradation. When used in post-hoc explanation, our learning-based simplification approach offers a valuable new tool to explore the basis of network decisions.
Understanding Anomaly Detection with Deep Invertible Networks through Hierarchies of Distributions and Features
Jun 25, 2020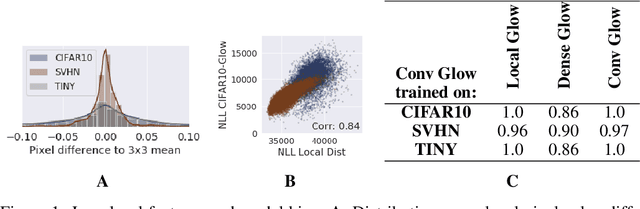
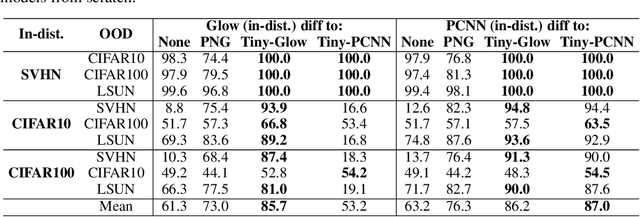
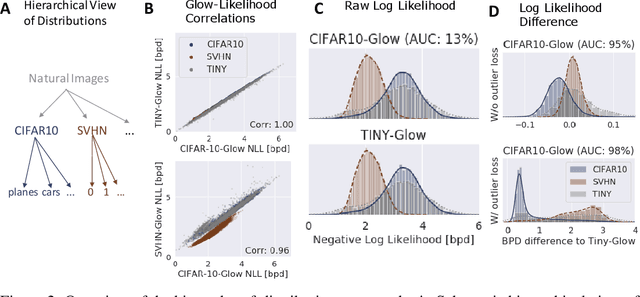
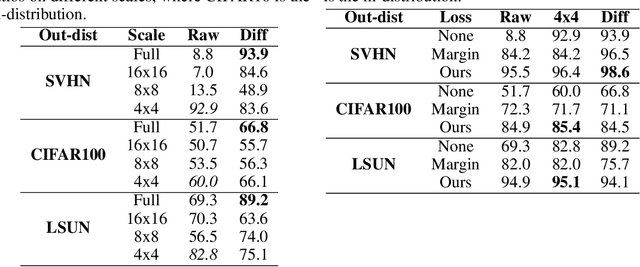
Deep generative networks trained via maximum likelihood on a natural image dataset like CIFAR10 often assign high likelihoods to images from datasets with different objects (e.g., SVHN). We refine previous investigations of this failure at anomaly detection for invertible generative networks and provide a clear explanation of it as a combination of model bias and domain prior: Convolutional networks learn similar low-level feature distributions when trained on any natural image dataset and these low-level features dominate the likelihood. Hence, when the discriminative features between inliers and outliers are on a high-level, e.g., object shapes, anomaly detection becomes particularly challenging. To remove the negative impact of model bias and domain prior on detecting high-level differences, we propose two methods, first, using the log likelihood ratios of two identical models, one trained on the in-distribution data (e.g., CIFAR10) and the other one on a more general distribution of images (e.g., 80 Million Tiny Images). We also derive a novel outlier loss for the in-distribution network on samples from the more general distribution to further improve the performance. Secondly, using a multi-scale model like Glow, we show that low-level features are mainly captured at early scales. Therefore, using only the likelihood contribution of the final scale performs remarkably well for detecting high-level feature differences of the out-of-distribution and the in-distribution. This method is especially useful if one does not have access to a suitable general distribution. Overall, our methods achieve strong anomaly detection performance in the unsupervised setting, reaching comparable performance as state-of-the-art classifier-based methods in the supervised setting.
Machine-Learning-Based Diagnostics of EEG Pathology
Feb 11, 2020
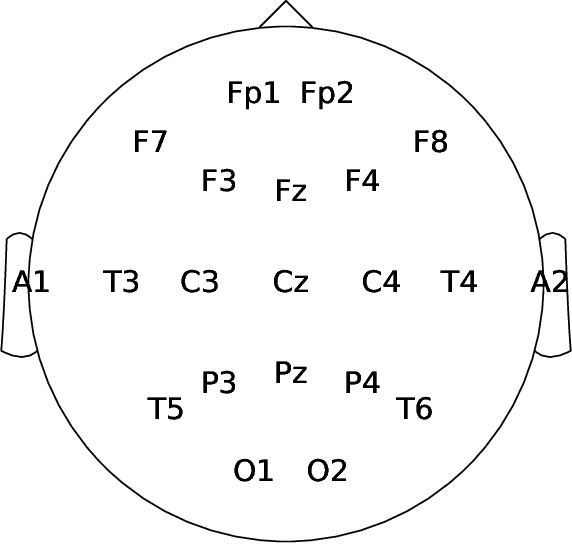

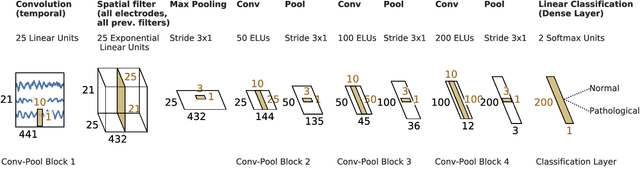
Machine learning (ML) methods have the potential to automate clinical EEG analysis. They can be categorized into feature-based (with handcrafted features), and end-to-end approaches (with learned features). Previous studies on EEG pathology decoding have typically analyzed a limited number of features, decoders, or both. For a I) more elaborate feature-based EEG analysis, and II) in-depth comparisons of both approaches, here we first develop a comprehensive feature-based framework, and then compare this framework to state-of-the-art end-to-end methods. To this aim, we apply the proposed feature-based framework and deep neural networks including an EEG-optimized temporal convolutional network (TCN) to the task of pathological versus non-pathological EEG classification. For a robust comparison, we chose the Temple University Hospital (TUH) Abnormal EEG Corpus (v2.0.0), which contains approximately 3000 EEG recordings. The results demonstrate that the proposed feature-based decoding framework can achieve accuracies on the same level as state-of-the-art deep neural networks. We find accuracies across both approaches in an astonishingly narrow range from 81--86\%. Moreover, visualizations and analyses indicated that both approaches used similar aspects of the data, e.g., delta and theta band power at temporal electrode locations. We argue that the accuracies of current binary EEG pathology decoders could saturate near 90\% due to the imperfect inter-rater agreement of the clinical labels, and that such decoders are already clinically useful, such as in areas where clinical EEG experts are rare. We make the proposed feature-based framework available open source and thus offer a new tool for EEG machine learning research.
Deep Invertible Networks for EEG-based brain-signal decoding
Jul 17, 2019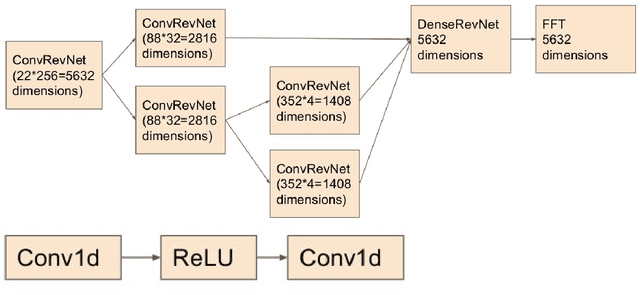
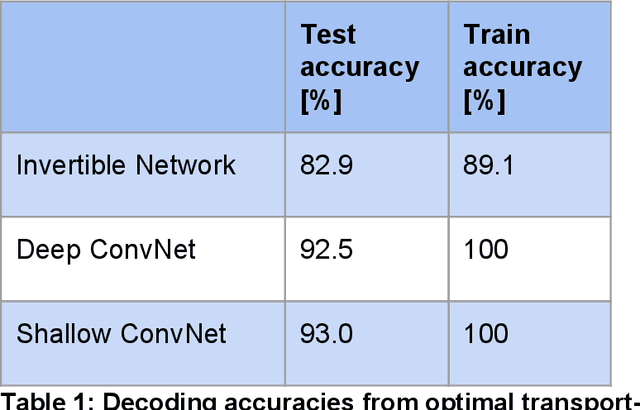
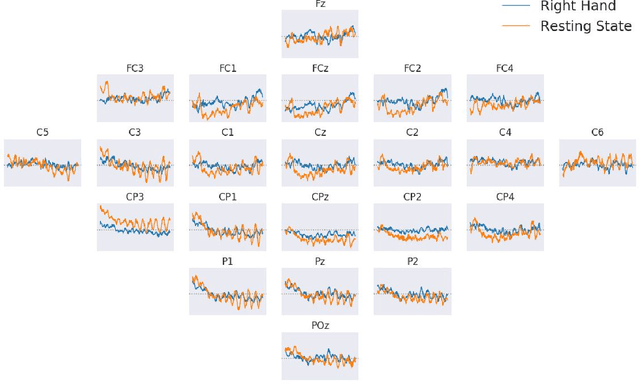
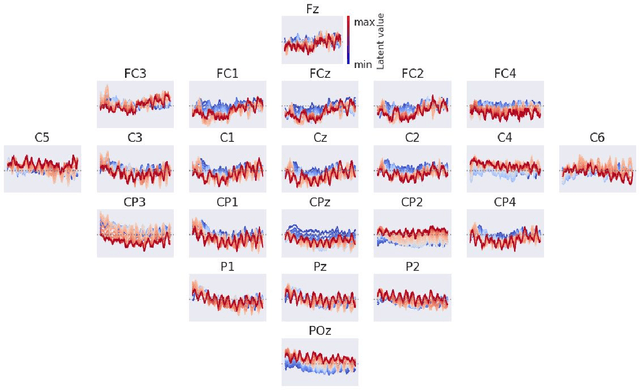
In this manuscript, we investigate deep invertible networks for EEG-based brain signal decoding and find them to generate realistic EEG signals as well as classify novel signals above chance. Further ideas for their regularization towards better decoding accuracies are discussed.
Intracranial Error Detection via Deep Learning
Nov 02, 2018


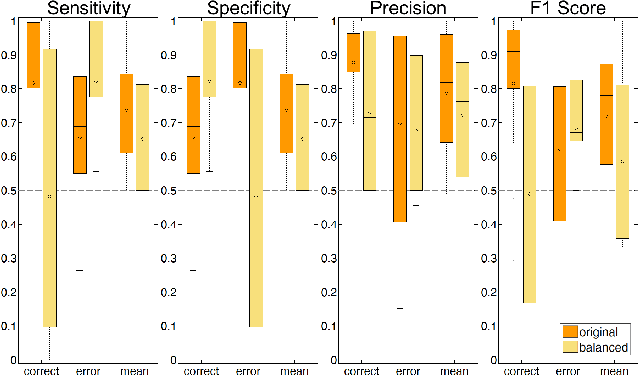
Deep learning techniques have revolutionized the field of machine learning and were recently successfully applied to various classification problems in noninvasive electroencephalography (EEG). However, these methods were so far only rarely evaluated for use in intracranial EEG. We employed convolutional neural networks (CNNs) to classify and characterize the error-related brain response as measured in 24 intracranial EEG recordings. Decoding accuracies of CNNs were significantly higher than those of a regularized linear discriminant analysis. Using time-resolved deep decoding, it was possible to classify errors in various regions in the human brain, and further to decode errors over 200 ms before the actual erroneous button press, e.g., in the precentral gyrus. Moreover, deeper networks performed better than shallower networks in distinguishing correct from error trials in all-channel decoding. In single recordings, up to 100 % decoding accuracy was achieved. Visualization of the networks' learned features indicated that multivariate decoding on an ensemble of channels yields related, albeit non-redundant information compared to single-channel decoding. In summary, here we show the usefulness of deep learning for both intracranial error decoding and mapping of the spatio-temporal structure of the human error processing network.
Training Generative Reversible Networks
Aug 23, 2018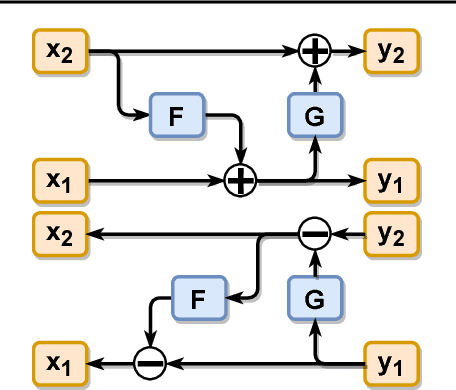


Generative models with an encoding component such as autoencoders currently receive great interest. However, training of autoencoders is typically complicated by the need to train a separate encoder and decoder model that have to be enforced to be reciprocal to each other. To overcome this problem, by-design reversible neural networks (RevNets) had been previously used as generative models either directly optimizing the likelihood of the data under the model or using an adversarial approach on the generated data. Here, we instead investigate their performance using an adversary on the latent space in the adversarial autoencoder framework. We investigate the generative performance of RevNets on the CelebA dataset, showing that generative RevNets can generate coherent faces with similar quality as Variational Autoencoders. This first attempt to use RevNets inside the adversarial autoencoder framework slightly underperformed relative to recent advanced generative models using an autoencoder component on CelebA, but this gap may diminish with further optimization of the training setup of generative RevNets. In addition to the experiments on CelebA, we show a proof-of-principle experiment on the MNIST dataset suggesting that adversary-free trained RevNets can discover meaningful latent dimensions without pre-specifying the number of dimensions of the latent sampling distribution. In summary, this study shows that RevNets can be employed in different generative training settings. Source code for this study is at https://github.com/robintibor/generative-reversible
A large-scale evaluation framework for EEG deep learning architectures
Jul 25, 2018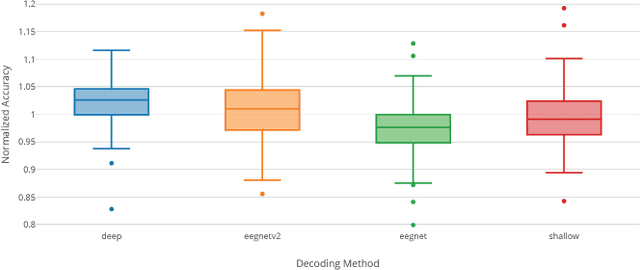
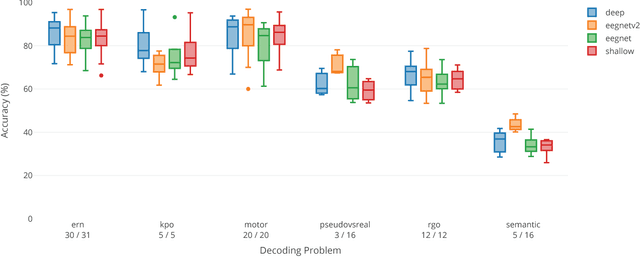
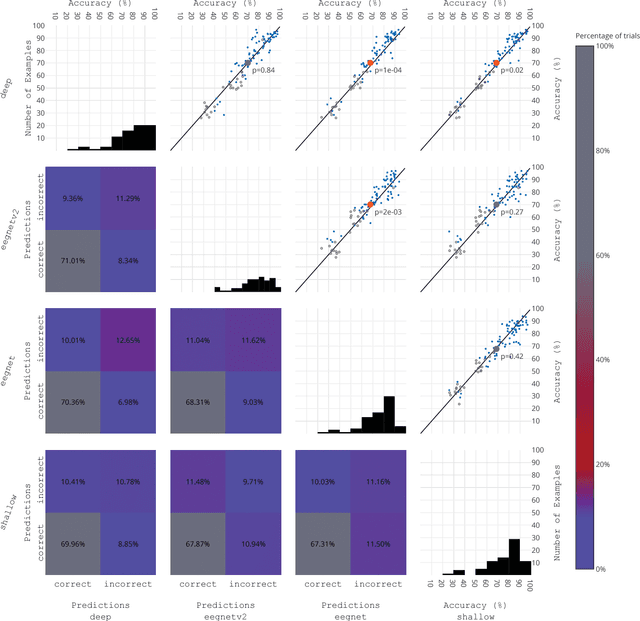
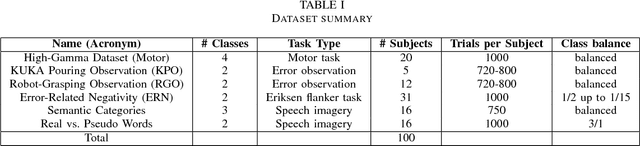
EEG is the most common signal source for noninvasive BCI applications. For such applications, the EEG signal needs to be decoded and translated into appropriate actions. A recently emerging EEG decoding approach is deep learning with Convolutional or Recurrent Neural Networks (CNNs, RNNs) with many different architectures already published. Here we present a novel framework for the large-scale evaluation of different deep-learning architectures on different EEG datasets. This framework comprises (i) a collection of EEG datasets currently including 100 examples (recording sessions) from six different classification problems, (ii) a collection of different EEG decoding algorithms, and (iii) a wrapper linking the decoders to the data as well as handling structured documentation of all settings and (hyper-) parameters and statistics, designed to ensure transparency and reproducibility. As an applications example we used our framework by comparing three publicly available CNN architectures: the Braindecode Deep4 ConvNet, Braindecode Shallow ConvNet, and two versions of EEGNet. We also show how our framework can be used to study similarities and differences in the performance of different decoding methods across tasks. We argue that the deep learning EEG framework as described here could help to tap the full potential of deep learning for BCI applications.