 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Generative Reversible Networks
Paper and Code
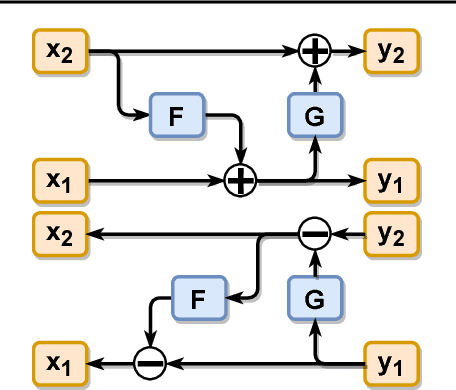

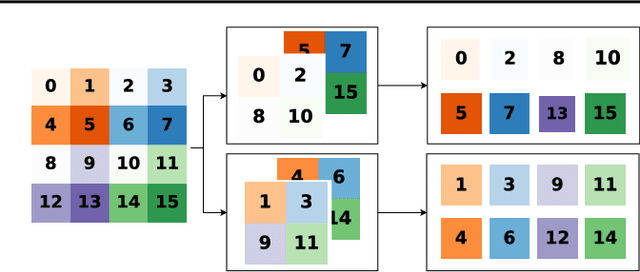

Generative models with an encoding component such as autoencoders currently receive great interest. However, training of autoencoders is typically complicated by the need to train a separate encoder and decoder model that have to be enforced to be reciprocal to each other. To overcome this problem, by-design reversible neural networks (RevNets) had been previously used as generative models either directly optimizing the likelihood of the data under the model or using an adversarial approach on the generated data. Here, we instead investigate their performance using an adversary on the latent space in the adversarial autoencoder framework. We investigate the generative performance of RevNets on the CelebA dataset, showing that generative RevNets can generate coherent faces with similar quality as Variational Autoencoders. This first attempt to use RevNets inside the adversarial autoencoder framework slightly underperformed relative to recent advanced generative models using an autoencoder component on CelebA, but this gap may diminish with further optimization of the training setup of generative RevNets. In addition to the experiments on CelebA, we show a proof-of-principle experiment on the MNIST dataset suggesting that adversary-free trained RevNets can discover meaningful latent dimensions without pre-specifying the number of dimensions of the latent sampling distribution. In summary, this study shows that RevNets can be employed in different generative training settings. Source code for this study is at https://github.com/robintibor/generative-reversible