 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEG-CLIP : Learning EEG representations from natural language descriptions
Mar 18, 2025Deep networks for electroencephalogram (EEG) decoding are currently often trained to only solve a specific task like pathology or gender decoding. A more general approach leveraging the medical reports of clinical EEG recordings is to learn mappings between medical reports and EEG recordings. This approach was pioneered in the computer vision domain matching images and their text captions and subsequently allowed to do successful zero-shot decoding using textual class prompts. In this work, we follow this approach and develop a contrastive learning framework EEG-CLIP that aligns EEG time series and their corresponding clinical text descriptions in a shared embedding space. We investigate its potential for versatile EEG decoding, assessing performance on a range of few-shot and zero-shot settings. Overall, results show that EEG-CLIP manages to nontrivially align text and EEG representations. Our work presents a promising approach to learn general EEG representations, which could enable easier analyses of diverse decoding questions through zero shot decoding or training task-specific models from fewer training examples. The code for reproducing our results is available at https://github.com/tidiane-camaret/EEGClip.
TuneTables: Context Optimization for Scalable Prior-Data Fitted Networks
Feb 17, 2024



While tabular classification has traditionally relied on from-scratch training, a recent breakthrough called prior-data fitted networks (PFNs) challenges this approach. Similar to large language models, PFNs make use of pretraining and in-context learning to achieve strong performance on new tasks in a single forward pass. However, current PFNs have limitations that prohibit their widespread adoption. Notably, TabPFN achieves very strong performance on small tabular datasets but is not designed to make predictions for datasets of size larger than 1000. In this work, we overcome these limitations and substantially improve the performance of PFNs by developing context optimization techniques for PFNs. Specifically, we propose TuneTables, a novel prompt-tuning strategy that compresses large datasets into a smaller learned context. TuneTables scales TabPFN to be competitive with state-of-the-art tabular classification methods on larger datasets, while having a substantially lower inference time than TabPFN. Furthermore, we show that TuneTables can be used as an interpretability tool and can even be used to mitigate biases by optimizing a fairness objective.
Deep Riemannian Networks for EEG Decoding
Dec 21, 2022State-of-the-art performance in electroencephalography (EEG) decoding tasks is currently often achieved with either Deep-Learning or Riemannian-Geometry-based decoders. Recently, there is growing interest in Deep Riemannian Networks (DRNs) possibly combining the advantages of both previous classes of methods. However, there are still a range of topics where additional insight is needed to pave the way for a more widespread application of DRNs in EEG. These include architecture design questions such as network size and end-to-end ability as well as model training questions. How these factors affect model performance has not been explored. Additionally, it is not clear how the data within these networks is transformed, and whether this would correlate with traditional EEG decoding. Our study aims to lay the groundwork in the area of these topics through the analysis of DRNs for EEG with a wide range of hyperparameters. Networks were tested on two public EEG datasets and compared with state-of-the-art ConvNets. Here we propose end-to-end EEG SPDNet (EE(G)-SPDNet), and we show that this wide, end-to-end DRN can outperform the ConvNets, and in doing so use physiologically plausible frequency regions. We also show that the end-to-end approach learns more complex filters than traditional band-pass filters targeting the classical alpha, beta, and gamma frequency bands of the EEG, and that performance can benefit from channel specific filtering approaches. Additionally, architectural analysis revealed areas for further improvement due to the possible loss of Riemannian specific information throughout the network. Our study thus shows how to design and train DRNs to infer task-related information from the raw EEG without the need of handcrafted filterbanks and highlights the potential of end-to-end DRNs such as EE(G)-SPDNet for high-performance EEG decoding.
On the Importance of Hyperparameters and Data Augmentation for Self-Supervised Learning
Jul 16, 2022
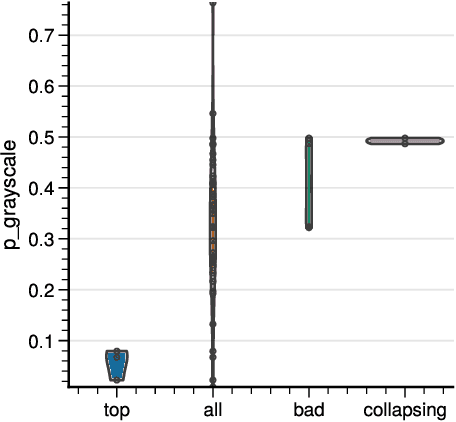
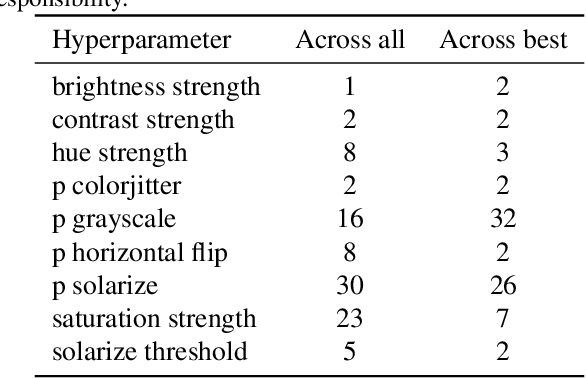
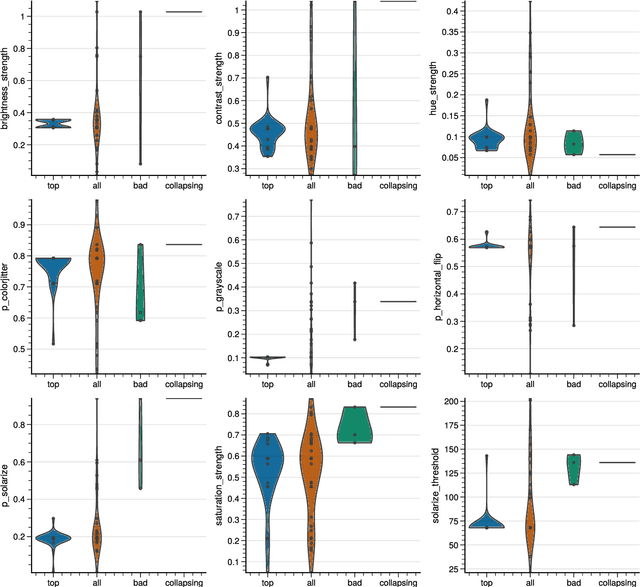
Self-Supervised Learning (SSL) has become a very active area of Deep Learning research where it is heavily used as a pre-training method for classification and other tasks. However, the rapid pace of advancements in this area comes at a price: training pipelines vary significantly across papers, which presents a potentially crucial confounding factor. Here, we show that, indeed, the choice of hyperparameters and data augmentation strategies can have a dramatic impact on performance. To shed light on these neglected factors and help maximize the power of SSL, we hyperparameterize these components and optimize them with Bayesian optimization, showing improvements across multiple datasets for the SimSiam SSL approach. Realizing the importance of data augmentations for SSL, we also introduce a new automated data augmentation algorithm, GroupAugment, which considers groups of augmentations and optimizes the sampling across groups. In contrast to algorithms designed for supervised learning, GroupAugment achieved consistently high linear evaluation accuracy across all datasets we considered. Overall, our results indicate the importance and likely underestimated role of data augmentation for SSL.
When less is more: Simplifying inputs aids neural network understanding
Feb 01, 2022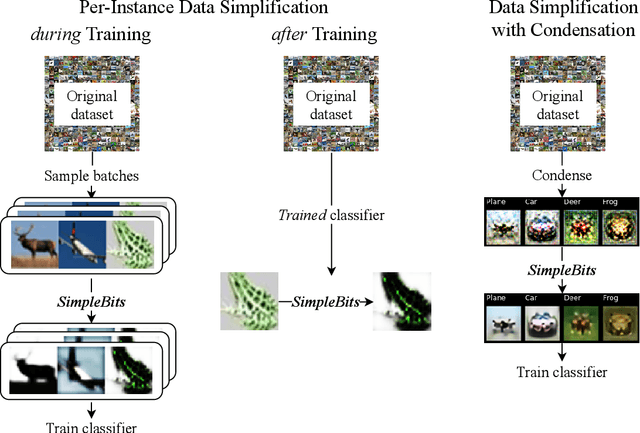

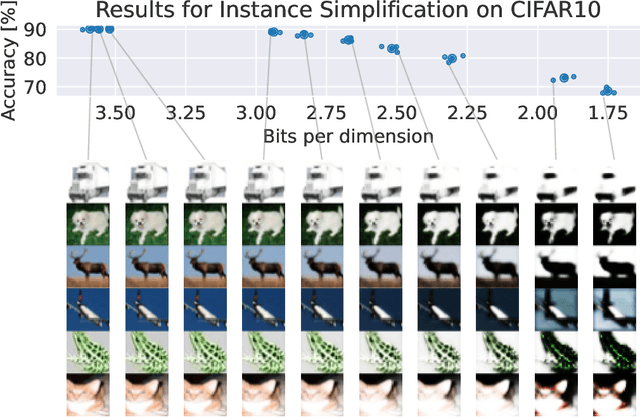
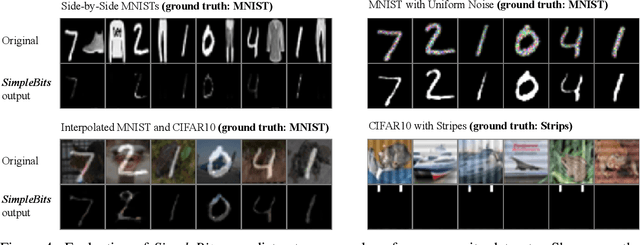
How do neural network image classifiers respond to simpler and simpler inputs? And what do such responses reveal about the learning process? To answer these questions, we need a clear measure of input simplicity (or inversely, complexity), an optimization objective that correlates with simplification, and a framework to incorporate such objective into training and inference. Lastly we need a variety of testbeds to experiment and evaluate the impact of such simplification on learning. In this work, we measure simplicity with the encoding bit size given by a pretrained generative model, and minimize the bit size to simplify inputs in training and inference. We investigate the effect of such simplification in several scenarios: conventional training, dataset condensation and post-hoc explanations. In all settings, inputs are simplified along with the original classification task, and we investigate the trade-off between input simplicity and task performance. For images with injected distractors, such simplification naturally removes superfluous information. For dataset condensation, we find that inputs can be simplified with almost no accuracy degradation. When used in post-hoc explanation, our learning-based simplification approach offers a valuable new tool to explore the basis of network decisions.
Understanding Anomaly Detection with Deep Invertible Networks through Hierarchies of Distributions and Features
Jun 25, 2020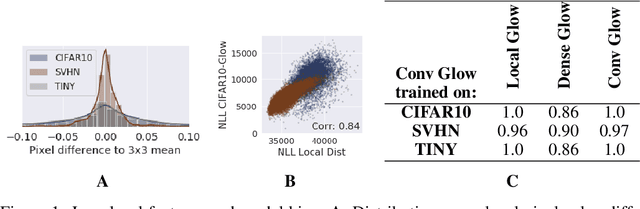
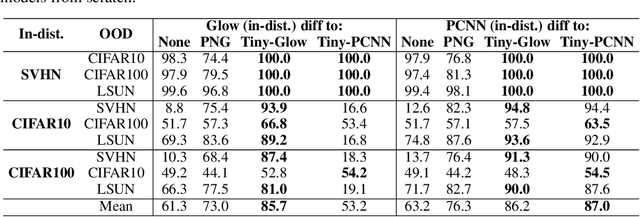
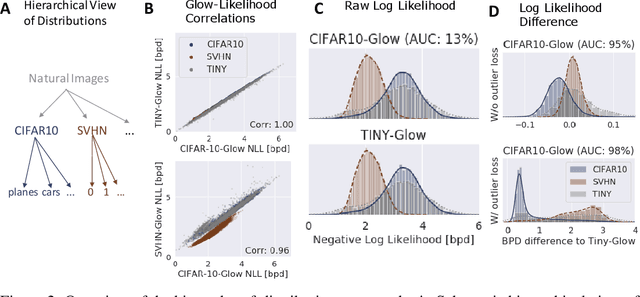
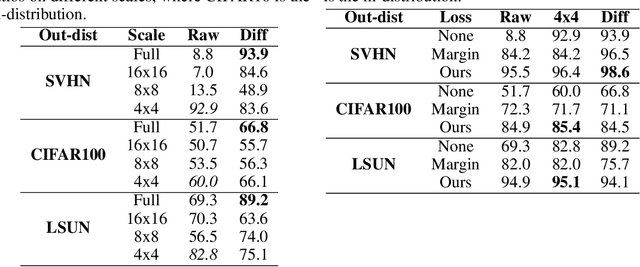
Deep generative networks trained via maximum likelihood on a natural image dataset like CIFAR10 often assign high likelihoods to images from datasets with different objects (e.g., SVHN). We refine previous investigations of this failure at anomaly detection for invertible generative networks and provide a clear explanation of it as a combination of model bias and domain prior: Convolutional networks learn similar low-level feature distributions when trained on any natural image dataset and these low-level features dominate the likelihood. Hence, when the discriminative features between inliers and outliers are on a high-level, e.g., object shapes, anomaly detection becomes particularly challenging. To remove the negative impact of model bias and domain prior on detecting high-level differences, we propose two methods, first, using the log likelihood ratios of two identical models, one trained on the in-distribution data (e.g., CIFAR10) and the other one on a more general distribution of images (e.g., 80 Million Tiny Images). We also derive a novel outlier loss for the in-distribution network on samples from the more general distribution to further improve the performance. Secondly, using a multi-scale model like Glow, we show that low-level features are mainly captured at early scales. Therefore, using only the likelihood contribution of the final scale performs remarkably well for detecting high-level feature differences of the out-of-distribution and the in-distribution. This method is especially useful if one does not have access to a suitable general distribution. Overall, our methods achieve strong anomaly detection performance in the unsupervised setting, reaching comparable performance as state-of-the-art classifier-based methods in the supervised setting.
Machine-Learning-Based Diagnostics of EEG Pathology
Feb 11, 2020
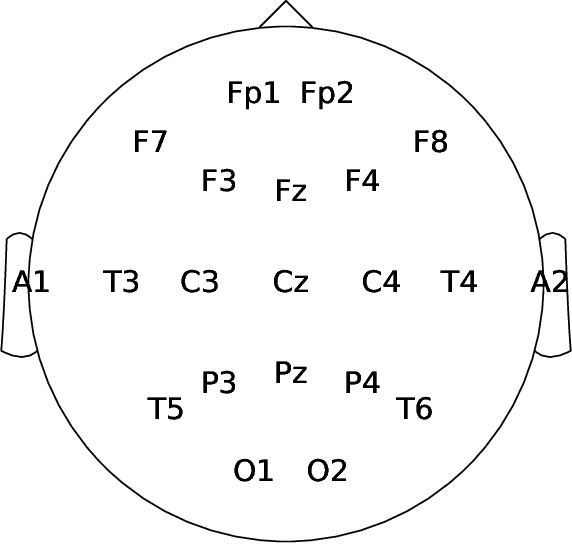

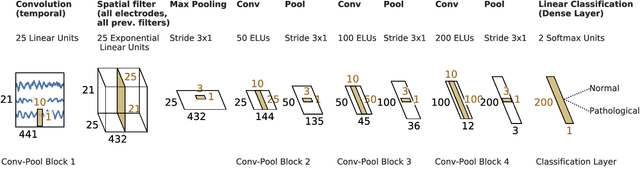
Machine learning (ML) methods have the potential to automate clinical EEG analysis. They can be categorized into feature-based (with handcrafted features), and end-to-end approaches (with learned features). Previous studies on EEG pathology decoding have typically analyzed a limited number of features, decoders, or both. For a I) more elaborate feature-based EEG analysis, and II) in-depth comparisons of both approaches, here we first develop a comprehensive feature-based framework, and then compare this framework to state-of-the-art end-to-end methods. To this aim, we apply the proposed feature-based framework and deep neural networks including an EEG-optimized temporal convolutional network (TCN) to the task of pathological versus non-pathological EEG classification. For a robust comparison, we chose the Temple University Hospital (TUH) Abnormal EEG Corpus (v2.0.0), which contains approximately 3000 EEG recordings. The results demonstrate that the proposed feature-based decoding framework can achieve accuracies on the same level as state-of-the-art deep neural networks. We find accuracies across both approaches in an astonishingly narrow range from 81--86\%. Moreover, visualizations and analyses indicated that both approaches used similar aspects of the data, e.g., delta and theta band power at temporal electrode locations. We argue that the accuracies of current binary EEG pathology decoders could saturate near 90\% due to the imperfect inter-rater agreement of the clinical labels, and that such decoders are already clinically useful, such as in areas where clinical EEG experts are rare. We make the proposed feature-based framework available open source and thus offer a new tool for EEG machine learning research.
Deep Invertible Networks for EEG-based brain-signal decoding
Jul 17, 2019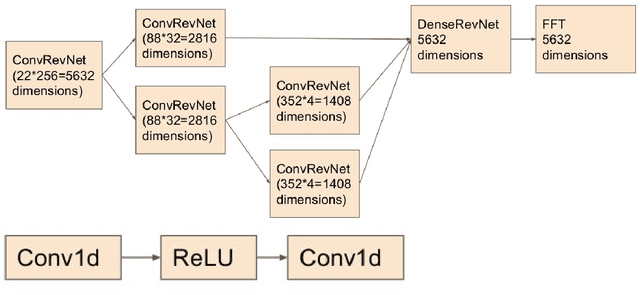
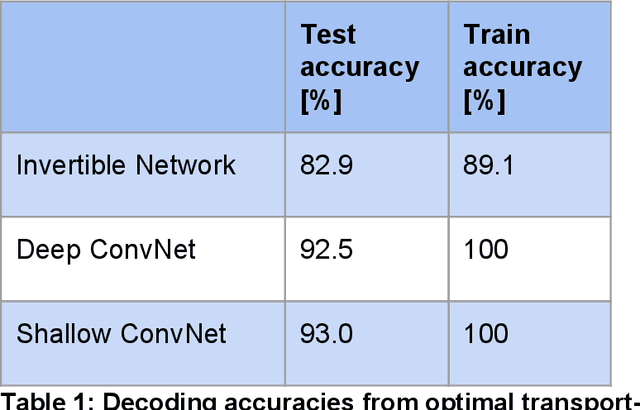
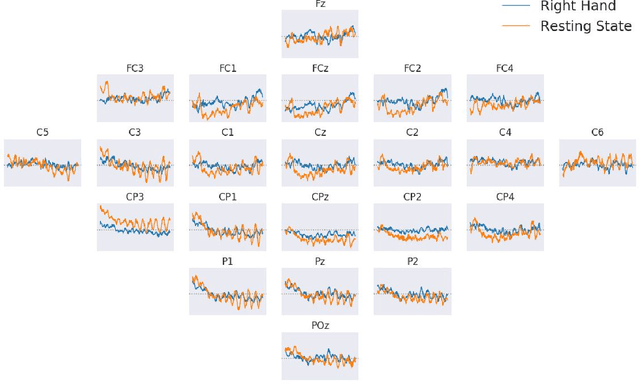
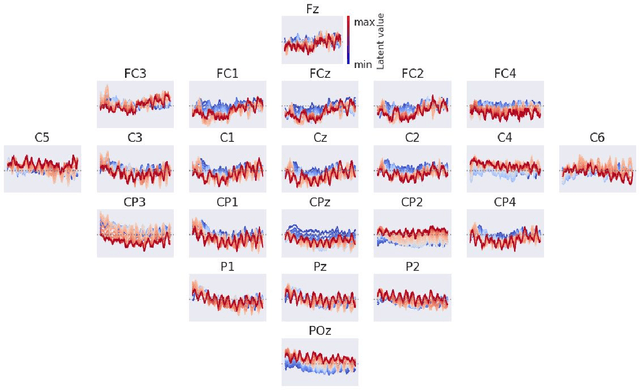
In this manuscript, we investigate deep invertible networks for EEG-based brain signal decoding and find them to generate realistic EEG signals as well as classify novel signals above chance. Further ideas for their regularization towards better decoding accuracies are discussed.
Training Generative Reversible Networks
Aug 23, 2018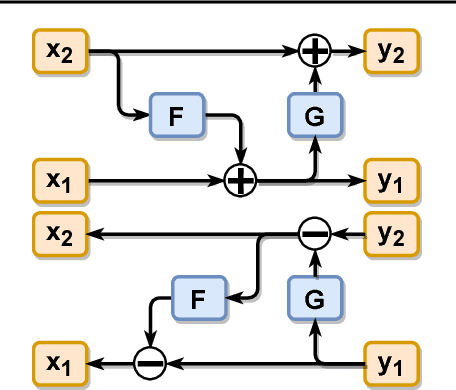


Generative models with an encoding component such as autoencoders currently receive great interest. However, training of autoencoders is typically complicated by the need to train a separate encoder and decoder model that have to be enforced to be reciprocal to each other. To overcome this problem, by-design reversible neural networks (RevNets) had been previously used as generative models either directly optimizing the likelihood of the data under the model or using an adversarial approach on the generated data. Here, we instead investigate their performance using an adversary on the latent space in the adversarial autoencoder framework. We investigate the generative performance of RevNets on the CelebA dataset, showing that generative RevNets can generate coherent faces with similar quality as Variational Autoencoders. This first attempt to use RevNets inside the adversarial autoencoder framework slightly underperformed relative to recent advanced generative models using an autoencoder component on CelebA, but this gap may diminish with further optimization of the training setup of generative RevNets. In addition to the experiments on CelebA, we show a proof-of-principle experiment on the MNIST dataset suggesting that adversary-free trained RevNets can discover meaningful latent dimensions without pre-specifying the number of dimensions of the latent sampling distribution. In summary, this study shows that RevNets can be employed in different generative training settings. Source code for this study is at https://github.com/robintibor/generative-reversible
Acting Thoughts: Towards a Mobile Robotic Service Assistant for Users with Limited Communication Skills
Jun 12, 2018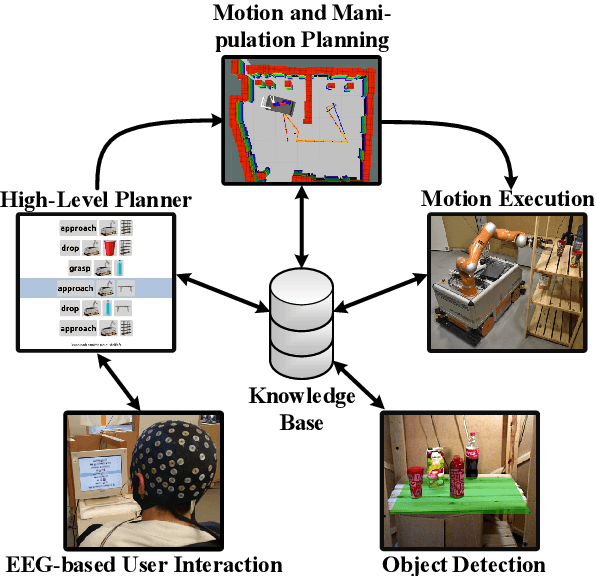
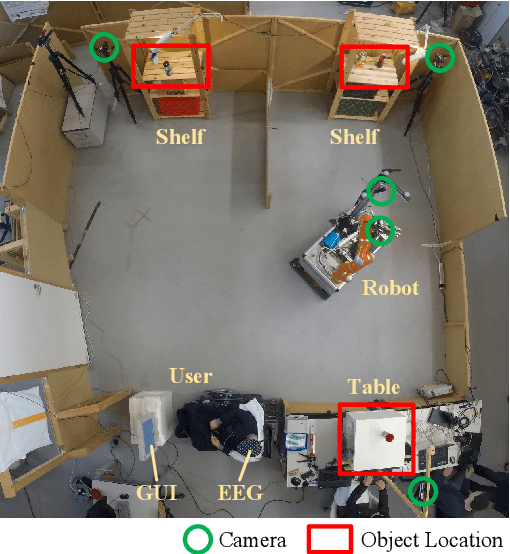
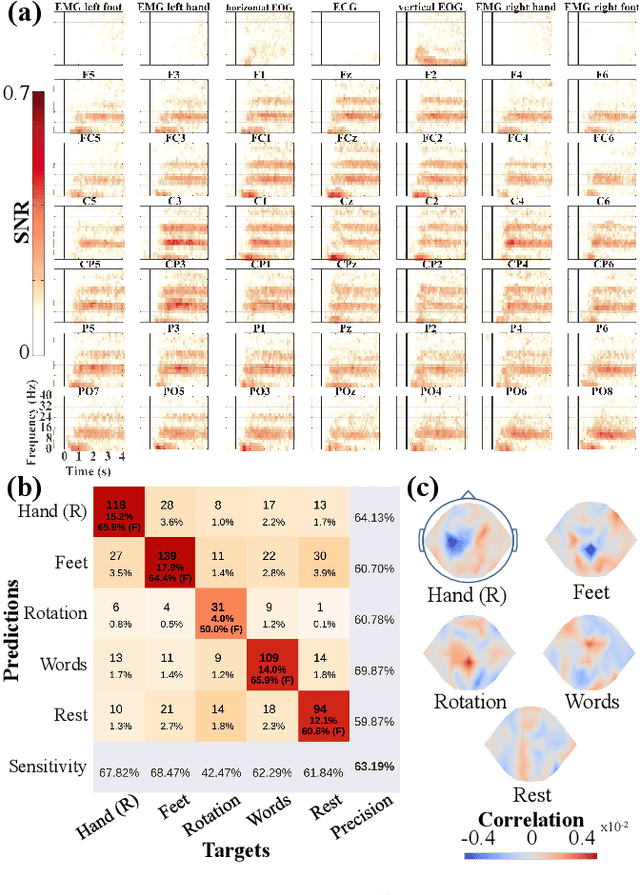
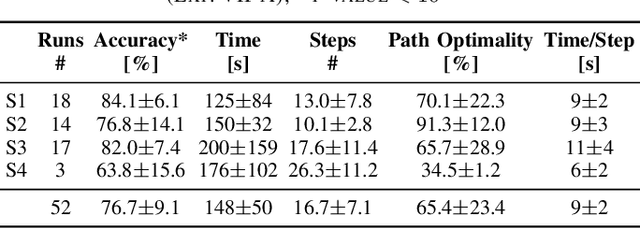
As autonomous service robots become more affordable and thus available also for the general public, there is a growing need for user friendly interfaces to control the robotic system. Currently available control modalities typically expect users to be able to express their desire through either touch, speech or gesture commands. While this requirement is fulfilled for the majority of users, paralyzed users may not be able to use such systems. In this paper, we present a novel framework, that allows these users to interact with a robotic service assistant in a closed-loop fashion, using only thoughts. The brain-computer interface (BCI) system is composed of several interacting components, i.e., non-invasive neuronal signal recording and decoding, high-level task planning, motion and manipulation planning as well as environment perception. In various experiments, we demonstrate its applicability and robustness in real world scenarios, considering fetch-and-carry tasks and tasks involving human-robot interaction. As our results demonstrate, our system is capable of adapting to frequent changes in the environment and reliably completing given tasks within a reasonable amount of time. Combined with high-level planning and autonomous robotic systems, interesting new perspectives open up for non-invasive BCI-based human-robot interactions.
* * FB, LDJF, DK, MV and JA contributed equally to the work. Accepted as a conference paper at the European Conference on Mobile Robotics 2017 (ECMR 2017), 6 pages, 3 figures