 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning and Synthetic Data for Automated Pretraining and Finetuning
Jun 11, 2025The growing number of pretrained models in Machine Learning (ML) presents significant challenges for practitioners. Given a new dataset, they need to determine the most suitable deep learning (DL) pipeline, consisting of the pretrained model and the hyperparameters for finetuning to it. Moreover, as models grow in scale, the increasing reliance on real-world data poses a bottleneck for training and requires leveraging data more effectively. Addressing the first challenge often involves manual model selection and hyperparameter tuning. At the same time, as models grow larger and more and more of the available human-generated data is being used for training, data augmentation and synthetic data become critical elements. Automated machine learning offers a path to address these challenges but is traditionally designed for tabular data and classical ML methods. This dissertation adopts meta-learning to extend automated machine learning to the deep learning domain. We propose empirical approaches to automate DL pipeline selection for Computer Vision tasks using prior task knowledge to learn surrogate models for pipeline ranking. Extending these methods to the language domain, we learn to finetune large language models. As a result, we show that our approach can outperform finetuning foundation models. Additionally, we meta-learn data augmentation and synthetic data to enhance performance in up-stream and down-stream tasks. We empirically show the underestimated importance of data augmentation when using Self-Supervised Learning and meta-learn advanced data augmentation strategies. Leveraging synthetic data, we also propose to meta-learn neural synthetic data generators as proxies for Reinforcement Learning (RL) environments. Additionally, we learn a multiple-environment world model in an in-context learning fashion by purely using synthetic, randomly sampled data.
Improving LLM-based Global Optimization with Search Space Partitioning
May 27, 2025Large Language Models (LLMs) have recently emerged as effective surrogate models and candidate generators within global optimization frameworks for expensive blackbox functions. Despite promising results, LLM-based methods often struggle in high-dimensional search spaces or when lacking domain-specific priors, leading to sparse or uninformative suggestions. To overcome these limitations, we propose HOLLM, a novel global optimization algorithm that enhances LLM-driven sampling by partitioning the search space into promising subregions. Each subregion acts as a ``meta-arm'' selected via a bandit-inspired scoring mechanism that effectively balances exploration and exploitation. Within each selected subregion, an LLM then proposes high-quality candidate points, without any explicit domain knowledge. Empirical evaluation on standard optimization benchmarks shows that HOLLM consistently matches or surpasses leading Bayesian optimization and trust-region methods, while substantially outperforming global LLM-based sampling strategies.
Transfer Learning for Finetuning Large Language Models
Nov 02, 2024



As the landscape of large language models expands, efficiently finetuning for specific tasks becomes increasingly crucial. At the same time, the landscape of parameter-efficient finetuning methods rapidly expands. Consequently, practitioners face a multitude of complex choices when searching for an optimal finetuning pipeline for large language models. To reduce the complexity for practitioners, we investigate transfer learning for finetuning large language models and aim to transfer knowledge about configurations from related finetuning tasks to a new task. In this work, we transfer learn finetuning by meta-learning performance and cost surrogate models for grey-box meta-optimization from a new meta-dataset. Counter-intuitively, we propose to rely only on transfer learning for new datasets. Thus, we do not use task-specific Bayesian optimization but prioritize knowledge transferred from related tasks over task-specific feedback. We evaluate our method on eight synthetic question-answer datasets and a meta-dataset consisting of 1,800 runs of finetuning Microsoft's Phi-3. Our transfer learning is superior to zero-shot, default finetuning, and meta-optimization baselines. Our results demonstrate the transferability of finetuning to adapt large language models more effectively.
One-shot World Models Using a Transformer Trained on a Synthetic Prior
Sep 21, 2024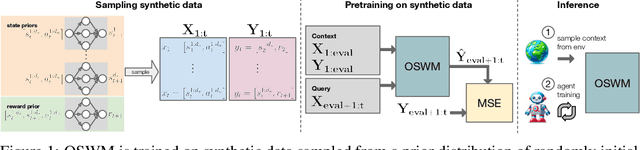

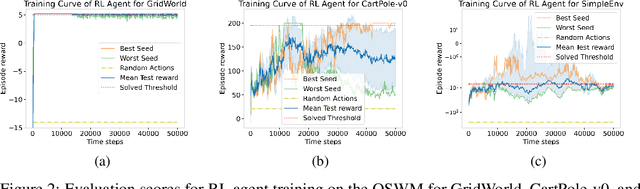

A World Model is a compressed spatial and temporal representation of a real world environment that allows one to train an agent or execute planning methods. However, world models are typically trained on observations from the real world environment, and they usually do not enable learning policies for other real environments. We propose One-Shot World Model (OSWM), a transformer world model that is learned in an in-context learning fashion from purely synthetic data sampled from a prior distribution. Our prior is composed of multiple randomly initialized neural networks, where each network models the dynamics of each state and reward dimension of a desired target environment. We adopt the supervised learning procedure of Prior-Fitted Networks by masking next-state and reward at random context positions and query OSWM to make probabilistic predictions based on the remaining transition context. During inference time, OSWM is able to quickly adapt to the dynamics of a simple grid world, as well as the CartPole gym and a custom control environment by providing 1k transition steps as context and is then able to successfully train environment-solving agent policies. However, transferring to more complex environments remains a challenge, currently. Despite these limitations, we see this work as an important stepping-stone in the pursuit of learning world models purely from synthetic data.
Hard View Selection for Contrastive Learning
Oct 05, 2023Many Contrastive Learning (CL) methods train their models to be invariant to different "views" of an image input for which a good data augmentation pipeline is crucial. While considerable efforts were directed towards improving pre-text tasks, architectures, or robustness (e.g., Siamese networks or teacher-softmax centering), the majority of these methods remain strongly reliant on the random sampling of operations within the image augmentation pipeline, such as the random resized crop or color distortion operation. In this paper, we argue that the role of the view generation and its effect on performance has so far received insufficient attention. To address this, we propose an easy, learning-free, yet powerful Hard View Selection (HVS) strategy designed to extend the random view generation to expose the pretrained model to harder samples during CL training. It encompasses the following iterative steps: 1) randomly sample multiple views and create pairs of two views, 2) run forward passes for each view pair on the currently trained model, 3) adversarially select the pair yielding the worst loss, and 4) run the backward pass with the selected pair. In our empirical analysis we show that under the hood, HVS increases task difficulty by controlling the Intersection over Union of views during pretraining. With only 300-epoch pretraining, HVS is able to closely rival the 800-epoch DINO baseline which remains very favorable even when factoring in the slowdown induced by the additional forwards of HVS. Additionally, HVS consistently achieves accuracy improvements on ImageNet between 0.55% and 1.9% on linear evaluation and similar improvements on transfer tasks across multiple CL methods, such as DINO, SimSiam, and SimCLR.
Quick-Tune: Quickly Learning Which Pretrained Model to Finetune and How
Jun 11, 2023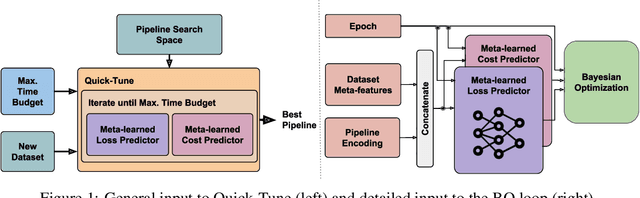
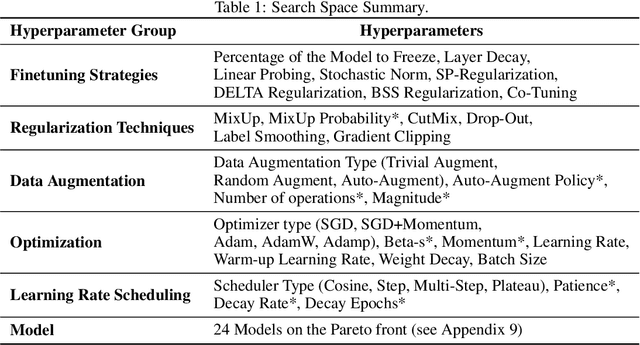
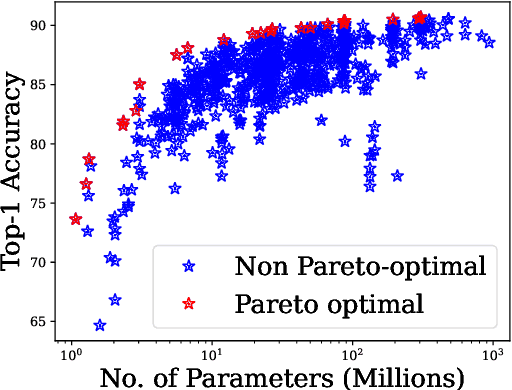

With the ever-increasing number of pretrained models, machine learning practitioners are continuously faced with which pretrained model to use, and how to finetune it for a new dataset. In this paper, we propose a methodology that jointly searches for the optimal pretrained model and the hyperparameters for finetuning it. Our method transfers knowledge about the performance of many pretrained models with multiple hyperparameter configurations on a series of datasets. To this aim, we evaluated over 20k hyperparameter configurations for finetuning 24 pretrained image classification models on 87 datasets to generate a large-scale meta-dataset. We meta-learn a multi-fidelity performance predictor on the learning curves of this meta-dataset and use it for fast hyperparameter optimization on new datasets. We empirically demonstrate that our resulting approach can quickly select an accurate pretrained model for a new dataset together with its optimal hyperparameters.
On the Importance of Hyperparameters and Data Augmentation for Self-Supervised Learning
Jul 16, 2022
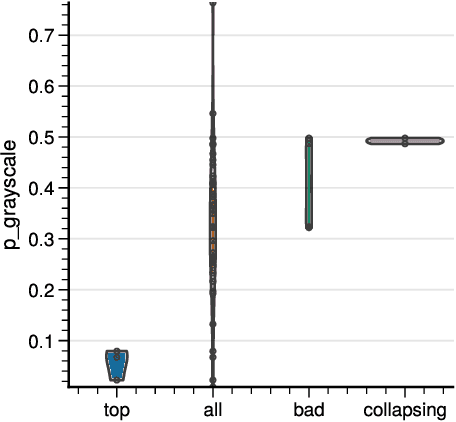
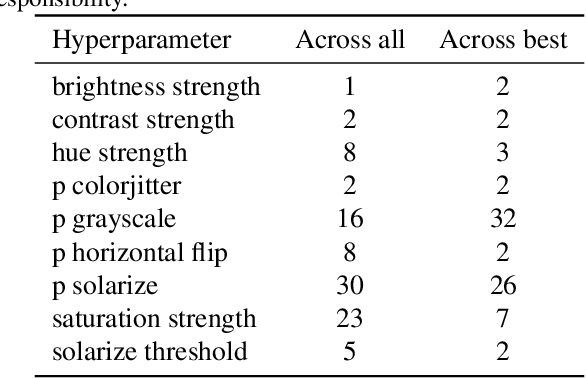
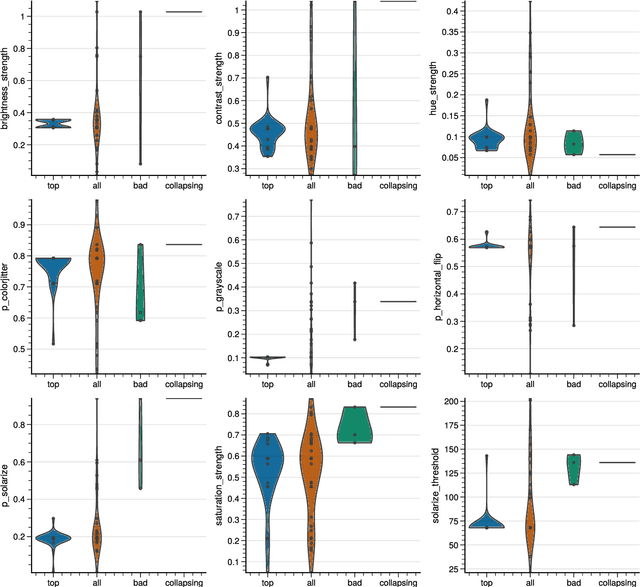
Self-Supervised Learning (SSL) has become a very active area of Deep Learning research where it is heavily used as a pre-training method for classification and other tasks. However, the rapid pace of advancements in this area comes at a price: training pipelines vary significantly across papers, which presents a potentially crucial confounding factor. Here, we show that, indeed, the choice of hyperparameters and data augmentation strategies can have a dramatic impact on performance. To shed light on these neglected factors and help maximize the power of SSL, we hyperparameterize these components and optimize them with Bayesian optimization, showing improvements across multiple datasets for the SimSiam SSL approach. Realizing the importance of data augmentations for SSL, we also introduce a new automated data augmentation algorithm, GroupAugment, which considers groups of augmentations and optimizes the sampling across groups. In contrast to algorithms designed for supervised learning, GroupAugment achieved consistently high linear evaluation accuracy across all datasets we considered. Overall, our results indicate the importance and likely underestimated role of data augmentation for SSL.
Zero-Shot AutoML with Pretrained Models
Jun 25, 2022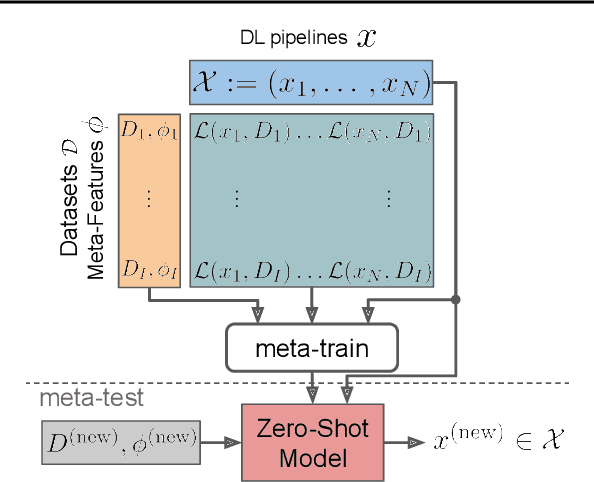
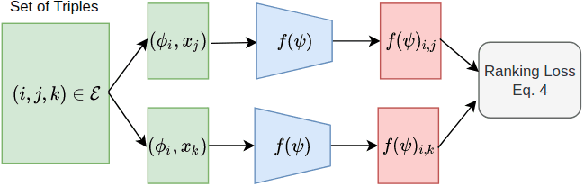

Given a new dataset D and a low compute budget, how should we choose a pre-trained model to fine-tune to D, and set the fine-tuning hyperparameters without risking overfitting, particularly if D is small? Here, we extend automated machine learning (AutoML) to best make these choices. Our domain-independent meta-learning approach learns a zero-shot surrogate model which, at test time, allows to select the right deep learning (DL) pipeline (including the pre-trained model and fine-tuning hyperparameters) for a new dataset D given only trivial meta-features describing D such as image resolution or the number of classes. To train this zero-shot model, we collect performance data for many DL pipelines on a large collection of datasets and meta-train on this data to minimize a pairwise ranking objective. We evaluate our approach under the strict time limit of the vision track of the ChaLearn AutoDL challenge benchmark, clearly outperforming all challenge contenders.
Lessons learned from the NeurIPS 2021 MetaDL challenge: Backbone fine-tuning without episodic meta-learning dominates for few-shot learning image classification
Jun 15, 2022

Although deep neural networks are capable of achieving performance superior to humans on various tasks, they are notorious for requiring large amounts of data and computing resources, restricting their success to domains where such resources are available. Metalearning methods can address this problem by transferring knowledge from related tasks, thus reducing the amount of data and computing resources needed to learn new tasks. We organize the MetaDL competition series, which provide opportunities for research groups all over the world to create and experimentally assess new meta-(deep)learning solutions for real problems. In this paper, authored collaboratively between the competition organizers and the top-ranked participants, we describe the design of the competition, the datasets, the best experimental results, as well as the top-ranked methods in the NeurIPS 2021 challenge, which attracted 15 active teams who made it to the final phase (by outperforming the baseline), making over 100 code submissions during the feedback phase. The solutions of the top participants have been open-sourced. The lessons learned include that learning good representations is essential for effective transfer learning.
Learning Synthetic Environments and Reward Networks for Reinforcement Learning
Feb 06, 2022

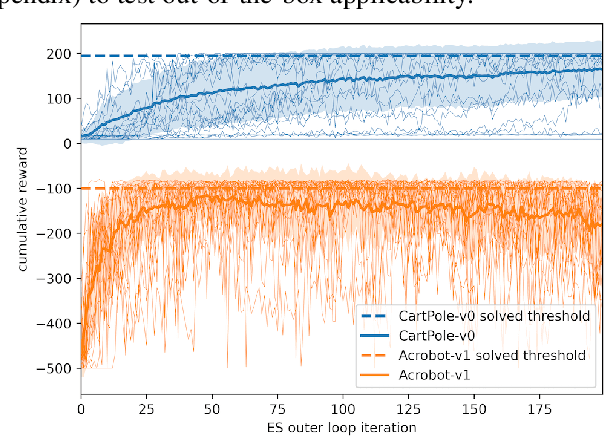

We introduce Synthetic Environments (SEs) and Reward Networks (RNs), represented by neural networks, as proxy environment models for training Reinforcement Learning (RL) agents. We show that an agent, after being trained exclusively on the SE, is able to solve the corresponding real environment. While an SE acts as a full proxy to a real environment by learning about its state dynamics and rewards, an RN is a partial proxy that learns to augment or replace rewards. We use bi-level optimization to evolve SEs and RNs: the inner loop trains the RL agent, and the outer loop trains the parameters of the SE / RN via an evolution strategy. We evaluate our proposed new concept on a broad range of RL algorithms and classic control environments. In a one-to-one comparison, learning an SE proxy requires more interactions with the real environment than training agents only on the real environment. However, once such an SE has been learned, we do not need any interactions with the real environment to train new agents. Moreover, the learned SE proxies allow us to train agents with fewer interactions while maintaining the original task performance. Our empirical results suggest that SEs achieve this result by learning informed representations that bias the agents towards relevant states. Moreover, we find that these proxies are robust against hyperparameter variation and can also transfer to unseen agents.