 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot AutoML with Pretrained Models
Jun 25, 2022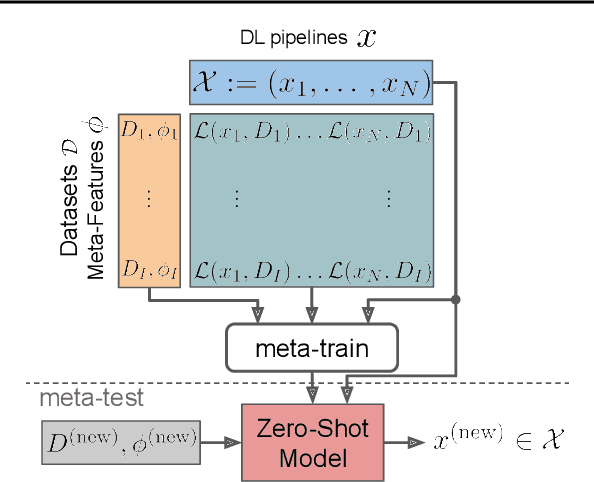
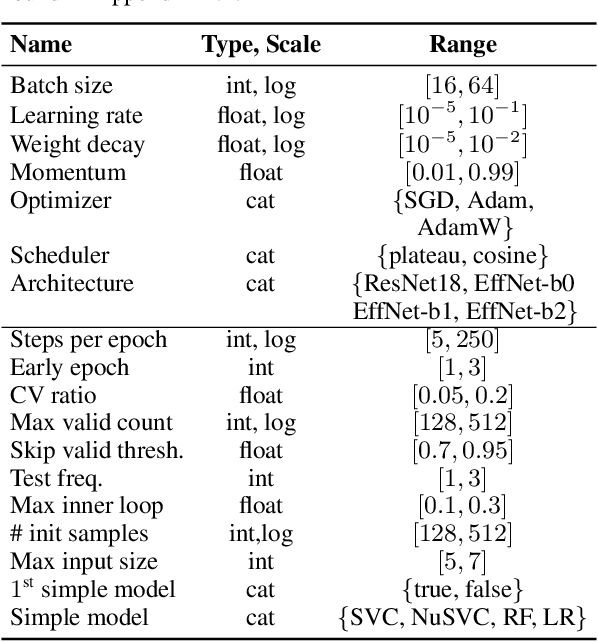

Given a new dataset D and a low compute budget, how should we choose a pre-trained model to fine-tune to D, and set the fine-tuning hyperparameters without risking overfitting, particularly if D is small? Here, we extend automated machine learning (AutoML) to best make these choices. Our domain-independent meta-learning approach learns a zero-shot surrogate model which, at test time, allows to select the right deep learning (DL) pipeline (including the pre-trained model and fine-tuning hyperparameters) for a new dataset D given only trivial meta-features describing D such as image resolution or the number of classes. To train this zero-shot model, we collect performance data for many DL pipelines on a large collection of datasets and meta-train on this data to minimize a pairwise ranking objective. We evaluate our approach under the strict time limit of the vision track of the ChaLearn AutoDL challenge benchmark, clearly outperforming all challenge contenders.
Improving Hyperparameter Optimization by Planning Ahead
Oct 15, 2021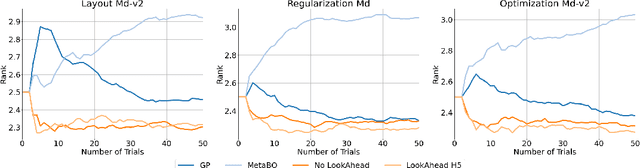
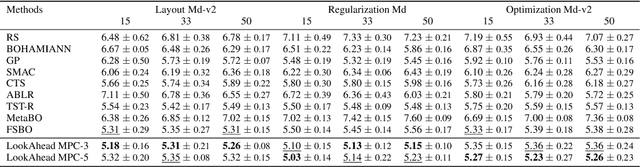
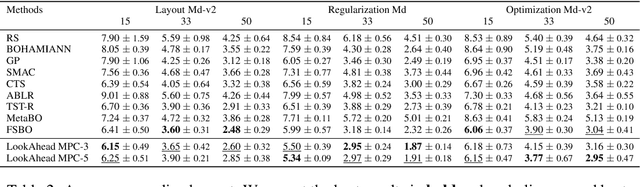

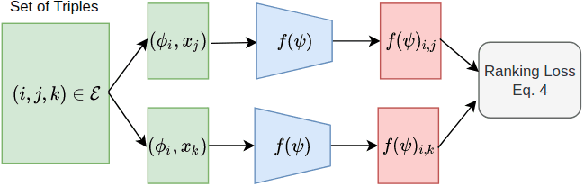
Hyperparameter optimization (HPO) is generally treated as a bi-level optimization problem that involves fitting a (probabilistic) surrogate model to a set of observed hyperparameter responses, e.g. validation loss, and consequently maximizing an acquisition function using a surrogate model to identify good hyperparameter candidates for evaluation. The choice of a surrogate and/or acquisition function can be further improved via knowledge transfer across related tasks. In this paper, we propose a novel transfer learning approach, defined within the context of model-based reinforcement learning, where we represent the surrogate as an ensemble of probabilistic models that allows trajectory sampling. We further propose a new variant of model predictive control which employs a simple look-ahead strategy as a policy that optimizes a sequence of actions, representing hyperparameter candidates to expedite HPO. Our experiments on three meta-datasets comparing to state-of-the-art HPO algorithms including a model-free reinforcement learning approach show that the proposed method can outperform all baselines by exploiting a simple planning-based policy.
HPO-B: A Large-Scale Reproducible Benchmark for Black-Box HPO based on OpenML
Jun 11, 2021
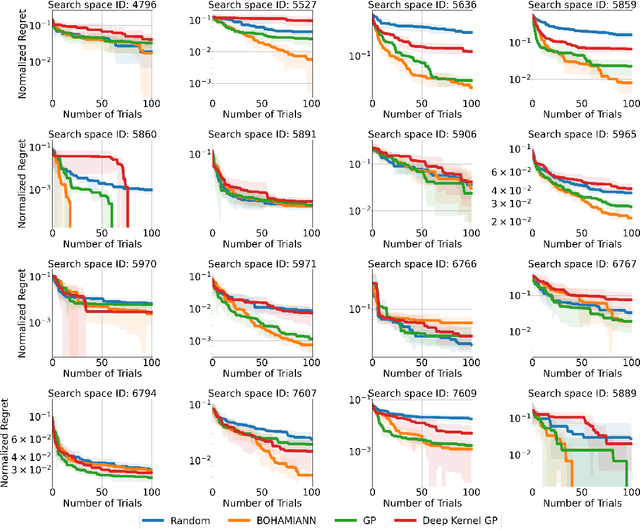
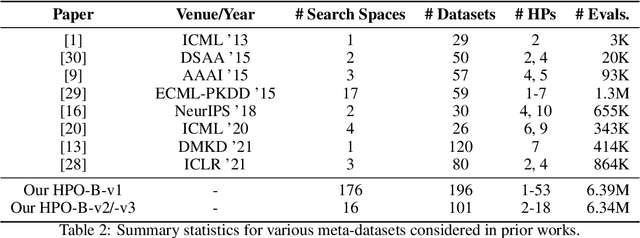
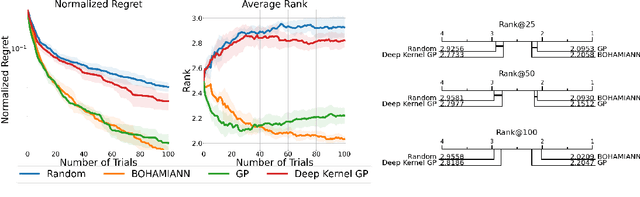
Hyperparameter optimization (HPO) is a core problem for the machine learning community and remains largely unsolved due to the significant computational resources required to evaluate hyperparameter configurations. As a result, a series of recent related works have focused on the direction of transfer learning for quickly fine-tuning hyperparameters on a dataset. Unfortunately, the community does not have a common large-scale benchmark for comparing HPO algorithms. Instead, the de facto practice consists of empirical protocols on arbitrary small-scale meta-datasets that vary inconsistently across publications, making reproducibility a challenge. To resolve this major bottleneck and enable a fair and fast comparison of black-box HPO methods on a level playing field, we propose HPO-B, a new large-scale benchmark in the form of a collection of meta-datasets. Our benchmark is assembled and preprocessed from the OpenML repository and consists of 176 search spaces (algorithms) evaluated sparsely on 196 datasets with a total of 6.4 million hyperparameter evaluations. For ensuring reproducibility on our benchmark, we detail explicit experimental protocols, splits, and evaluation measures for comparing methods for both non-transfer, as well as, transfer learning HPO.
Hyperparameter Optimization with Differentiable Metafeatures
Feb 07, 2021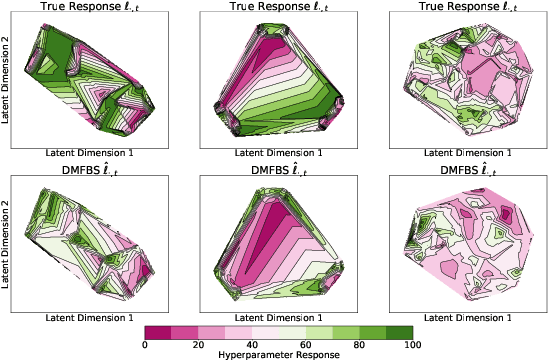


Metafeatures, or dataset characteristics, have been shown to improve the performance of hyperparameter optimization (HPO). Conventionally, metafeatures are precomputed and used to measure the similarity between datasets, leading to a better initialization of HPO models. In this paper, we propose a cross dataset surrogate model called Differentiable Metafeature-based Surrogate (DMFBS), that predicts the hyperparameter response, i.e. validation loss, of a model trained on the dataset at hand. In contrast to existing models, DMFBS i) integrates a differentiable metafeature extractor and ii) is optimized using a novel multi-task loss, linking manifold regularization with a dataset similarity measure learned via an auxiliary dataset identification meta-task, effectively enforcing the response approximation for similar datasets to be similar. We compare DMFBS against several recent models for HPO on three large meta-datasets and show that it consistently outperforms all of them with an average 10% improvement. Finally, we provide an extensive ablation study that examines the different components of our approach.
Hyp-RL : Hyperparameter Optimization by Reinforcement Learning
Jun 27, 2019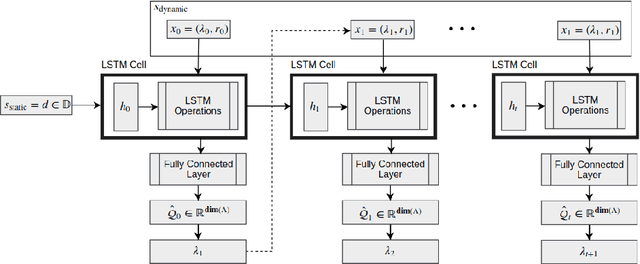

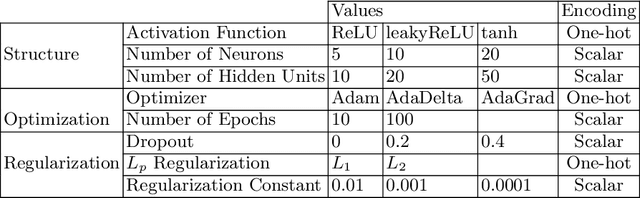
Hyperparameter tuning is an omnipresent problem in machine learning as it is an integral aspect of obtaining the state-of-the-art performance for any model. Most often, hyperparameters are optimized just by training a model on a grid of possible hyperparameter values and taking the one that performs best on a validation sample (grid search). More recently, methods have been introduced that build a so-called surrogate model that predicts the validation loss for a specific hyperparameter setting, model and dataset and then sequentially select the next hyperparameter to test, based on a heuristic function of the expected value and the uncertainty of the surrogate model called acquisition function (sequential model-based Bayesian optimization, SMBO). In this paper we model the hyperparameter optimization problem as a sequential decision problem, which hyperparameter to test next, and address it with reinforcement learning. This way our model does not have to rely on a heuristic acquisition function like SMBO, but can learn which hyperparameters to test next based on the subsequent reduction in validation loss they will eventually lead to, either because they yield good models themselves or because they allow the hyperparameter selection policy to build a better surrogate model that is able to choose better hyperparameters later on. Experiments on a large battery of 50 data sets demonstrate that our method outperforms the state-of-the-art approaches for hyperparameter learning.
In Hindsight: A Smooth Reward for Steady Exploration
Jun 24, 2019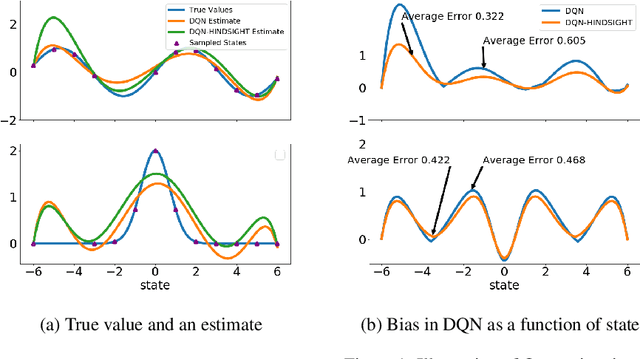
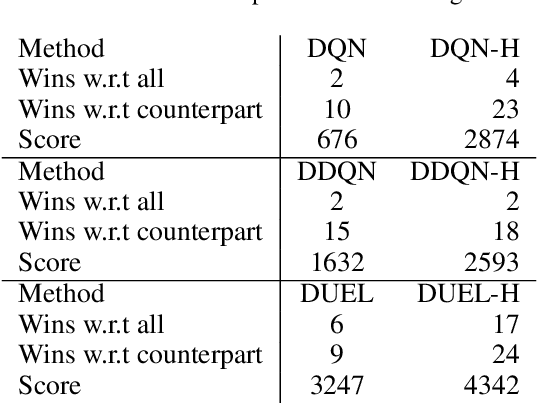
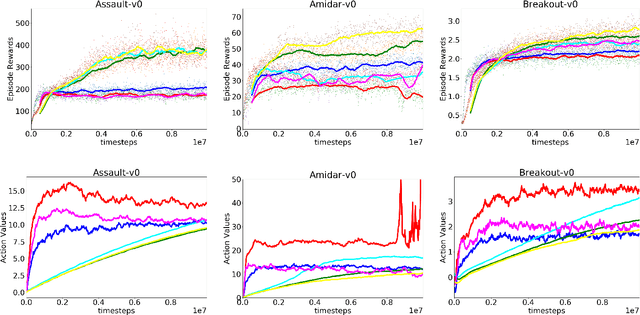
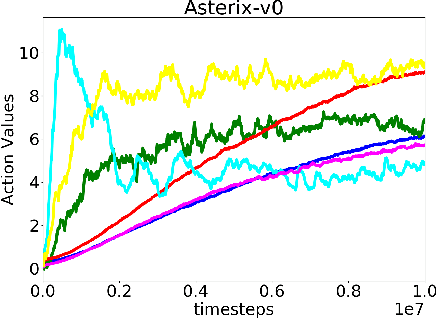
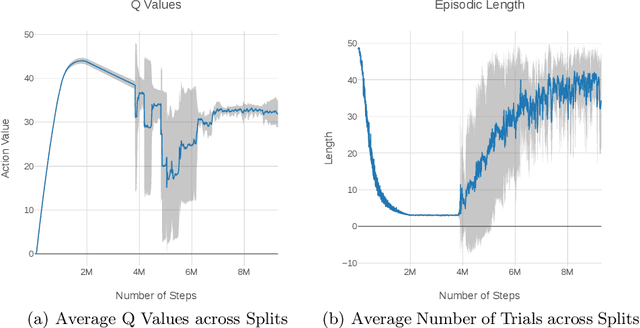
In classical Q-learning, the objective is to maximize the sum of discounted rewards through iteratively using the Bellman equation as an update, in an attempt to estimate the action value function of the optimal policy. Conventionally, the loss function is defined as the temporal difference between the action value and the expected (discounted) reward, however it focuses solely on the future, leading to overestimation errors. We extend the well-established Q-learning techniques by introducing the hindsight factor, an additional loss term that takes into account how the model progresses, by integrating the historic temporal difference as part of the reward. The effect of this modification is examined in a deterministic continuous-state space function estimation problem, where the overestimation phenomenon is significantly reduced and results in improved stability. The underlying effect of the hindsight factor is modeled as an adaptive learning rate, which unlike existing adaptive optimizers, takes into account the previously estimated action value. The proposed method outperforms variations of Q-learning, with an overall higher average reward and lower action values, which supports the deterministic evaluation, and proves that the hindsight factor contributes to lower overestimation errors. The mean average score of 100 episodes obtained after training for 10 million frames shows that the hindsight factor outperforms deep Q-networks, double deep Q-networks and dueling networks for a variety of ATARI games.
Dataset2Vec: Learning Dataset Meta-Features
May 27, 2019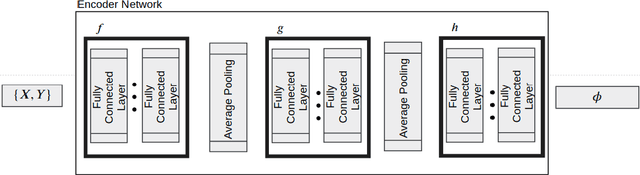

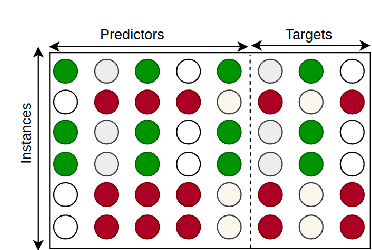

Machine learning tasks such as optimizing the hyper-parameters of a model for a new dataset or few-shot learning can be vastly accelerated if they are not done from scratch for every new dataset, but carry over findings from previous runs. Meta-learning makes use of features of a whole dataset such as its number of instances, its number of predictors, the means of the predictors etc., so called meta-features, dataset summary statistics or simply dataset characteristics, which so far have been hand-crafted, often specifically for the task at hand. More recently, unsupervised dataset encoding models based on variational auto-encoders have been successful in learning such characteristics for the special case when all datasets follow the same schema, but not beyond. In this paper we design a novel model, Dataset2Vec, that is able to characterize datasets with a latent feature vector based on batches and thus is able to generalize beyond datasets having the same schema to arbitrary (tabular) datasets. To do so, we employ auxiliary learning tasks on batches of datasets, esp. to distinguish batches from different datasets. We show empirically that the meta-features collected from batches of similar datasets are concentrated within a small area in the latent space, hence preserving similarity. We also show that using the dataset characteristics learned by Dataset2Vec in a state-of-the-art hyper-parameter optimization model outperforms the hand-crafted meta-features that have been used in the hyper-parameter optimization literature so far. As a result, we advance the current state-of-the-art results for hyper-parameter optimization.