 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset2Vec: Learning Dataset Meta-Features
Paper and Code
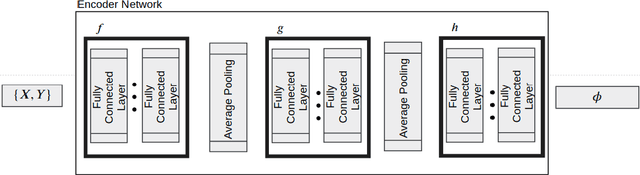

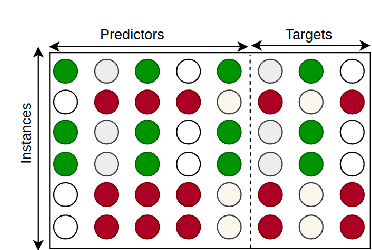

Machine learning tasks such as optimizing the hyper-parameters of a model for a new dataset or few-shot learning can be vastly accelerated if they are not done from scratch for every new dataset, but carry over findings from previous runs. Meta-learning makes use of features of a whole dataset such as its number of instances, its number of predictors, the means of the predictors etc., so called meta-features, dataset summary statistics or simply dataset characteristics, which so far have been hand-crafted, often specifically for the task at hand. More recently, unsupervised dataset encoding models based on variational auto-encoders have been successful in learning such characteristics for the special case when all datasets follow the same schema, but not beyond. In this paper we design a novel model, Dataset2Vec, that is able to characterize datasets with a latent feature vector based on batches and thus is able to generalize beyond datasets having the same schema to arbitrary (tabular) datasets. To do so, we employ auxiliary learning tasks on batches of datasets, esp. to distinguish batches from different datasets. We show empirically that the meta-features collected from batches of similar datasets are concentrated within a small area in the latent space, hence preserving similarity. We also show that using the dataset characteristics learned by Dataset2Vec in a state-of-the-art hyper-parameter optimization model outperforms the hand-crafted meta-features that have been used in the hyper-parameter optimization literature so far. As a result, we advance the current state-of-the-art results for hyper-parameter optimization.