 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons learned from the NeurIPS 2021 MetaDL challenge: Backbone fine-tuning without episodic meta-learning dominates for few-shot learning image classification
Jun 15, 2022

Although deep neural networks are capable of achieving performance superior to humans on various tasks, they are notorious for requiring large amounts of data and computing resources, restricting their success to domains where such resources are available. Metalearning methods can address this problem by transferring knowledge from related tasks, thus reducing the amount of data and computing resources needed to learn new tasks. We organize the MetaDL competition series, which provide opportunities for research groups all over the world to create and experimentally assess new meta-(deep)learning solutions for real problems. In this paper, authored collaboratively between the competition organizers and the top-ranked participants, we describe the design of the competition, the datasets, the best experimental results, as well as the top-ranked methods in the NeurIPS 2021 challenge, which attracted 15 active teams who made it to the final phase (by outperforming the baseline), making over 100 code submissions during the feedback phase. The solutions of the top participants have been open-sourced. The lessons learned include that learning good representations is essential for effective transfer learning.
Delivering Document Conversion as a Cloud Service with High Throughput and Responsiveness
Jun 01, 2022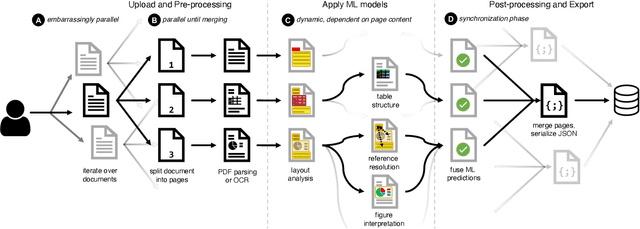
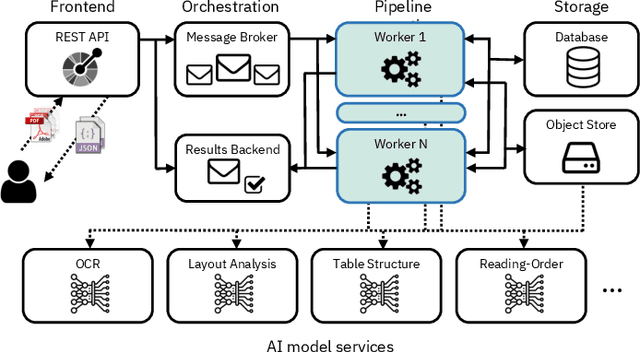
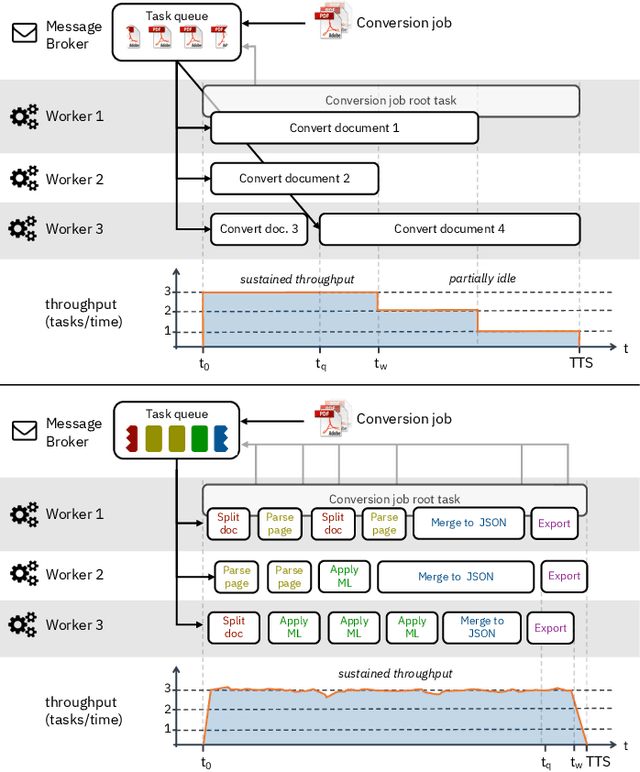
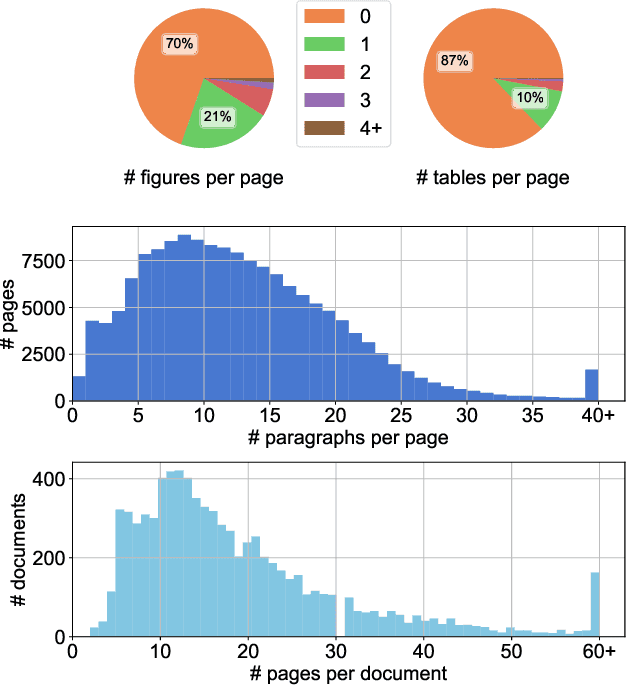
Document understanding is a key business process in the data-driven economy since documents are central to knowledge discovery and business insights. Converting documents into a machine-processable format is a particular challenge here due to their huge variability in formats and complex structure. Accordingly, many algorithms and machine-learning methods emerged to solve particular tasks such as Optical Character Recognition (OCR), layout analysis, table-structure recovery, figure understanding, etc. We observe the adoption of such methods in document understanding solutions offered by all major cloud providers. Yet, publications outlining how such services are designed and optimized to scale in the cloud are scarce. In this paper, we focus on the case of document conversion to illustrate the particular challenges of scaling a complex data processing pipeline with a strong reliance on machine-learning methods on cloud infrastructure. Our key objective is to achieve high scalability and responsiveness for different workload profiles in a well-defined resource budget. We outline the requirements, design, and implementation choices of our document conversion service and reflect on the challenges we faced. Evidence for the scaling behavior and resource efficiency is provided for two alternative workload distribution strategies and deployment configurations. Our best-performing method achieves sustained throughput of over one million PDF pages per hour on 3072 CPU cores across 192 nodes.
Transfer Learning for Algorithm Recommendation
Oct 15, 2019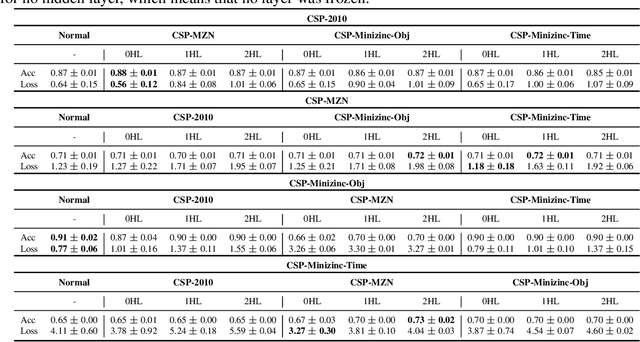
Meta-Learning is a subarea of Machine Learning that aims to take advantage of prior knowledge to learn faster and with fewer data [1]. There are different scenarios where meta-learning can be applied, and one of the most common is algorithm recommendation, where previous experience on applying machine learning algorithms for several datasets can be used to learn which algorithm, from a set of options, would be more suitable for a new dataset [2]. Perhaps the most popular form of meta-learning is transfer learning, which consists of transferring knowledge acquired by a machine learning algorithm in a previous learning task to increase its performance faster in another and similar task [3]. Transfer Learning has been widely applied in a variety of complex tasks such as image classification, machine translation and, speech recognition, achieving remarkable results [4,5,6,7,8]. Although transfer learning is very used in traditional or base-learning, it is still unknown if it is useful in a meta-learning setup. For that purpose, in this paper, we investigate the effects of transferring knowledge in the meta-level instead of base-level. Thus, we train a neural network on meta-datasets related to algorithm recommendation, and then using transfer learning, we reuse the knowledge learned by the neural network in other similar datasets from the same domain, to verify how transferable is the acquired meta-knowledge.