 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubGrapher: Visual Fingerprinting of Chemical Structures
Apr 28, 2025Automatic extraction of chemical structures from scientific literature plays a crucial role in accelerating research across fields ranging from drug discovery to materials science. Patent documents, in particular, contain molecular information in visual form, which is often inaccessible through traditional text-based searches. In this work, we introduce SubGrapher, a method for the visual fingerprinting of chemical structure images. Unlike conventional Optical Chemical Structure Recognition (OCSR) models that attempt to reconstruct full molecular graphs, SubGrapher focuses on extracting molecular fingerprints directly from chemical structure images. Using learning-based instance segmentation, SubGrapher identifies functional groups and carbon backbones, constructing a substructure-based fingerprint that enables chemical structure retrieval. Our approach is evaluated against state-of-the-art OCSR and fingerprinting methods, demonstrating superior retrieval performance and robustness across diverse molecular depictions. The dataset, models, and code will be made publicly available.
SmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion
Mar 14, 2025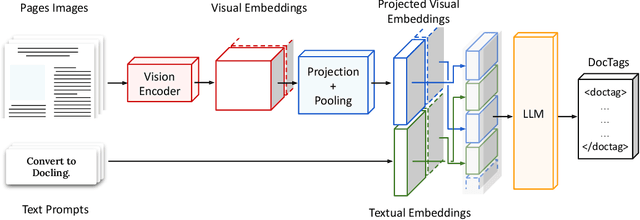
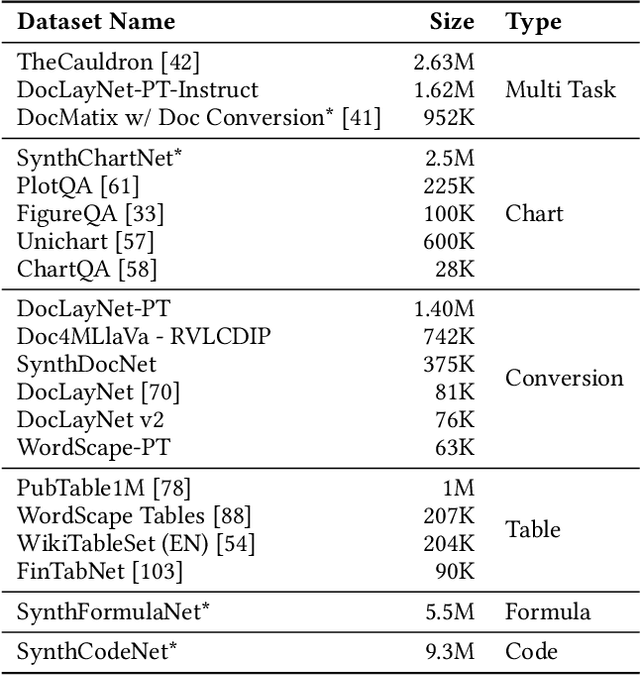
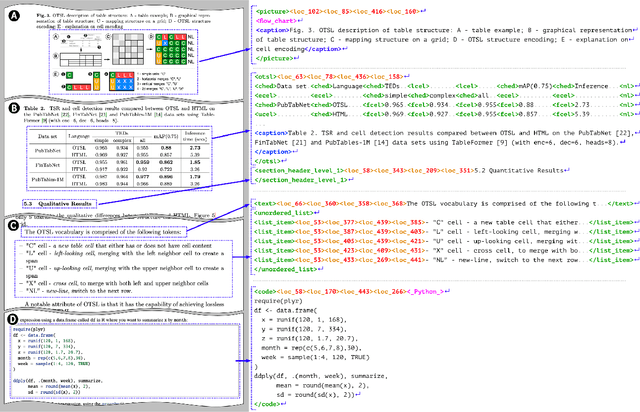
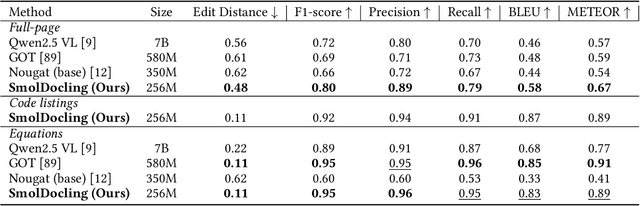
We introduce SmolDocling, an ultra-compact vision-language model targeting end-to-end document conversion. Our model comprehensively processes entire pages by generating DocTags, a new universal markup format that captures all page elements in their full context with location. Unlike existing approaches that rely on large foundational models, or ensemble solutions that rely on handcrafted pipelines of multiple specialized models, SmolDocling offers an end-to-end conversion for accurately capturing content, structure and spatial location of document elements in a 256M parameters vision-language model. SmolDocling exhibits robust performance in correctly reproducing document features such as code listings, tables, equations, charts, lists, and more across a diverse range of document types including business documents, academic papers, technical reports, patents, and forms -- significantly extending beyond the commonly observed focus on scientific papers. Additionally, we contribute novel publicly sourced datasets for charts, tables, equations, and code recognition. Experimental results demonstrate that SmolDocling competes with other Vision Language Models that are up to 27 times larger in size, while reducing computational requirements substantially. The model is currently available, datasets will be publicly available soon.
Docling: An Efficient Open-Source Toolkit for AI-driven Document Conversion
Jan 27, 2025



We introduce Docling, an easy-to-use, self-contained, MIT-licensed, open-source toolkit for document conversion, that can parse several types of popular document formats into a unified, richly structured representation. It is powered by state-of-the-art specialized AI models for layout analysis (DocLayNet) and table structure recognition (TableFormer), and runs efficiently on commodity hardware in a small resource budget. Docling is released as a Python package and can be used as a Python API or as a CLI tool. Docling's modular architecture and efficient document representation make it easy to implement extensions, new features, models, and customizations. Docling has been already integrated in other popular open-source frameworks (e.g., LangChain, LlamaIndex, spaCy), making it a natural fit for the processing of documents and the development of high-end applications. The open-source community has fully engaged in using, promoting, and developing for Docling, which gathered 10k stars on GitHub in less than a month and was reported as the No. 1 trending repository in GitHub worldwide in November 2024.
Docling Technical Report
Aug 19, 2024



This technical report introduces Docling, an easy to use, self-contained, MIT-licensed open-source package for PDF document conversion. It is powered by state-of-the-art specialized AI models for layout analysis (DocLayNet) and table structure recognition (TableFormer), and runs efficiently on commodity hardware in a small resource budget. The code interface allows for easy extensibility and addition of new features and models.
Delivering Document Conversion as a Cloud Service with High Throughput and Responsiveness
Jun 01, 2022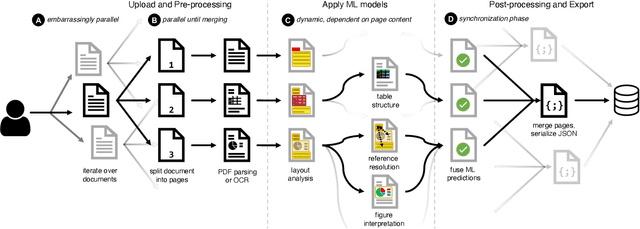
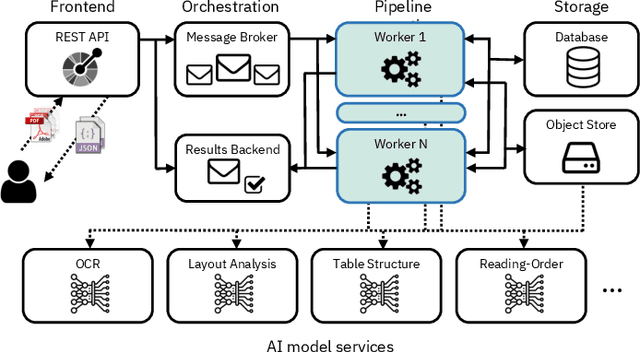
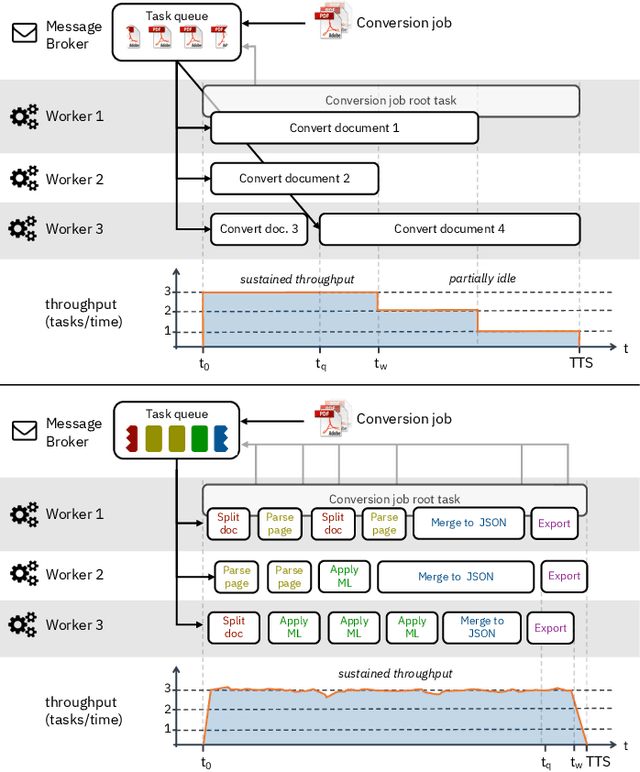
Document understanding is a key business process in the data-driven economy since documents are central to knowledge discovery and business insights. Converting documents into a machine-processable format is a particular challenge here due to their huge variability in formats and complex structure. Accordingly, many algorithms and machine-learning methods emerged to solve particular tasks such as Optical Character Recognition (OCR), layout analysis, table-structure recovery, figure understanding, etc. We observe the adoption of such methods in document understanding solutions offered by all major cloud providers. Yet, publications outlining how such services are designed and optimized to scale in the cloud are scarce. In this paper, we focus on the case of document conversion to illustrate the particular challenges of scaling a complex data processing pipeline with a strong reliance on machine-learning methods on cloud infrastructure. Our key objective is to achieve high scalability and responsiveness for different workload profiles in a well-defined resource budget. We outline the requirements, design, and implementation choices of our document conversion service and reflect on the challenges we faced. Evidence for the scaling behavior and resource efficiency is provided for two alternative workload distribution strategies and deployment configurations. Our best-performing method achieves sustained throughput of over one million PDF pages per hour on 3072 CPU cores across 192 nodes.