 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion
Mar 14, 2025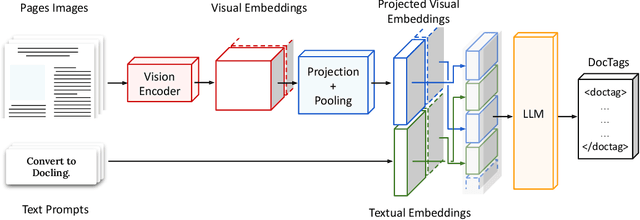
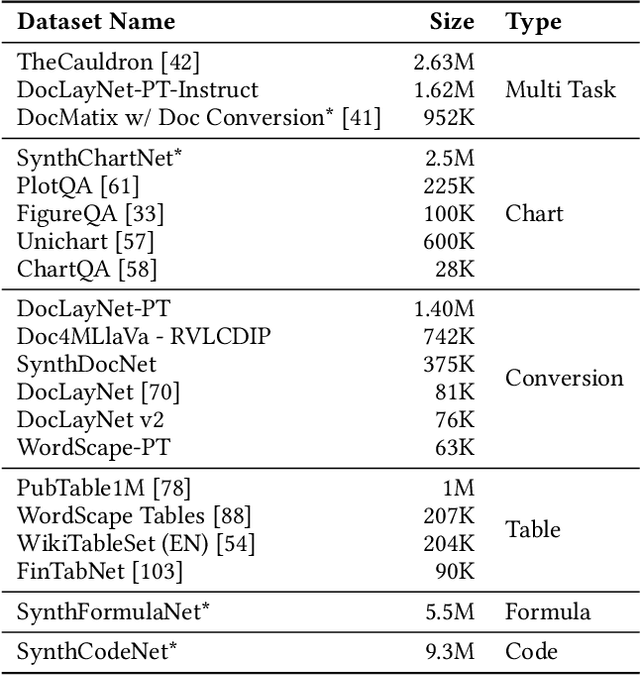
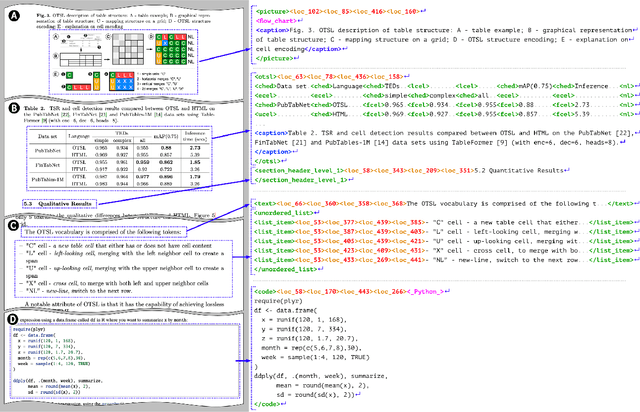
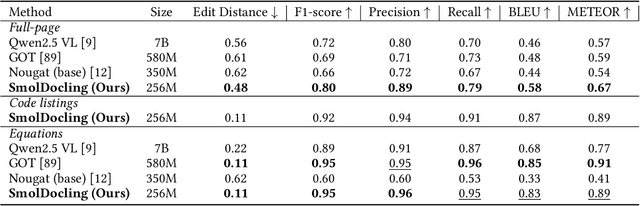
We introduce SmolDocling, an ultra-compact vision-language model targeting end-to-end document conversion. Our model comprehensively processes entire pages by generating DocTags, a new universal markup format that captures all page elements in their full context with location. Unlike existing approaches that rely on large foundational models, or ensemble solutions that rely on handcrafted pipelines of multiple specialized models, SmolDocling offers an end-to-end conversion for accurately capturing content, structure and spatial location of document elements in a 256M parameters vision-language model. SmolDocling exhibits robust performance in correctly reproducing document features such as code listings, tables, equations, charts, lists, and more across a diverse range of document types including business documents, academic papers, technical reports, patents, and forms -- significantly extending beyond the commonly observed focus on scientific papers. Additionally, we contribute novel publicly sourced datasets for charts, tables, equations, and code recognition. Experimental results demonstrate that SmolDocling competes with other Vision Language Models that are up to 27 times larger in size, while reducing computational requirements substantially. The model is currently available, datasets will be publicly available soon.
GACELA -- A generative adversarial context encoder for long audio inpainting
May 11, 2020

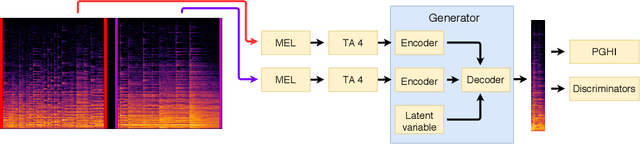

We introduce GACELA, a generative adversarial network (GAN) designed to restore missing musical audio data with a duration ranging between hundreds of milliseconds to a few seconds, i.e., to perform long-gap audio inpainting. While previous work either addressed shorter gaps or relied on exemplars by copying available information from other signal parts, GACELA addresses the inpainting of long gaps in two aspects. First, it considers various time scales of audio information by relying on five parallel discriminators with increasing resolution of receptive fields. Second, it is conditioned not only on the available information surrounding the gap, i.e., the context, but also on the latent variable of the conditional GAN. This addresses the inherent multi-modality of audio inpainting at such long gaps and provides the option of user-defined inpainting. GACELA was tested in listening tests on music signals of varying complexity and gap durations ranging from 375~ms to 1500~ms. While our subjects were often able to detect the inpaintings, the severity of the artifacts decreased from unacceptable to mildly disturbing. GACELA represents a framework capable to integrate future improvements such as processing of more auditory-related features or more explicit musical features.