 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort-term cognitive fatigue of spatial selective attention after face-to-face conversations in virtual noisy environments
Sep 11, 2025Spatial selective attention is an important asset for communication in cocktail party situations but may be compromised by short-term cognitive fatigue. Here we tested whether an effortful conversation in a highly ecological setting depletes task performance in an auditory spatial selective attention task. Young participants with normal hearing performed the task before and after (1) having a real dyadic face-to-face conversation on a free topic in a virtual reverberant room with simulated interfering conversations and background babble noise at 72 dB SPL for 30 minutes, (2) passively listening to the interfering conversations and babble noise, or (3) having the conversation in quiet. Self-reported perceived effort and fatigue increased after conversations in noise and passive listening relative to the reports after conversations in quiet. In contrast to our expectations, response times in the attention task decreased, rather than increased, after conversation in noise and accuracy did not change systematically in any of the conditions on the group level. Unexpectedly, we observed strong training effects between the individual sessions in our within-subject design even after one hour of training on a different day.
A comparative study of eight human auditory models of monaural processing
Jul 05, 2021
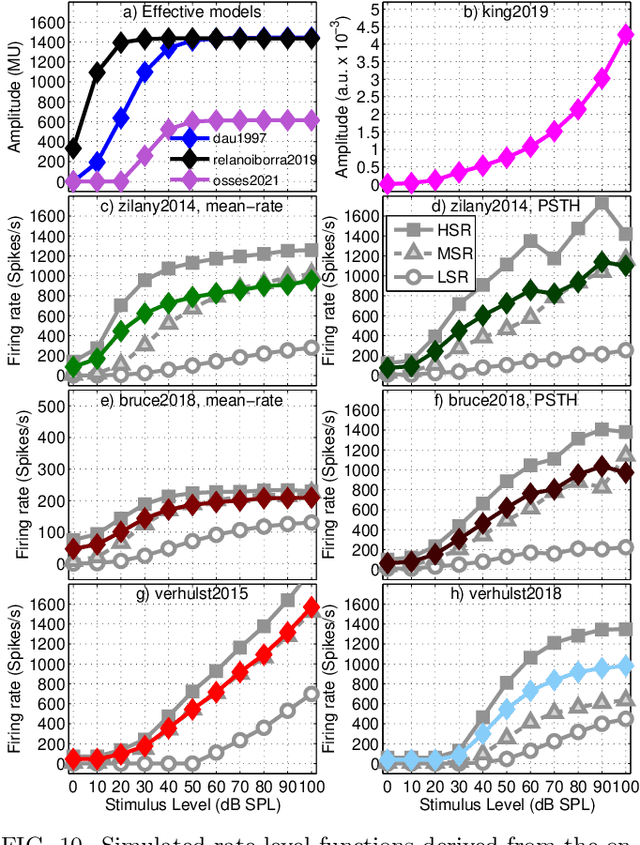


A number of auditory models have been developed using diverging approaches, either physiological or perceptual, but they share comparable stages of signal processing, as they are inspired by the same constitutive parts of the auditory system. We compare eight monaural models that are openly accessible in the Auditory Modelling Toolbox. We discuss the considerations required to make the model outputs comparable to each other, as well as the results for the following model processing stages or their equivalents: outer and middle ear, cochlear filter bank, inner hair cell, auditory nerve synapse, cochlear nucleus, and inferior colliculus. The discussion includes some practical considerations related to the use of monaural stages in binaural frameworks.
Time-Frequency Phase Retrieval for Audio -- The Effect of Transform Parameters
Jun 09, 2021
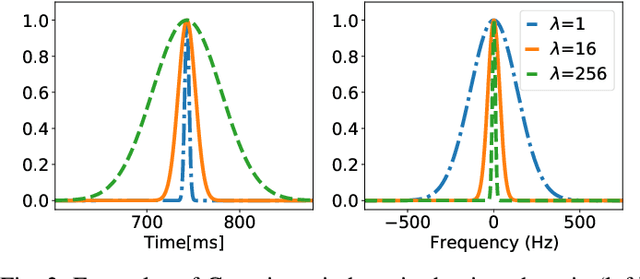
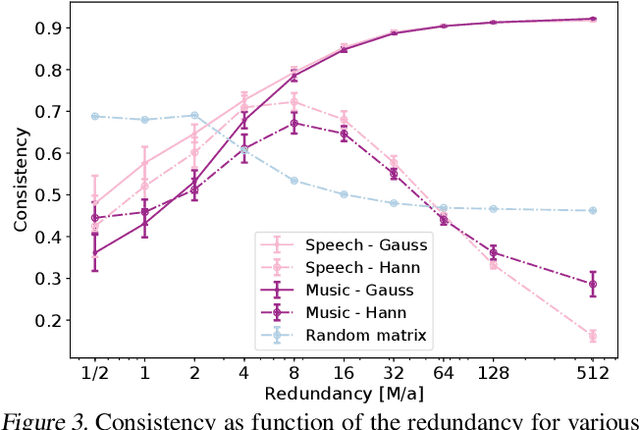
In audio processing applications, phase retrieval (PR) is often performed from the magnitude of short-time Fourier transform (STFT) coefficients. Although PR performance has been observed to depend on the considered STFT parameters and audio data, the extent of this dependence has not been systematically evaluated yet. To address this, we studied the performance of three PR algorithms for various types of audio content and various STFT parameters such as redundancy, time-frequency ratio, and the type of window. The quality of PR was studied in terms of objective difference grade and signal-to-noise ratio of the STFT magnitude, to provide auditory- and signal-based quality assessments. Our results show that PR quality improved with increasing redundancy, with a strong relevance of the time-frequency ratio. The effect of the audio content was smaller but still observable. The effect of the window was only significant for one of the PR algorithms. Interestingly, for a good PR quality, each of the three algorithms required a different set of parameters, demonstrating the relevance of individual parameter sets for a fair comparison across PR algorithms. Based on these results, we developed guidelines for optimizing STFT parameters for a given application.
GACELA -- A generative adversarial context encoder for long audio inpainting
May 11, 2020

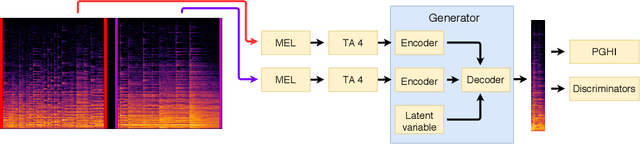

We introduce GACELA, a generative adversarial network (GAN) designed to restore missing musical audio data with a duration ranging between hundreds of milliseconds to a few seconds, i.e., to perform long-gap audio inpainting. While previous work either addressed shorter gaps or relied on exemplars by copying available information from other signal parts, GACELA addresses the inpainting of long gaps in two aspects. First, it considers various time scales of audio information by relying on five parallel discriminators with increasing resolution of receptive fields. Second, it is conditioned not only on the available information surrounding the gap, i.e., the context, but also on the latent variable of the conditional GAN. This addresses the inherent multi-modality of audio inpainting at such long gaps and provides the option of user-defined inpainting. GACELA was tested in listening tests on music signals of varying complexity and gap durations ranging from 375~ms to 1500~ms. While our subjects were often able to detect the inpaintings, the severity of the artifacts decreased from unacceptable to mildly disturbing. GACELA represents a framework capable to integrate future improvements such as processing of more auditory-related features or more explicit musical features.
Adversarial Generation of Time-Frequency Features with application in audio synthesis
Feb 11, 2019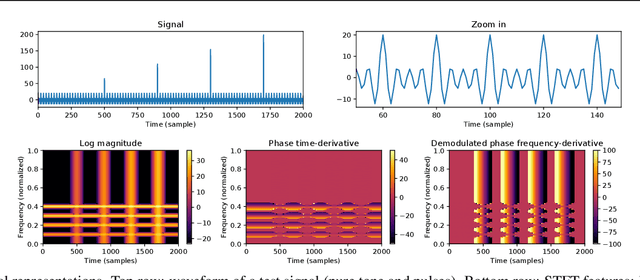

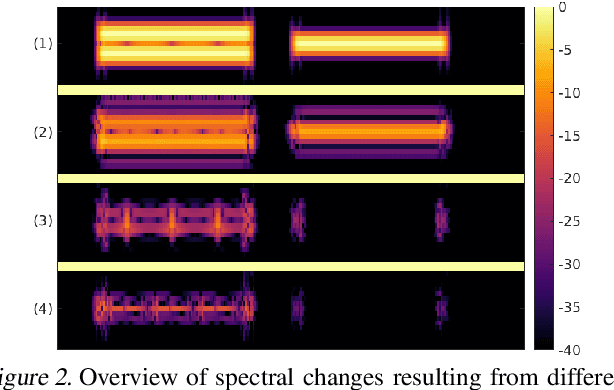
Time-frequency (TF) representations provide powerful and intuitive features for the analysis of time series such as audio. But still, generative modeling of audio in the TF domain is a subtle matter. Consequently, neural audio synthesis widely relies on directly modeling the waveform and previous attempts at unconditionally synthesizing audio from neurally generated TF features still struggle to produce audio at satisfying quality. In this contribution, focusing on the short-time Fourier transform, we discuss the challenges that arise in audio synthesis based on generated TF features and how to overcome them. We demonstrate the potential of deliberate generative TF modeling by training a generative adversarial network (GAN) on short-time Fourier features. We show that our TF-based network was able to outperform the state-of-the-art GAN generating waveform, despite the similar architecture in the two networks.
A context encoder for audio inpainting
Oct 29, 2018
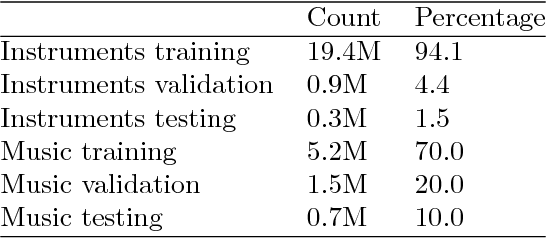
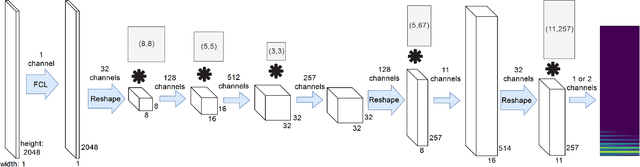
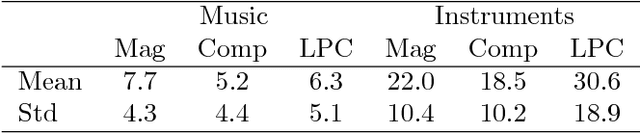
We studied the ability of deep neural networks (DNNs) to restore missing audio content based on its context, a process usually referred to as audio inpainting. We focused on gaps in the range of tens of milliseconds, a condition which has not received much attention yet. The proposed DNN structure was trained on audio signals containing music and musical instruments, separately, with 64-ms long gaps. The input to the DNN was the context, i.e., the signal surrounding the gap, transformed into time-frequency (TF) coefficients. Two networks were analyzed, a DNN with complex-valued TF coefficient output and another one producing magnitude TF coefficient output, both based on the same network architecture. We found significant differences in the inpainting results between the two DNNs. In particular, we discuss the observation that the complex-valued DNN fails to produce reliable results outside the low frequency range. Further, our results were compared to those obtained from a reference method based on linear predictive coding (LPC). For instruments, our DNNs were not able to match the performance of reference method, although the magnitude network provided good results as well. For music, however, our magnitude DNN significantly outperformed the reference method, demonstrating a generally good usability of the proposed DNN structure for inpainting complex audio signals like music. This paves the road towards future, more sophisticated audio inpainting approaches based on DNNs.
Inpainting of long audio segments with similarity graphs
Feb 23, 2018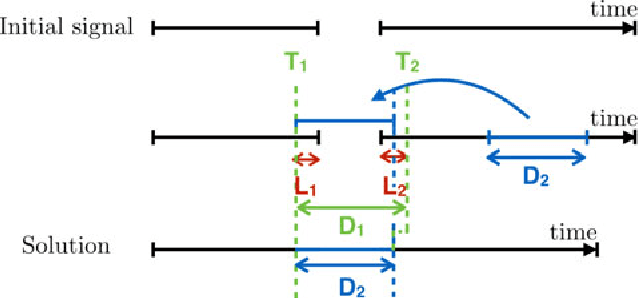
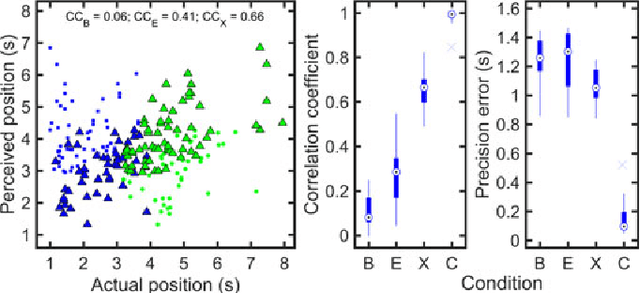
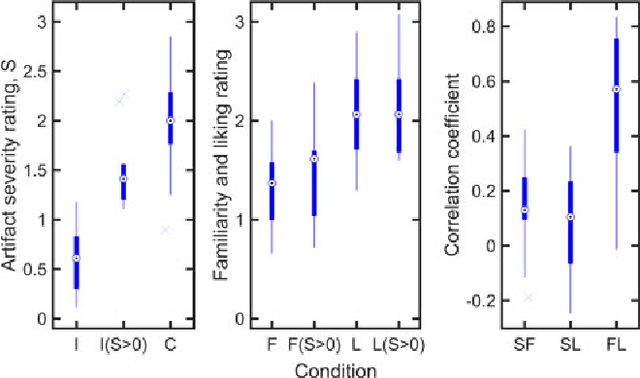
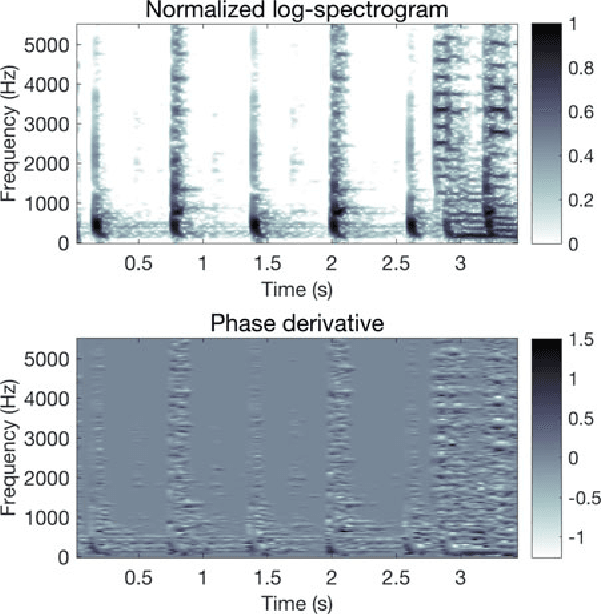
We present a novel method for the compensation of long duration data loss in audio signals, in particular music. The concealment of such signal defects is based on a graph that encodes signal structure in terms of time-persistent spectral similarity. A suitable candidate segment for the substitution of the lost content is proposed by an intuitive optimization scheme and smoothly inserted into the gap, i.e. the lost or distorted signal region. Extensive listening tests show that the proposed algorithm provides highly promising results when applied to a variety of real-world music signals.