 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort-wave admittance correction for a time-domain cochlear transmission line model
Feb 02, 2026Transmission line (TL) models implemented in the time domain can efficiently simulate basilar-membrane (BM) displacement in response to transient or non-stationary sounds. By design, a TL model is well-suited for an one-dimensional (1-D) characterization of the traveling wave, but the real configuration of the cochlea also introduces higher-dimensional effects. Such effects include the focusing of the pressure around the BM and transverse viscous damping, both of which are magnified in the short-wave region. The two effects depend on the wavelength and are more readily expressed in the frequency domain. In this paper, we introduce a numerical correction for the BM admittance to account for 2-D effects in the time domain using autoregressive filtering and regression techniques. The correction was required for the implementation of a TL model tailored to the gerbil cochlear physiology. The model, which includes instantaneous nonlinearities in the form of variable damping, initially presented insufficient compression with increasing sound levels. This limitation was explained by the strong coupling between gain and frequency selectivity assumed in the 1-D nonlinear TL model, whereas cochlear frequency selectivity shows only a moderate dependence on sound level in small mammals. The correction factor was implemented in the gerbil model and made level-dependent using a feedback loop. The updated model achieved some decoupling between frequency selectivity and gain, providing 5 dB of additional gain and extending the range of sound levels of the compressive regime by 10 dB. We discuss the relevance of this work through two key features: the integration of both analytical and regression methods for characterizing BM admittance, and the combination of instantaneous and non-instantaneous nonlinearities.
Artifact-free Sound Quality in DNN-based Closed-loop Systems for Audio Processing
Jan 07, 2025

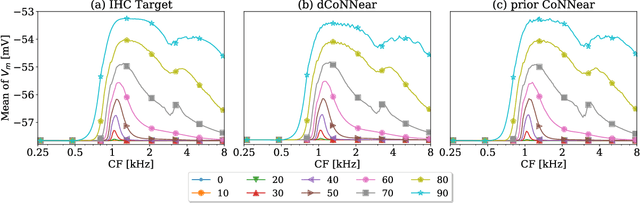
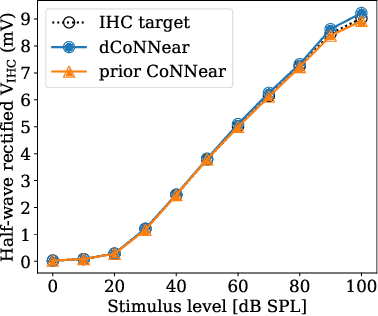
Recent advances in deep neural networks (DNNs) have significantly improved various audio processing applications, including speech enhancement, synthesis, and hearing aid algorithms. DNN-based closed-loop systems have gained popularity in these applications due to their robust performance and ability to adapt to diverse conditions. Despite their effectiveness, current DNN-based closed-loop systems often suffer from sound quality degradation caused by artifacts introduced by suboptimal sampling methods. To address this challenge, we introduce dCoNNear, a novel DNN architecture designed for seamless integration into closed-loop frameworks. This architecture specifically aims to prevent the generation of spurious artifacts. We demonstrate the effectiveness of dCoNNear through a proof-of-principle example within a closed-loop framework that employs biophysically realistic models of auditory processing for both normal and hearing-impaired profiles to design personalized hearing aid algorithms. Our results show that dCoNNear not only accurately simulates all processing stages of existing non-DNN biophysical models but also eliminates audible artifacts, thereby enhancing the sound quality of the resulting hearing aid algorithms. This study presents a novel, artifact-free closed-loop framework that improves the sound quality of audio processing systems, offering a promising solution for high-fidelity applications in audio and hearing technologies.
A Neural-Network Framework for the Design of Individualised Hearing-Loss Compensation
Jul 14, 2022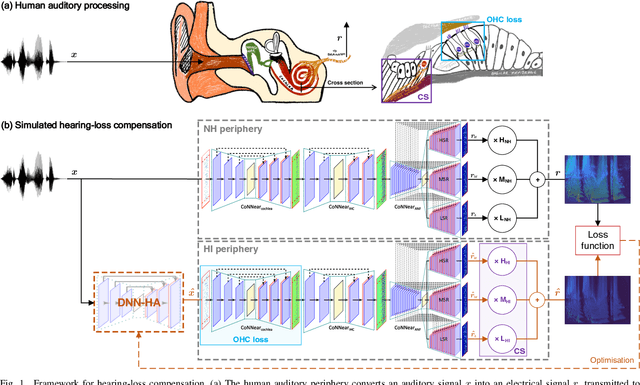
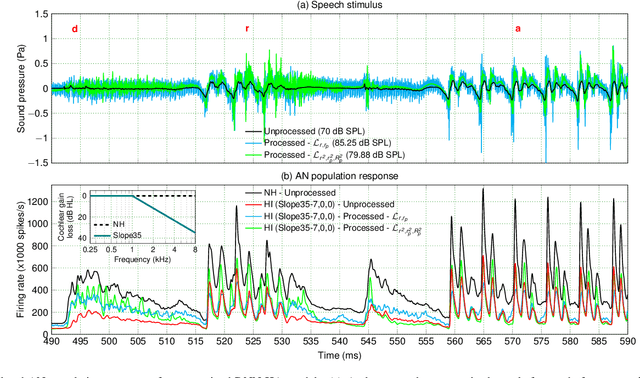
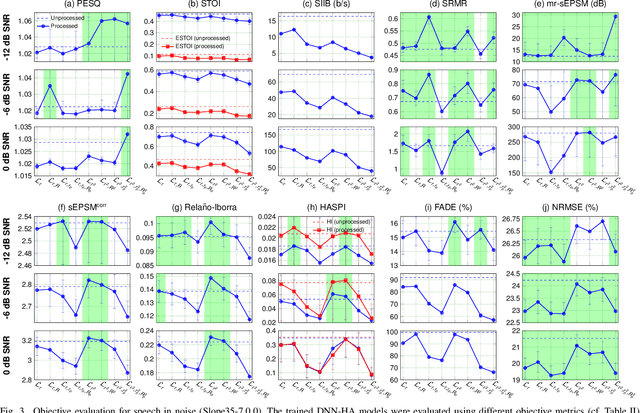
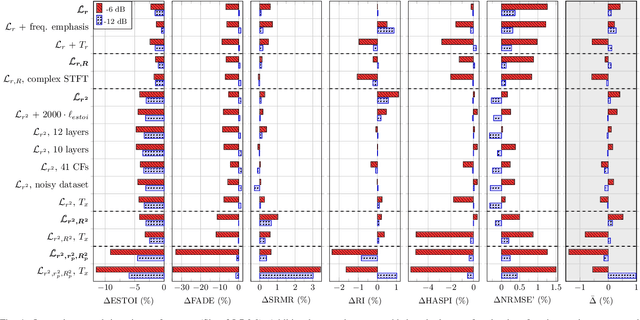
Even though sound processing in the human auditory system is complex and highly non-linear, hearing aids (HAs) still rely on simplified descriptions of auditory processing or hearing loss to restore hearing. Standard HA amplification strategies succeed in restoring inaudibility of faint sounds, but fall short of providing targetted treatments for complex sensorineural deficits. To address this challenge, biophysically realistic models of human auditory processing can be adopted in the design of individualised HA strategies, but these are typically non-differentiable and computationally expensive. Therefore, this study proposes a differentiable DNN framework that can be used to train DNN-based HA models based on biophysical auditory-processing differences between normal-hearing and hearing-impaired models. We investigate the restoration capabilities of our DNN-based hearing-loss compensation for different loss functions, to optimally compensate for a mixed outer-hair-cell (OHC) loss and cochlear-synaptopathy (CS) impairment. After evaluating which trained DNN-HA model yields the best restoration outcomes on simulated auditory responses and speech intelligibility, we applied the same training procedure to two milder hearing-loss profiles with OHC loss or CS alone. Our results show that auditory-processing restoration was possible for all considered hearing-loss cases, with OHC loss proving easier to compensate than CS. Several objective metrics were considered to estimate the expected perceptual benefit after processing, and these simulations hold promise in yielding improved understanding of speech-in-noise for hearing-impaired listeners who use our DNN-HA processing. Since our framework can be tuned to the hearing-loss profiles of individual listeners, we enter an era where truly individualised and DNN-based hearing-restoration strategies can be developed and be tested experimentally.
A comparative study of eight human auditory models of monaural processing
Jul 05, 2021
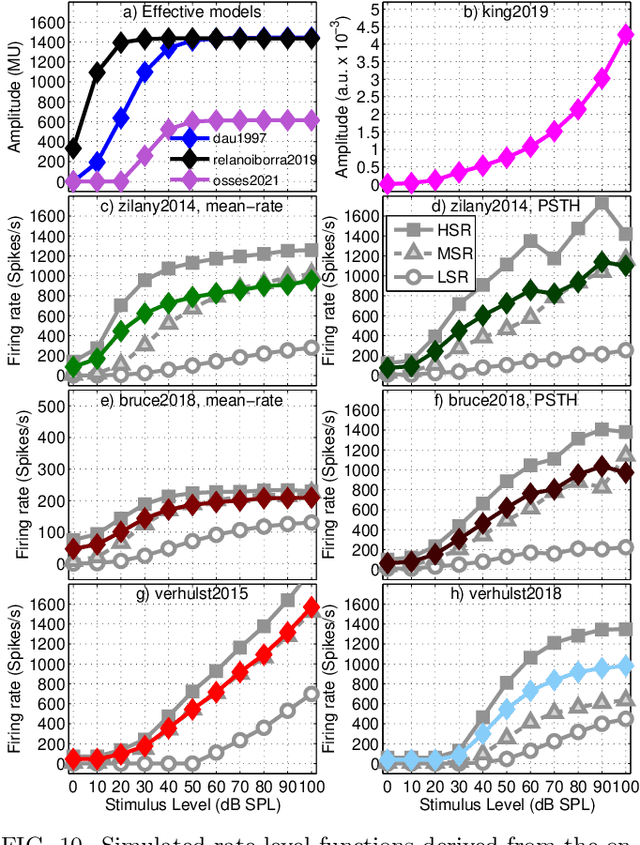


A number of auditory models have been developed using diverging approaches, either physiological or perceptual, but they share comparable stages of signal processing, as they are inspired by the same constitutive parts of the auditory system. We compare eight monaural models that are openly accessible in the Auditory Modelling Toolbox. We discuss the considerations required to make the model outputs comparable to each other, as well as the results for the following model processing stages or their equivalents: outer and middle ear, cochlear filter bank, inner hair cell, auditory nerve synapse, cochlear nucleus, and inferior colliculus. The discussion includes some practical considerations related to the use of monaural stages in binaural frameworks.
A convolutional neural-network model of human cochlear mechanics and filter tuning for real-time applications
Apr 30, 2020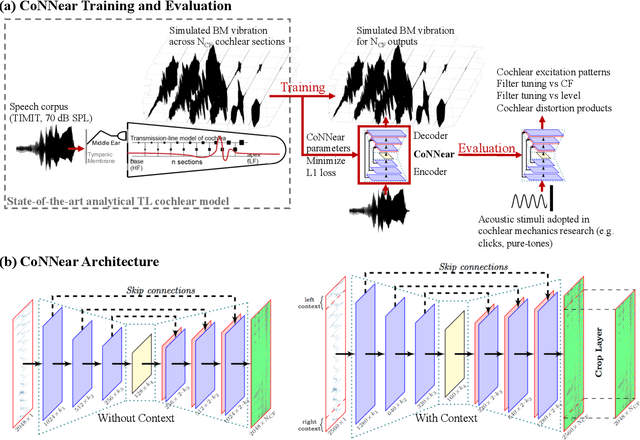
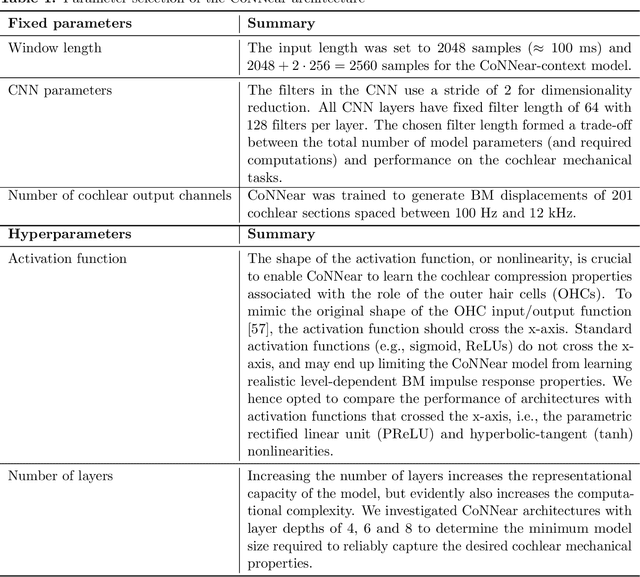
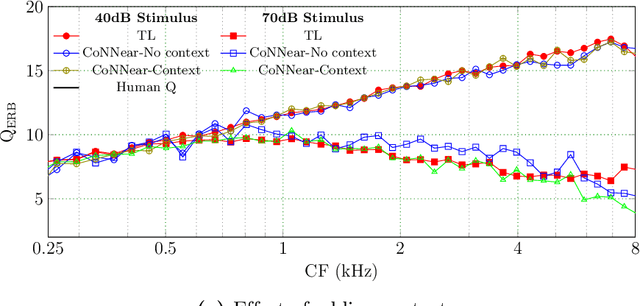

Auditory models are commonly used as feature extractors for automatic speech recognition systems or as front-ends for robotics, machine-hearing and hearing-aid applications. While over the years, auditory models have progressed to capture the biophysical and nonlinear properties of human hearing in great detail, these biophysical models are slow to compute and consequently not used in real-time applications. To enable an uptake, we present a hybrid approach where convolutional neural networks are combined with computational neuroscience to yield a real-time end-to-end model for human cochlear mechanics and level-dependent cochlear filter tuning (CoNNear). The CoNNear model was trained on acoustic speech material, but its performance and applicability evaluated using (unseen) sound stimuli common in cochlear mechanics research. The CoNNear model accurately simulates human frequency selectivity and its dependence on sound intensity, which is essential for our hallmark robust speech intelligibility performance, even at negative speech-to-background noise ratios. Because its architecture is based on real-time, parallel and differentiatable computations, the CoNNear model has the power to leverage real-time auditory applications towards human performance and can inspire the next generation of speech recognition, robotics and hearing-aid systems.
Machines hear better when they have ears
Jun 05, 2018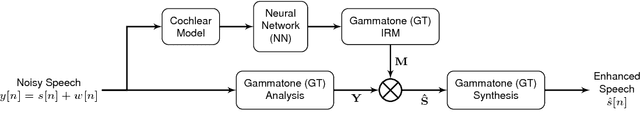
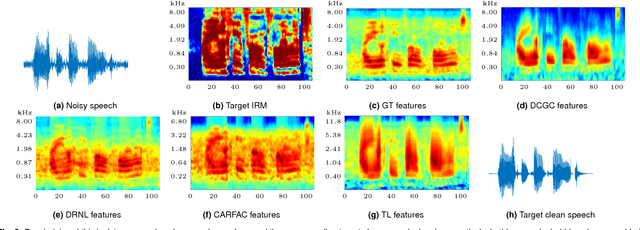
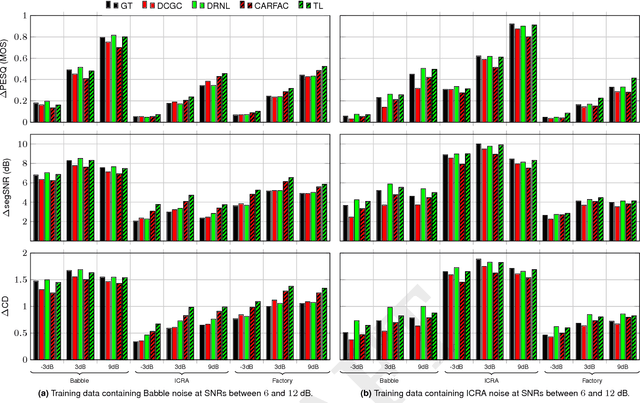
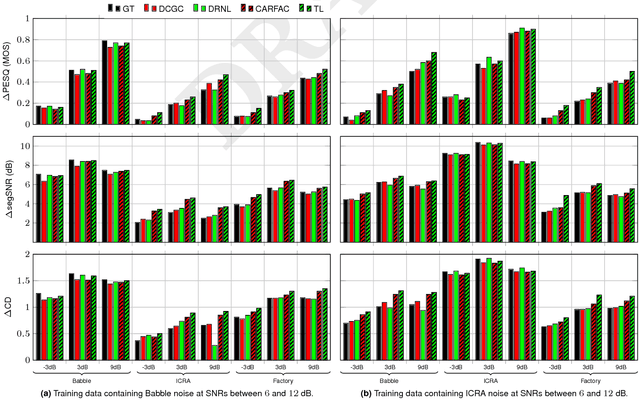
Deep-neural-network (DNN) based noise suppression systems yield significant improvements over conventional approaches such as spectral subtraction and non-negative matrix factorization, but do not generalize well to noise conditions they were not trained for. In comparison to DNNs, humans show remarkable noise suppression capabilities that yield successful speech intelligibility under various adverse listening conditions and negative signal-to-noise ratios (SNRs). Motivated by the excellent human performance, this paper explores whether numerical models that simulate human cochlear signal processing can be combined with DNNs to improve the robustness of DNN based noise suppression systems. Five cochlear models were coupled to fully-connected and recurrent NN-based noise suppression systems and were trained and evaluated for a variety of noise conditions using objective metrics: perceptual speech quality (PESQ), segmental SNR and cepstral distance. The simulations show that biophysically-inspired cochlear models improve the generalizability of DNN-based noise suppression systems for unseen noise and negative SNRs. This approach thus leads to robust noise suppression systems that are less sensitive to the noise type and noise level. Because cochlear models capture the intrinsic nonlinearities and dynamics of peripheral auditory processing, it is shown here that accounting for their deterministic signal processing improves machine hearing and avoids overtraining of multi-layer DNNs. We hence conclude that machines hear better when realistic cochlear models are used at the input of DNNs.